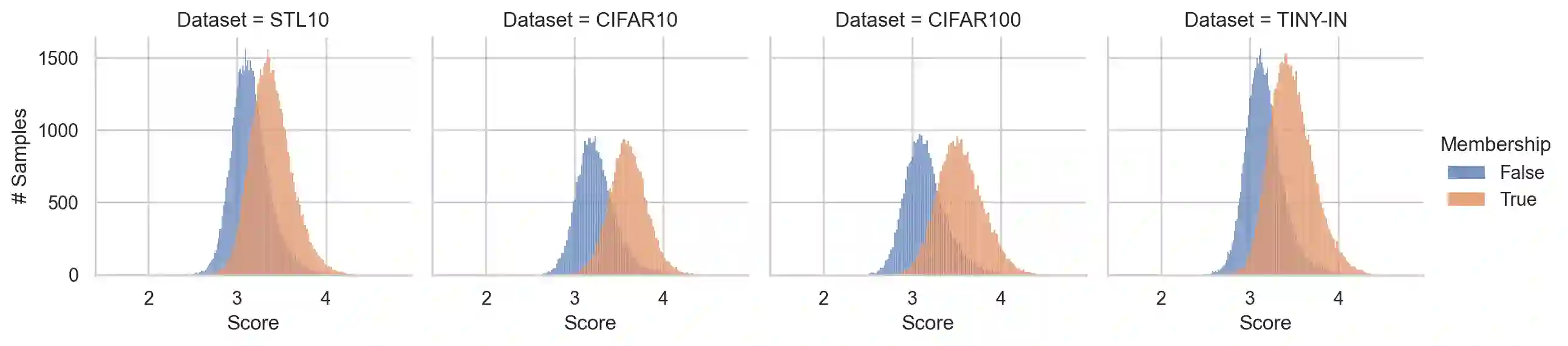
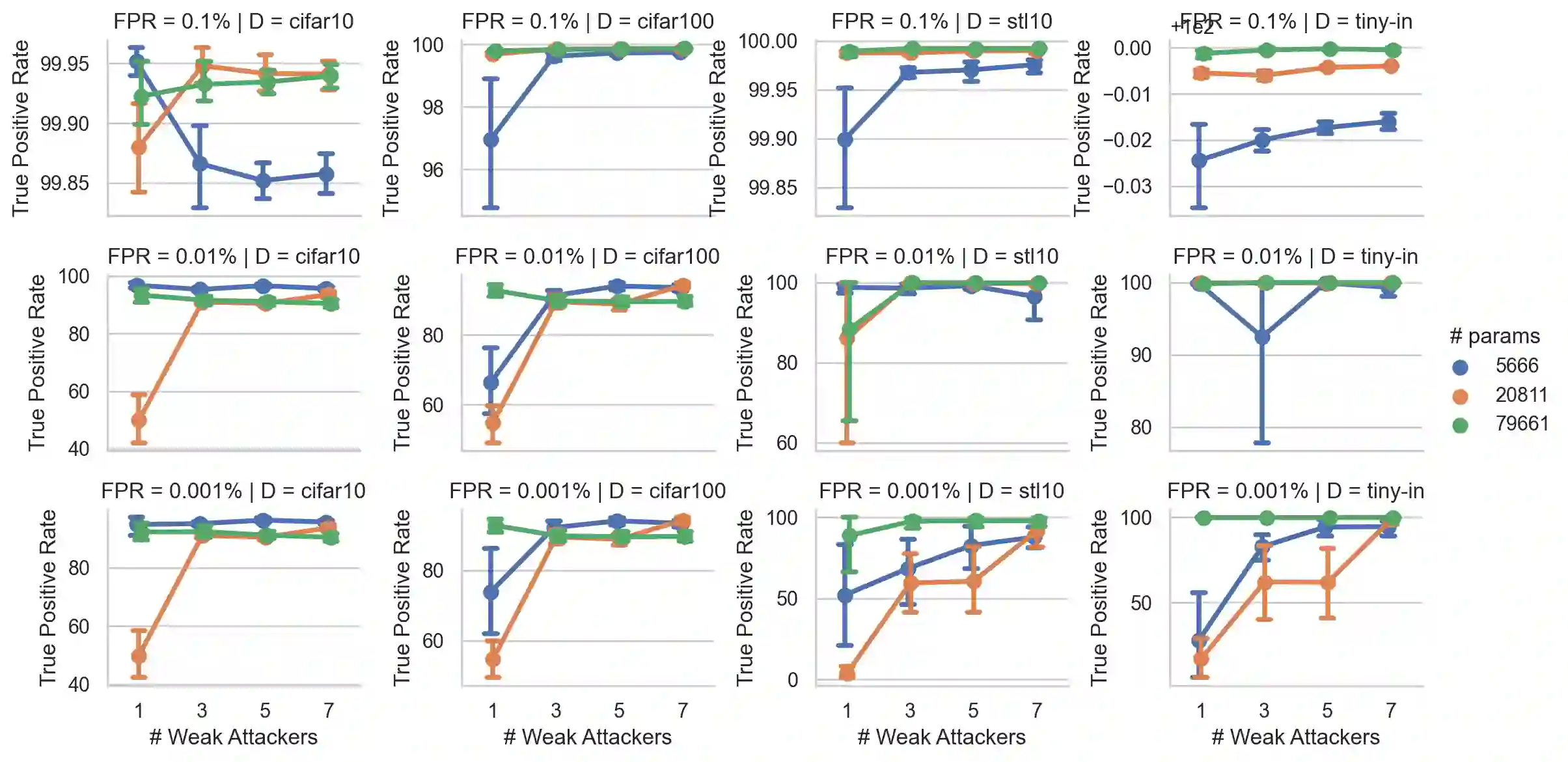
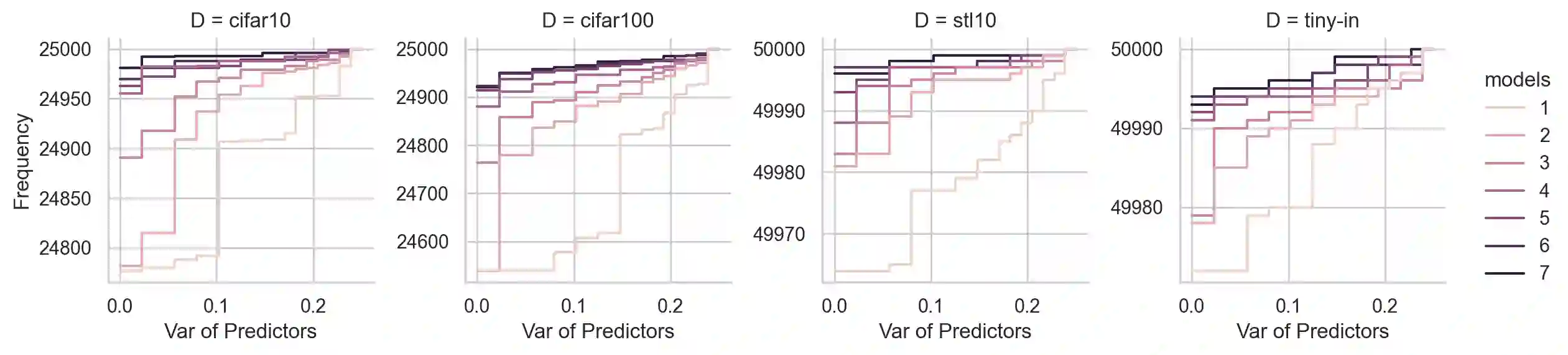
Recently, diffusion models have become popular tools for image synthesis because of their high-quality outputs. However, like other large-scale models, they may leak private information about their training data. Here, we demonstrate a privacy vulnerability of diffusion models through a \emph{membership inference (MI) attack}, which aims to identify whether a target example belongs to the training set when given the trained diffusion model. Our proposed MI attack learns quantile regression models that predict (a quantile of) the distribution of reconstruction loss on examples not used in training. This allows us to define a granular hypothesis test for determining the membership of a point in the training set, based on thresholding the reconstruction loss of that point using a