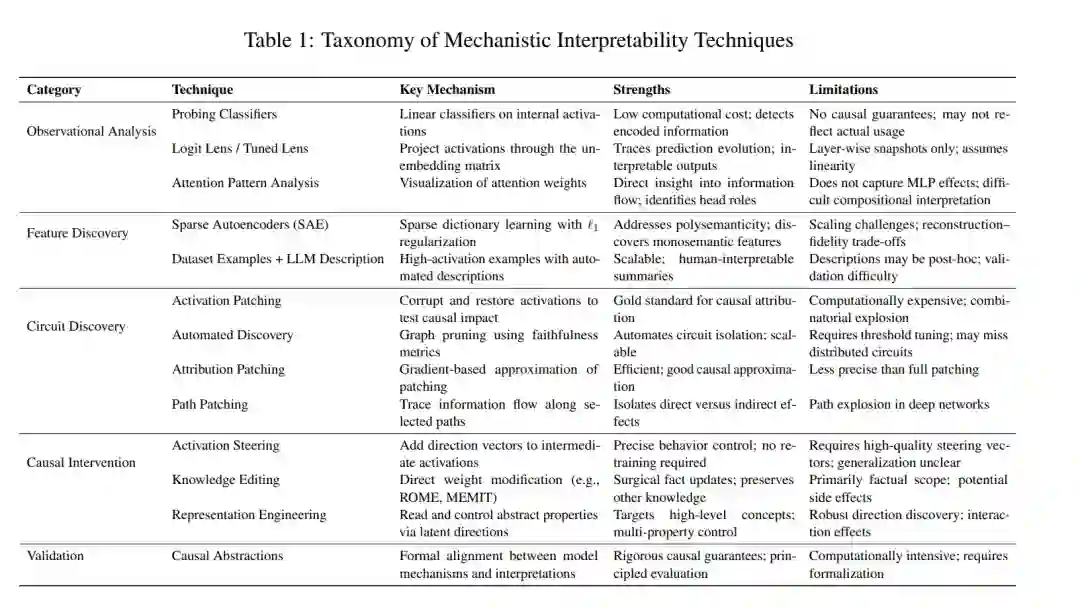
大语言模型(LLMs)在多种任务中展现出卓越的能力,但其内部决策过程在很大程度上仍是不透明的。机械解释性(Mechanistic Interpretability)——即通过神经元学习到的表征与计算结构,系统性地研究神经网络如何实现算法——已成为理解与对齐这些模型的关键研究方向。本文综述了应用于 LLM 对齐的机械解释性技术的最新进展,考察了从电路发现(Circuit Discovery)到特征可视化、激活引导(Activation Steering)以及因果干预等多种方法。 我们分析了解释性见解如何为对齐策略提供支持,包括基于人类反馈的强化学习(RLHF)、宪法 AI(Constitutional AI)以及可扩展监督(Scalable Oversight)。此外,本文还识别了当前面临的核心挑战,包括叠加假说(Superposition Hypothesis)、神经元的多义性(Polysemanticity),以及在大规模模型中解释涌现行为的复杂性。最后,我们提出了未来的研究方向,重点关注自动化解释性、电路的跨模型泛化,以及开发能够扩展至前沿模型的解释性驱动对齐技术。 大语言模型(LLMs)的飞速进步使得对鲁棒对齐技术的需求日益迫切,以确保这些系统表现出符合人类价值观和意图的行为 (Ouyang et al., 2022; Bai et al., 2022)。尽管基于行为的对齐方法——如 RLHF 和各种提示策略——已在实践中取得成功,但它们仍将模型视为“黑盒”,对于模型在面对新颖情境或对抗性输入时的泛化能力,所能提供的保证十分有限 (Casper et al., 2023)。 机械解释性(Mechanistic Interpretability)提供了一种互补的范式:即理解 LLMs 在训练过程中学习到的内部算法和表征 (Olah et al., 2020; Elhage et al., 2021)。通过对模型行为背后的计算机制进行逆向工程,研究人员旨在开发出更具原则性的对齐方法,从而在保留有益能力的同时,直接修改或约束那些存在问题的电路。 近期的研究表明,基于 Transformer 的 LLMs 会学习到实现特定算法功能的、被称为“电路(circuits)”的可解释子结构 (Wang et al., 2022; Conmy et al., 2023)。这些发现使得针对对齐目的的靶向干预成为可能,包括通过激活编辑引导模型行为 (Li et al., 2023),以及识别并消减欺骗性或有害的推理模式 (Zou et al., 2023)。 本文对应用于 LLM 对齐的机械解释性技术进行了全面的综述。我们围绕以下三个核心问题展开讨论: * 已取得哪些进展? 我们回顾了解释性方法的重大突破及其在对齐挑战中的应用。 * 还存在哪些根本性挑战? 我们分析了在实现大规模模型全面解释性方面存在的理论与实践障碍。 * 哪些未来方向最具前景? 我们确定了开发可扩展、自动化解释性技术的研究重点,以支持对能力日益增强的系统进行对齐。