

摘要:机械解释性(MI)已成为揭示大语言模型(LLMs)不透明决策过程的重要方法。然而,现有的综述主要将 MI 视为一种观测性科学,总结了分析性的见解,但缺乏可操作干预的系统框架。为了弥补这一空白,我们提出了一个围绕“定位、引导和改进”流程构建的实用综述。我们根据特定的可解释对象正式分类了定位(诊断)和引导(干预)方法,以建立严格的干预协议。此外,我们展示了该框架如何实现对齐、能力和效率的切实提升,从而有效地将 MI 转化为模型优化的可操作方法论。随着可操作机械解释性的快速发展,我们承诺保持本综述的更新,确保其反映该领域的尖端进展。
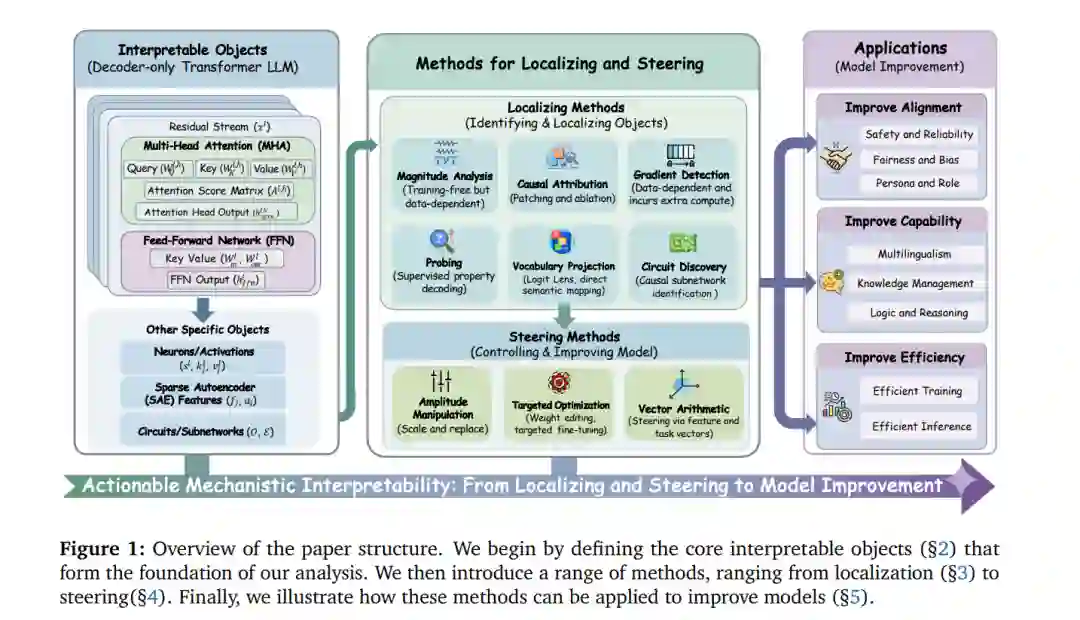
1. 引言
大语言模型(LLMs)近期取得了卓越的成功,在从复杂推理、多语言处理到高度专业化领域的广泛应用中展现了出色的性能 (Li et al., 2025i; Ren et al., 2025b; ...; Qwen et al., 2025)。尽管取得了这些进展,一个关键挑战依然存在:这些模型的内部决策过程在很大程度上是不透明的,通常作为“黑盒”运行。这种透明度的缺失带来了显著风险,特别是在安全关键型应用中,并严重限制了我们高效调试、控制和优化模型行为的能力 (Huang et al., 2024a; Hong et al., 2024; Zhang et al., 2025d)。因此,机械解释性(Mechanistic Interpretability, MI)已成为一个关键的研究方向。与传统的行为分析不同,MI 旨在对这些复杂的神经网络进行“逆向工程”,将其复杂的计算分解为可理解的组件和因果机制 (Ferrando et al., 2024; Zhao et al., 2024a; Geiger et al., 2025)。 目前该领域的研究大致分为两类。大量工作聚焦于 MI 的理论与基础层面 (Räuker et al., 2023; ...; Gantla, 2025)。这些研究为剖析 Transformer 架构和识别基础单元提供了技术路线图。然而,它们主要优先考虑科学发现——旨在为了理解模型自身而阐明其内部运作机制。它们通常将 MI 视为一门观测性科学,而对于如何将这些微观见解转化为实际的模型改进,研究尚不充分。 认识到解释性的应用潜力,第二条研究路线已开始弥合理论理解与实际利用之间的鸿沟。这些综述讨论了如何利用 MI 技术辅助下游任务或特定领域 (Luo and Specia, 2024; ...; Lin et al., 2025)。然而,尽管这些综述做出了贡献,但仍面临两个主要局限,阻碍了其更广泛的采用。首先,它们往往缺乏在实际应用语境下对 MI 方法的充分分类和清晰定义,诊断工具与干预技术之间的区别经常模糊不清。其次,它们对应用的覆盖往往不够全面,且对方法的说明通常过于笼统。这种高层级的抽象使得研究人员难以将理论上的机械见解转化为针对特定问题的可操作干预。因此,目前明显缺乏一个能够系统分类这些方法并清晰展示“主动模型改进”具体流程的统一指南。 为了填补这一空白,我们提出了“定位、引导与改进(Locate, Steer, and Improve)”流水线。这一概念框架旨在系统地将 MI 从一门被动的观测性科学转变为一门可操作的干预学科。本工作的主要贡献如下: * 1) 严谨的流程驱动框架: 我们建立了一个将 MI 应用于现实世界模型优化的结构化框架。我们首先定义了 LLMs 中的核心可解释对象(如神经元、注意力头、残差流)。基于应用工作流,我们将方法论清晰地划分为两个不同阶段:定位(诊断)——识别负责特定行为的因果组件;以及引导(干预)——主动操纵这些组件以改变模型输出。至关重要的是,针对每种技术,我们都提供了详细的方法论形式化描述及其适用对象和范围,帮助读者快速理解技术实现及适用的使用场景。 * 2) 全面的应用范式: 我们围绕三个主题对 MI 应用进行了广泛调研:提升对齐性、提升能力和提升效率。这些主题涵盖了从安全性和多语言处理到高效训练等八个具体场景。我们并没有简单地列举相关论文,而是总结了每个场景下具有代表性的 MI 应用范式。这种方法使读者能够快速掌握 MI 技术在不同应用语境下的独特使用模式,促进方法向新问题的迁移。 * 3) 见解、资源与未来方向: 我们批判性地讨论了当前可操作 MI 研究中的挑战,并勾勒了具有前景的未来方向。为了促进进一步的进展并降低准入门槛,我们精心策划了包含 200 多篇论文的完整合集,并在表 2 中列出。这些论文根据其对应的定位和引导方法进行了系统标记,为社区提供了一个实用且易于导航的参考资料。