custom threshold tailored to the example. We also provide a simple bootstrap technique that takes a majority membership prediction over ``a bag of weak attackers'' which improves the accuracy over individual quantile regression models. We show that our attack outperforms the prior state-of-the-art attack while being substantially less computationally expensive -- prior attacks required training multiple ``shadow models'' with the same architecture as the model under attack, whereas our attack requires training only much smaller models.
翻译:近期,扩散模型因其高质量的输出而成为图像合成的热门工具。然而,与其他大规模模型类似,它们也可能泄露关于训练数据的隐私信息。本文通过一种*成员推理攻击*展示了扩散模型的隐私漏洞,该攻击旨在判断给定已训练的扩散模型时,某个目标样本是否属于训练集。我们提出的成员推理攻击通过学习分位数回归模型,预测训练中未使用样本的重构损失分布(分位数)。这使得我们能够基于针对样本定制的阈值对重构损失进行门控,从而定义一个精细化的假设检验来判断样本是否属于训练集。我们还提供了一种简单的自助抽样技术,即通过对“一组弱攻击器”进行多数投票来预测成员身份,从而提升了单个分位数回归模型的准确性。实验表明,我们的攻击在性能上优于现有最先进攻击,同时计算成本大幅降低——先前攻击需要训练多个与被攻击模型架构相同的影子模型,而我们的攻击仅需训练规模小得多的模型。