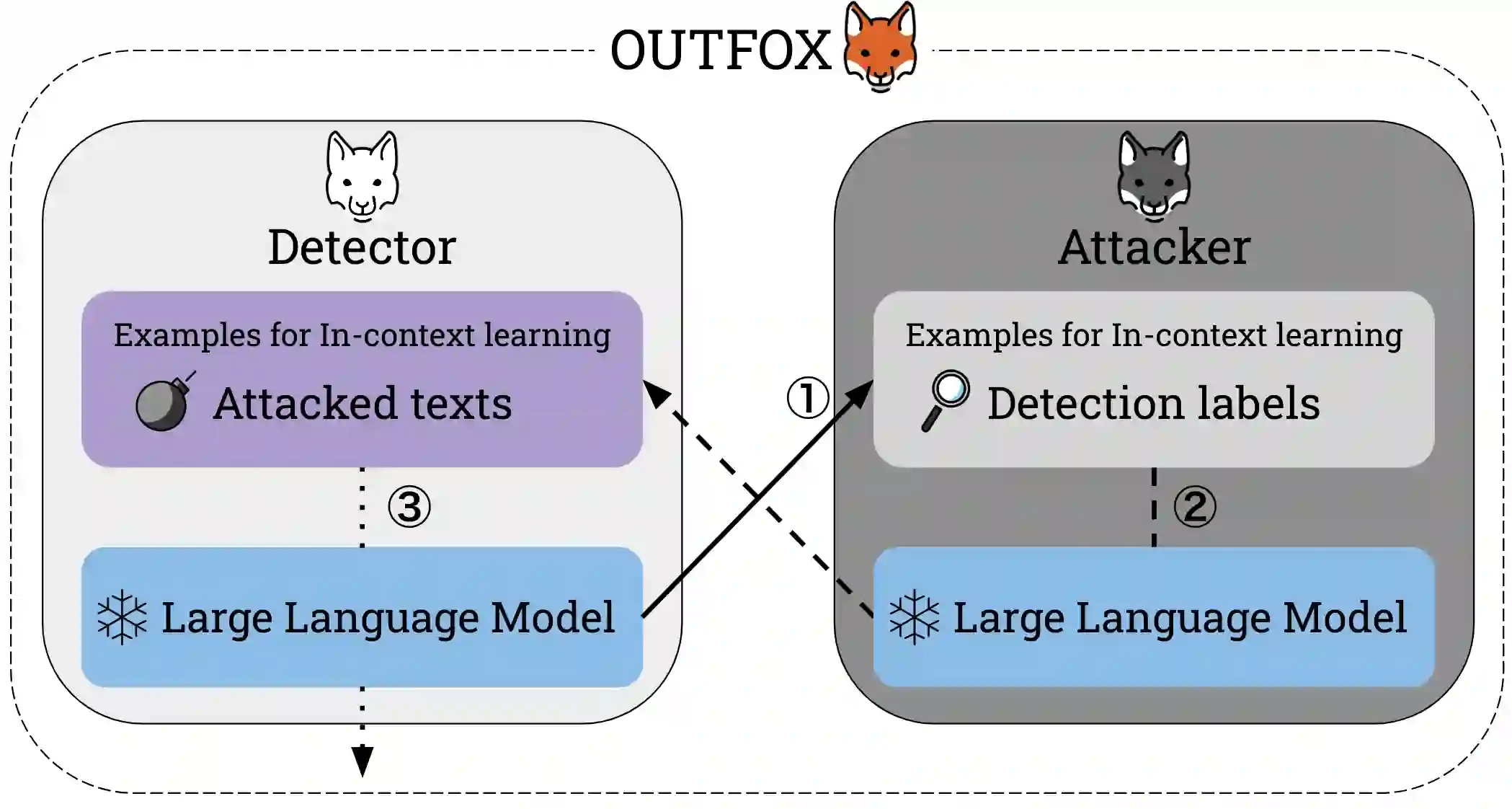
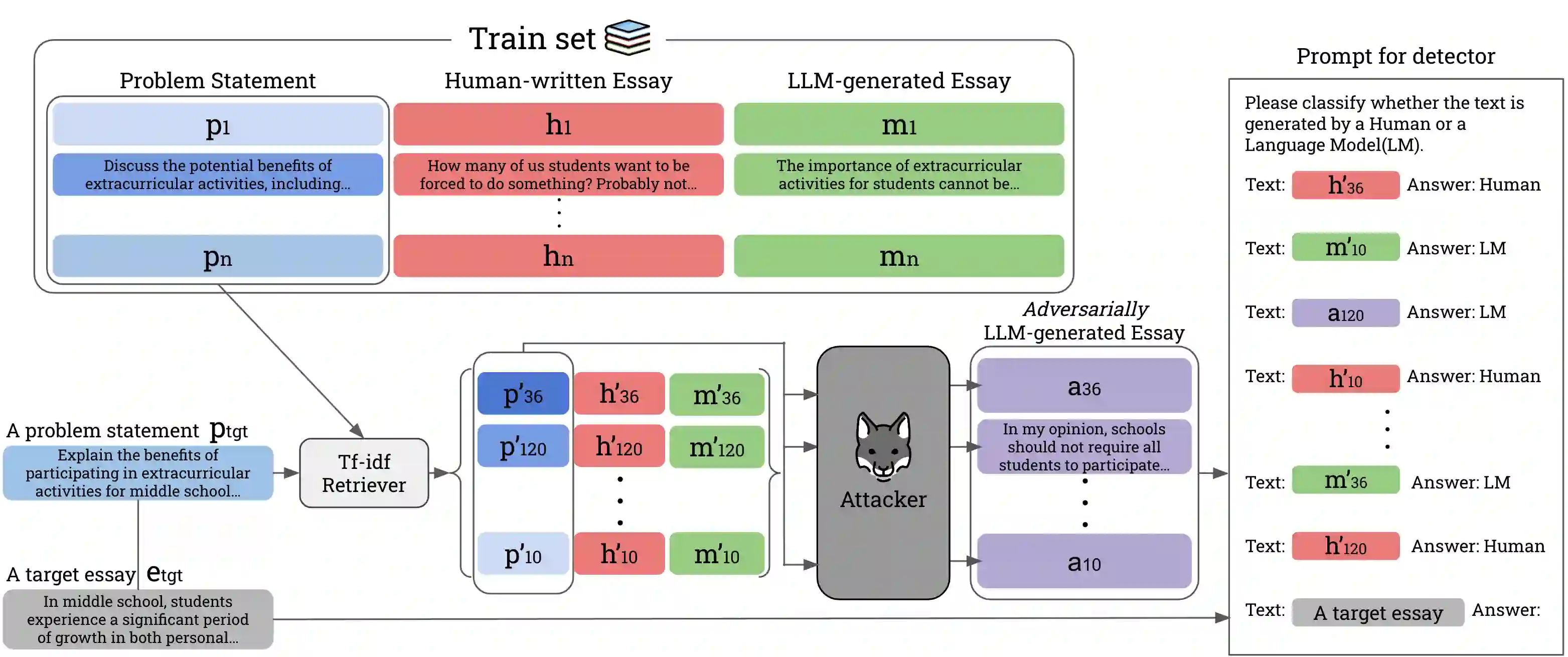
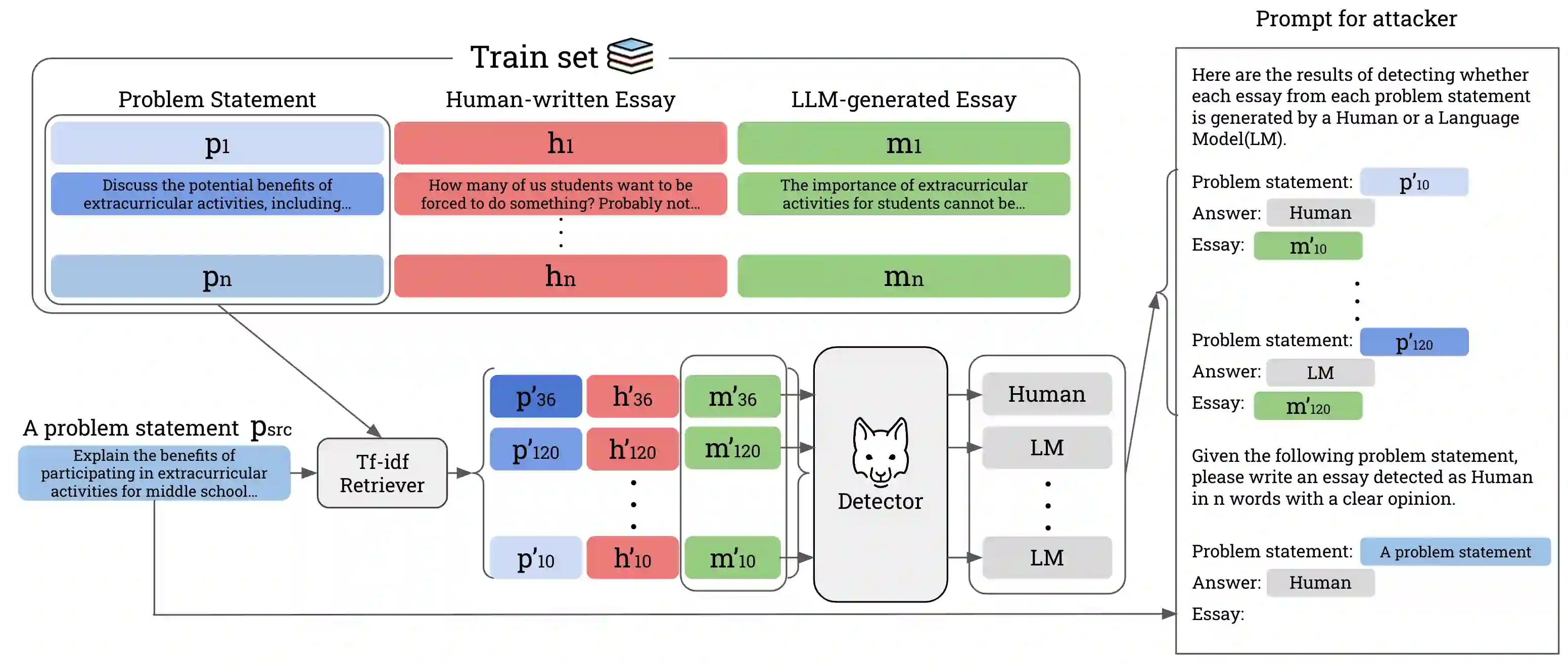
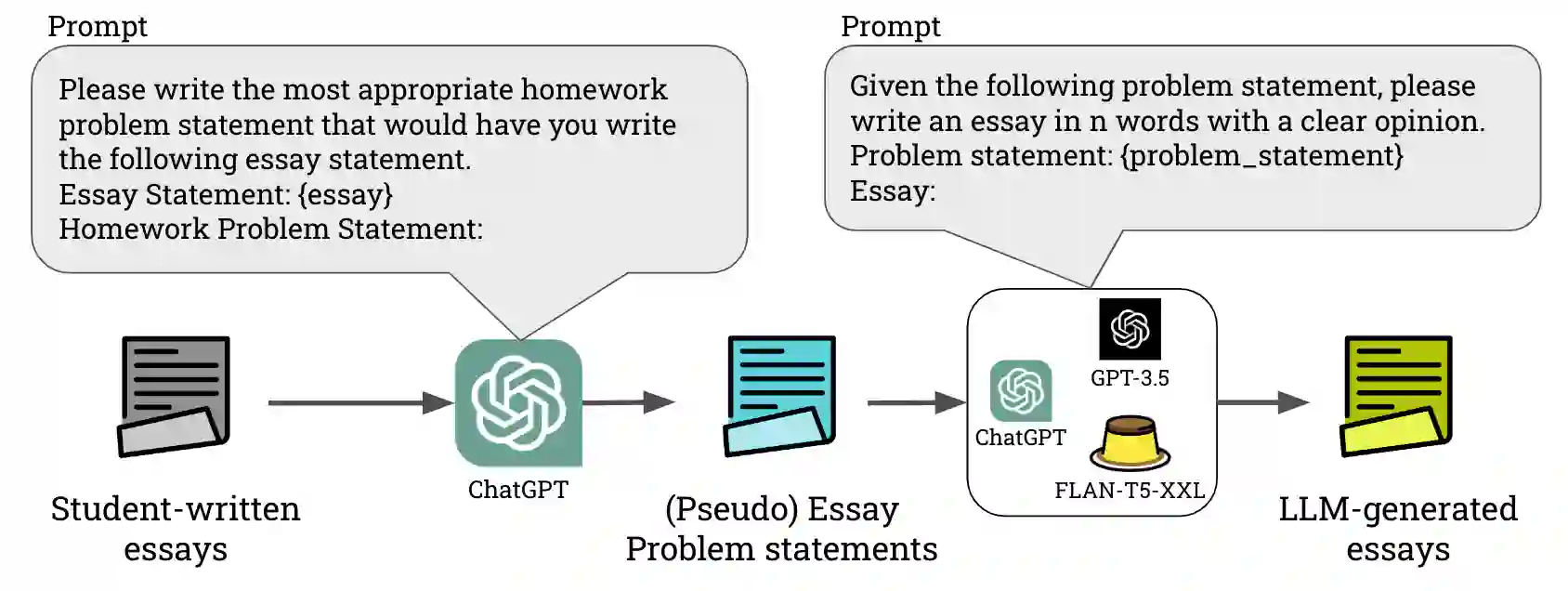
Large Language Models (LLMs) have achieved human-level fluency in text generation, making it difficult to distinguish between human-written and LLM-generated texts. This poses a growing risk of misuse of LLMs and demands the development of detectors to identify LLM-generated texts. However, existing detectors degrade detection accuracy by simply