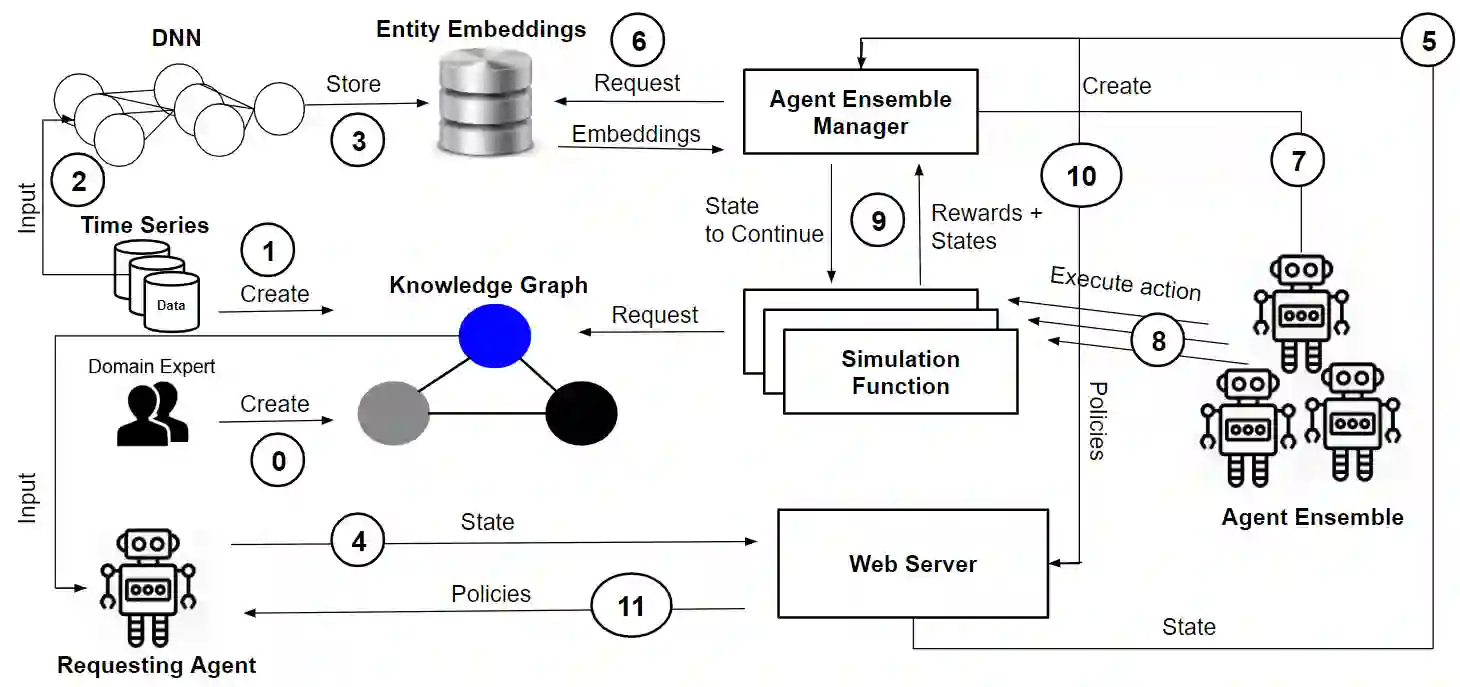
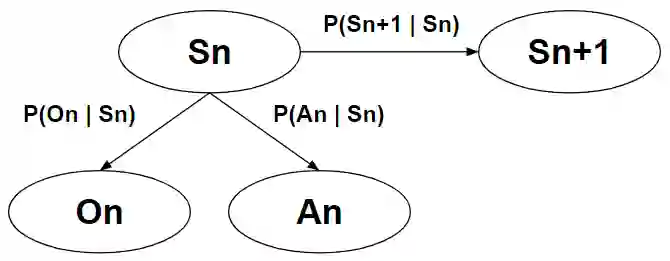
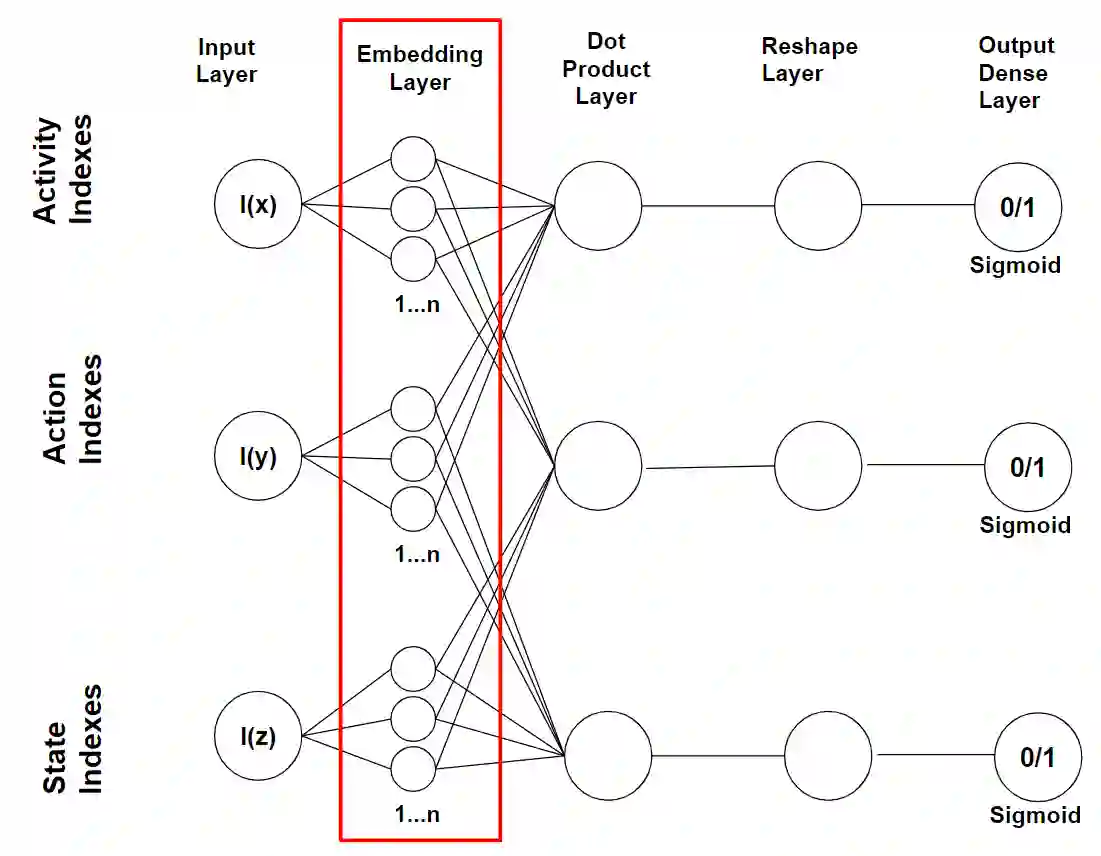
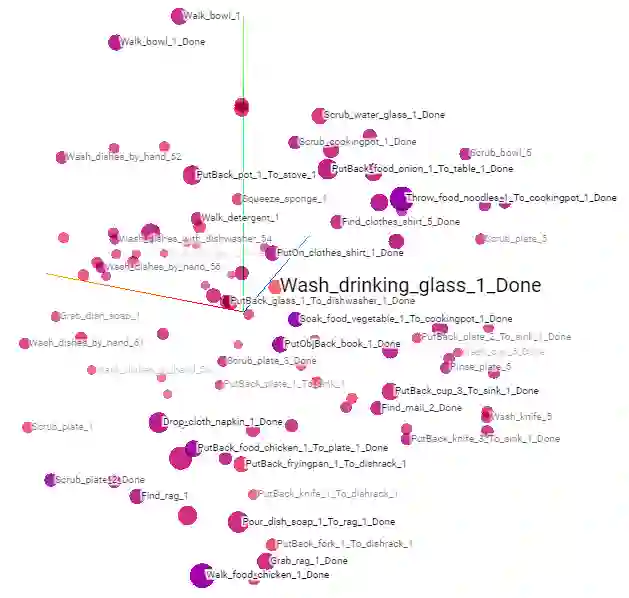
Computational agents support humans in many areas of life and are therefore found in heterogeneous contexts. This means they operate in rapidly changing environments and can be confronted with huge state and action spaces. In order to perform services and carry out activities in a goal-oriented manner, agents require prior knowledge and therefore have to develop and pursue context-dependent policies. However, prescribing policies in advance is limited and inflexible, especially in dynamically changing environments. Moreover, the context of an agent determines its choice of actions. Since the environments can be stochastic and complex in terms of the number of states and feasible actions, activities are usually modelled in a simplified way by Markov decision processes so that, e.g., agents with reinforcement learning are able to learn policies, that help to capture the context and act accordingly to optimally perform activities. However, training policies for all possible contexts using reinforcement learning is time-consuming. A requirement and challenge for agents is to learn strategies quickly and respond