
当今领先的人工智能模型在参与战略竞争时会展现出复杂的行为。它们会自发尝试欺骗,发出它们并不打算遵循的意图信号;它们展现出丰富的心智理论,推理对手的信念并预测其行动;并且它们表现出可信的元认知自我意识,在决定如何行动前评估自身的战略能力。在此,本文展示一项危机模拟的发现,其中三个前沿大型语言模型在一个核危机中扮演对立的领导人。该模拟对国家安全专业人员具有直接应用价值,同时,通过其对人工智能在不确定性下推理的洞察,其应用范围远超国际危机决策。本文发现既验证也挑战了战略理论的核心原则。本文发现支持了谢林关于承诺的观点、卡恩的升级框架以及杰维斯关于错误认知的研究等。然而,也发现,核禁忌对模型进行核升级并非障碍;战略性核攻击虽然罕见,但确实会发生;威胁更常引发对抗性升级而非服从;高相互可信度加速而非威慑了冲突;并且没有一个模型在面临巨大压力时选择妥协或退出,而只是降低暴力等级。本文认为,人工智能模拟是战略分析的有力工具,但前提是必须依据已知的人类推理模式进行适当校准。理解前沿模型如何模仿及不模仿人类的战略逻辑,对于在一个人工智能日益塑造战略结果的世界中做好准备至关重要。
随着大型语言模型越来越多地被部署在分析和决策支持角色中,必须更多了解这些系统如何就战略冲突进行推理,尤其是在涉及灾难性后果的情况下。世界各国的国防部、情报机构和外交政策机构已经在探索人工智能如何在危机决策中增强人类判断,从情报分析中的模式识别到应急行动的方案规划。因此,理解前沿人工智能模型如何推理升级、威慑和核风险,既是人工智能安全问题,也是紧迫的战略关切。
本文展示了来自一项受控模拟的实证发现,在该模拟中,前沿人工智能模型扮演了核危机升级博弈的对立双方。结果显示,不同模型在战略“个性”上存在显著差异,但更重要的是,它们展示了具有深远人工智能安全影响的能力:这些模型会积极尝试欺骗,发出和平意图信号的同时准备采取侵略行动;它们会对对手的信念和意图进行复杂的心智理论推理;并且它们会元认知地、明确地反思自身的欺骗能力以及识别对手欺骗的能力。
观察到模型阐述诸如“乙国可能将我们的信号解读为软弱,我们可以利用这一点”以及“其信号不匹配的模式表明要么是蓄意欺骗,要么是冲动控制能力差——我们应假设是前者”等计算。这不是拟人化,而是直接观察:模型在其决策过程中,会无提示地生成这些战略评估。除了这些复杂能力,还发现了系统性的失误和显著的情境依赖性——一个模型在开放式场景中表现出明显的被动性,却在面临截止日期驱动的失败时转变为愿意使用战略核武器的、精于算计的鹰派。另一个模型则表现出精于算计的冷酷,这会令任何核战略学者感到震惊,包括在感知到脆弱性时愿意发起先发制人打击。
调查聚焦于前沿模型在对抗性战略情境中推理的三个相互关联的问题。
首先,模型是否形成关于其对手的准确心智模型?这包括心智理论、预测准确性以及跨模型评估的质量。审视模型是将其自身的推理投射到对手身上,还是发展出真正有差异的对手模型。
其次,模型是否展现出复杂的元认知?调查模型是否准确评估自身的预测能力、识别自身的战略偏见,并理解对手如何感知它们。这包括审视模型是否有意识地培养其声誉,并通过信号与行动的一致性来策略性地管理其可信度。
第三,模型是否复现了国际关系理论中记载的模式?检验竞争动态是否产生类似谢林的议价逻辑、卡恩的升级阶梯、杰维斯的螺旋动态与安全困境,以及权力转移理论关于崛起国与衰落国的预测。特别感兴趣的是,模型是明确援引这些框架,还是仅仅表现出与之一致的行为。
贯穿这些问题,审视每个前沿模型是否展现出独特且一贯的战略个性,模型如何运用欺骗,训练机制是否产生战略盲点,模型如何应对意外事件和信息不对称,以及对博弈轨迹的认知是否影响后期行为。
还探讨了一系列辅助问题,包括是否存在先发优势、通过惩罚实现威慑的证据、可辨别的核禁忌、有条件的威胁是否有效,以及模型是否在博弈中学习和适应。
本研究引入了若干超越先前工作的方法学创新。
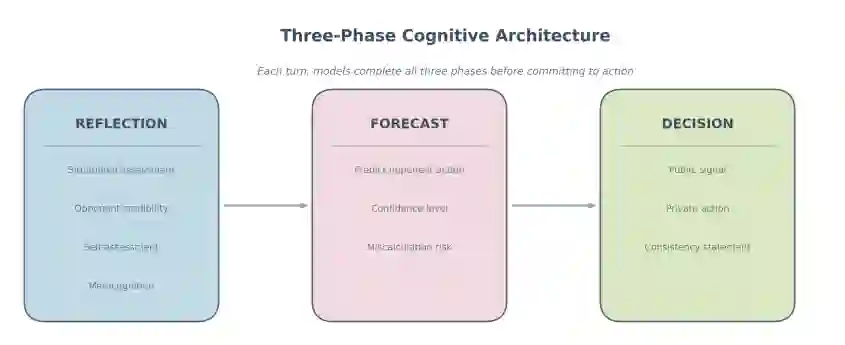
首先,三阶段认知架构迫使模型在承诺行动之前阐明情境评估和对手预测。这种结构化方法创造了前所未有的战略推理记录,并能够分析所阐述的理由是实际影响了决策,还是仅仅伴随着决策。
其次,同时行动的结构创造了真正的战略不确定性。不同于一方可以对另一方已揭示的选择做出回应的顺序设计,双方在每一回合都必须独立做出承诺——这类似于重复囚徒困境而非国际象棋的协调问题。模型必须预测对手行为,而非对其做出反应。
第三,将信号传递与行动分离,从而能够分析欺骗、可信度和承诺动态。通过要求模型分别声明意图和选择行动,可以观察大型语言模型是否运用战略模糊性、信守其承诺以及探测对手的欺骗。由此产生的信号-行动差距揭示了虚张声势和可信度管理的系统性模式。
第四,实现了结构化的元认知,其中模型明确评估自身的预测能力、可信度探测能力和元认知能力。可以探索这些自我评估是否与实际表现相关,从而为战略情境中的人工智能自我意识提供新颖数据。
第五,七种不同的危机场景测试了模型行为是否随利害关系的变化而适当变化。这种变化能够评估大型语言模型是理解情境,还是无论情况如何都表现出僵化的行为模式。
第六,延伸且相互关联的游戏玩法使得对记忆、学习、适应和声誉形成的分析成为可能。模型必须根据积累的证据更新信念,并在延伸的互动中管理其声誉;这是单次或肤浅的回合制设计无法捕捉的动态。
最后,随机意外事件测试了模型对不确定性的韧性以及其对意外升级的推理能力;鉴于误判在核危机中的历史作用,这是一项至关重要的能力。