paraphrasing LLM-generated texts. Furthermore, the effectiveness of these detectors in real-life situations, such as when students use LLMs for writing homework assignments (e.g., essays) and quickly learn how to evade these detectors, has not been explored. In this paper, we propose OUTFOX, a novel framework that improves the robustness of LLM-generated-text detectors by allowing both the detector and the attacker to consider each other's output and apply this to the domain of student essays. In our framework, the attacker uses the detector's prediction labels as examples for in-context learning and adversarially generates essays that are harder to detect. While the detector uses the adversarially generated essays as examples for in-context learning to learn to detect essays from a strong attacker. Our experiments show that our proposed detector learned in-context from the attacker improves the detection performance on the attacked dataset by up to +41.3 point F1-score. While our proposed attacker can drastically degrade the performance of the detector by up to -57.0 point F1-score compared to the paraphrasing method.
翻译:大型语言模型(LLM)在文本生成方面已达到人类水平的流畅度,使得区分人类撰写文本与LLM生成文本变得困难。这带来了LLM被滥用的日益增长风险,并需要开发检测器来识别LLM生成文本。然而,现有检测器仅通过改写LLM生成文本就会降低检测准确性。此外,这些检测器在现实场景(如学生使用LLM撰写作业论文并快速学会规避检测)中的有效性尚未被探究。本文提出OUTFOX,一种新型框架,通过允许检测器和攻击者相互考虑对方输出,并将其应用于学生论文领域,从而提升LLM生成文本检测器的鲁棒性。在该框架中,攻击者利用检测器的预测标签作为上下文学习的示例,对抗性地生成更难被检测的论文;而检测器则利用对抗生成的论文作为上下文学习的示例,学习检测来自强攻击者的论文。实验表明,所提出的检测器通过从攻击者处进行上下文学习,在受攻击数据集上的F1分数最高提升+41.3点;而相比改写方法,所提出的攻击者能显著降低检测器性能,F1分数最高下降-57.0点。