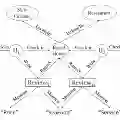
Heterogeneous information network (HIN), which contains rich semantics depicted by meta-paths, has become a powerful tool to alleviate data sparsity in recommender systems. Existing HIN-based recommendations hold the data centralized storage assumption and conduct centralized model training. However, the real-world data is often stored in a distributed manner for privacy concerns, resulting in the failure of centralized HIN-based recommendations. In this paper, we suggest the HIN is partitioned into private HINs stored in the client side and shared HINs in the server. Following this setting, we propose a federated heterogeneous graph neural network (FedHGNN) based framework, which can collaboratively train a recommendation model on distributed HINs without leaking user privacy. Specifically, we first formalize the privacy definition in the light of differential privacy for HIN-based federated recommendation, which aims to protect user-item interactions of private HIN as well as user's high-order patterns from shared HINs. To recover the broken meta-path based semantics caused by distributed data storage and satisfy the proposed privacy, we elaborately design a semantic-preserving user interactions publishing method, which locally perturbs user's high-order patterns as well as related user-item interactions for publishing. After that, we propose a HGNN model for recommendation, which conducts node- and semantic-level aggregations to capture recovered semantics. Extensive experiments on three datasets demonstrate our model outperforms existing methods by a large margin (up to 34% in HR@10 and 42% in NDCG@10) under an acceptable privacy budget.
翻译:异质信息网络(HIN)通过元路径刻画丰富语义,已成为缓解推荐系统数据稀疏性的有效工具。现有基于HIN的推荐方法均假设数据集中存储并进行集中式模型训练。然而,真实场景中数据常因隐私顾虑而分布式存储,导致集中式HIN推荐方案失效。本文提出将HIN划分为客户端私有HIN与服务器共享HIN,并基于此设计联邦异构图神经网络(FedHGNN)框架,可在不泄露用户隐私的前提下,利用分布式HIN协同训练推荐模型。具体而言,我们首先为基于HIN的联邦推荐定义了满足差分隐私的隐私保护规范,旨在保护私有HIN中的用户-物品交互信息及共享HIN中的用户高阶模式。针对分布式存储导致的元路径语义断裂问题,并满足所提出的隐私约束,我们精心设计了语义保持的用户交互发布方法,该方法在本地扰动用户高阶模式及相关用户-物品交互后发布。随后,我们提出面向推荐的HGNN模型,通过节点级与语义级聚合操作恢复被破坏的语义信息。在三个数据集上的大量实验表明,在可接受的隐私预算下,本模型在HR@10和NDCG@10指标上分别以最高34%和42%的幅度显著优于现有方法。