immediately in cross-context environments and applications, e.g., the Internet, service robotics, cyber-physical systems. In this work, we propose a novel simulation-based approach that enables a) the representation of heterogeneous contexts through knowledge graphs and entity embeddings and b) the context-aware composition of policies on demand by ensembles of agents running in parallel. The evaluation we conducted with the "Virtual Home" dataset indicates that agents with a need to switch seamlessly between different contexts, can request on-demand composed policies that lead to the successful completion of context-appropriate activities without having to learn these policies in lengthy training steps and episodes, in contrast to agents that use reinforcement learning.
翻译:计算智能体在人类生活的诸多领域提供支持,因此常处于异构环境中。这意味着它们需在快速变化的环境中运行,并可能面临庞大的状态空间与动作空间。为以目标导向的方式执行服务与活动,智能体需具备先验知识,从而制定并遵循依赖上下文的策略。然而,在动态变化的环境中,预先指定策略具有局限性与僵化性。此外,智能体的上下文决定了其动作选择。由于环境可能具有随机性,且状态与可行动作数量复杂,活动通常以马尔可夫决策过程进行简化建模,例如采用强化学习的智能体能学习策略,从而捕获上下文并据此执行最优活动。但使用强化学习为所有可能的上下文训练策略耗时巨大。智能体面临的需求与挑战在于:需在跨上下文环境与应用(如互联网、服务机器人、信息物理系统)中快速学习策略并即时响应。本文提出一种基于仿真的新方法,可实现:a) 通过知识图谱与实体嵌入表示异构上下文,以及b) 通过并行运行的智能体集成按需进行上下文感知的策略组合。我们基于"Virtual Home"数据集开展的评估表明:与使用强化学习的智能体不同,需在不同上下文间无缝切换的智能体可请求按需组合的策略,从而在不经过漫长训练步骤与回合的情况下成功完成上下文适配的活动。