本文介绍 GLM-5,一个旨在实现从“氛围编程”(Vibe Coding)向“智能体化工程”(Agentic Engineering)范式转换的下一代基座模型。在前代模型所具备的智能体、推理与编程(ARC)能力基础之上,GLM-5 采用了动态稀疏架构(DSA),在保持长文本保真度的同时,显著降低了训练与推理成本。 为了提升模型的对齐效果与自主性,我们实现了一套新型异步强化学习基础设施,通过解耦生成过程与训练过程,极大地提高了后训练阶段的效率。此外,我们提出了新型异步智能体强化学习(Asynchronous Agent RL)算法,进一步优化了强化学习的质量,使模型能够更有效地从复杂的长程交互中学习。 通过上述创新,GLM-5 在主要公开基准测试中均达到了当前最优(SOTA)性能。最关键的是,GLM-5 在真实世界的编程任务中展现了前所未有的能力,在处理端到端软件工程挑战方面超越了以往的所有基准模型。相关的代码、模型及更多信息已发布于:https://github.com/zai-org/GLM-5。 https://www.zhuanzhiai.com/paper/49753eaf536e2e758d9a5ae5949663e2
1 引言 (Introduction)
追求通用人工智能(AGI)不仅需要扩展模型参数规模,更需要从根本上重新思考智能的效率以及自主进化的架构。随着 GLM-4.5 的发布,我们证明了将智能体、推理与编程(ARC)能力统一整合至单模型专家(Model-of-Experts, MoE)架构中,可以在各类基准测试中取得当前最优(SOTA)的结果。然而,随着大语言模型(LLMs)从被动的知识库向主动的问题解决者转变,计算成本与现实世界适应性(尤其是在复杂的软件工程领域)的双重挑战已成为主要瓶颈。
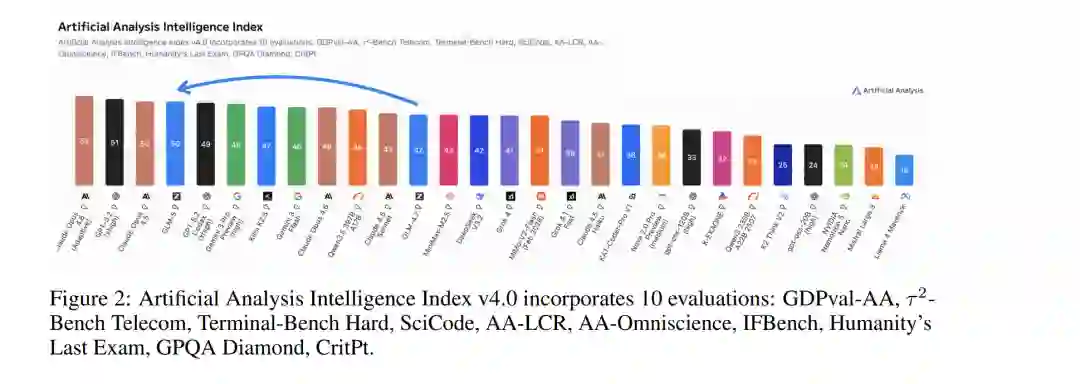
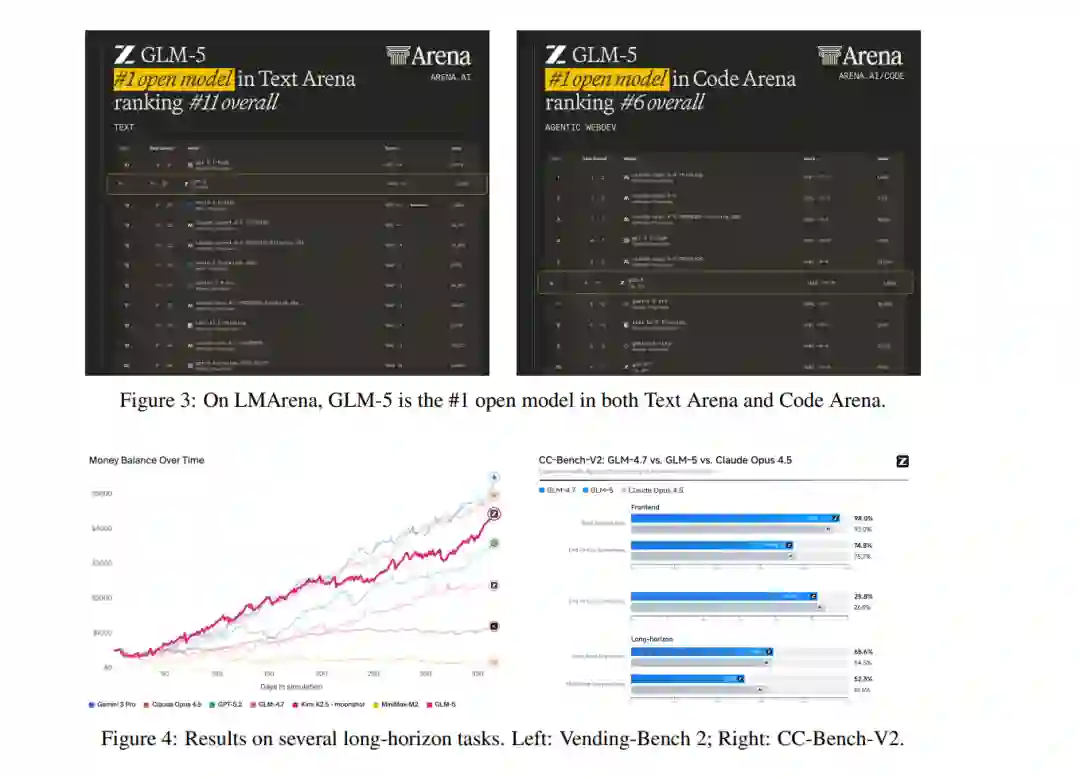
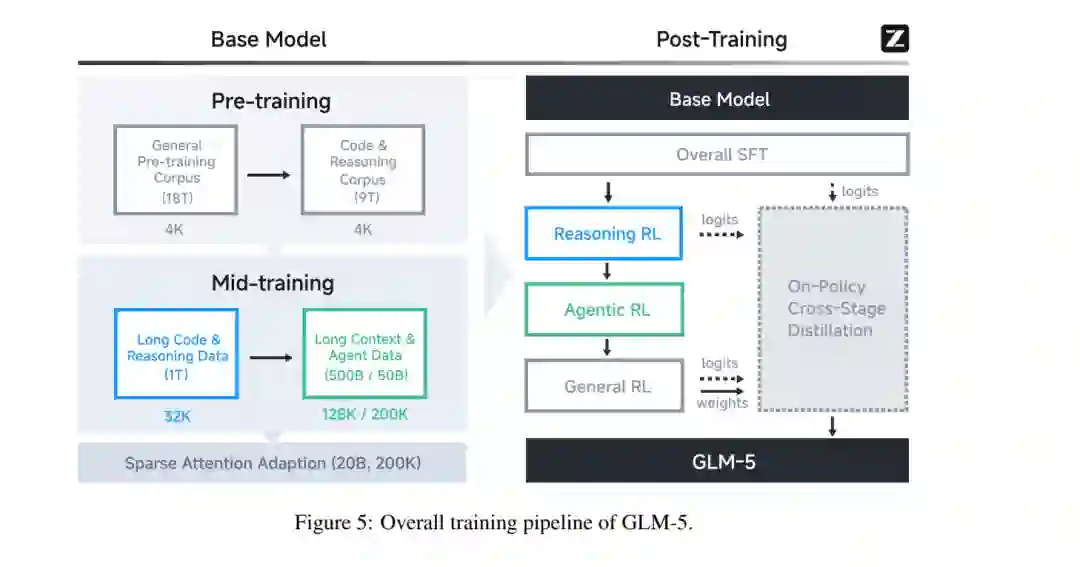
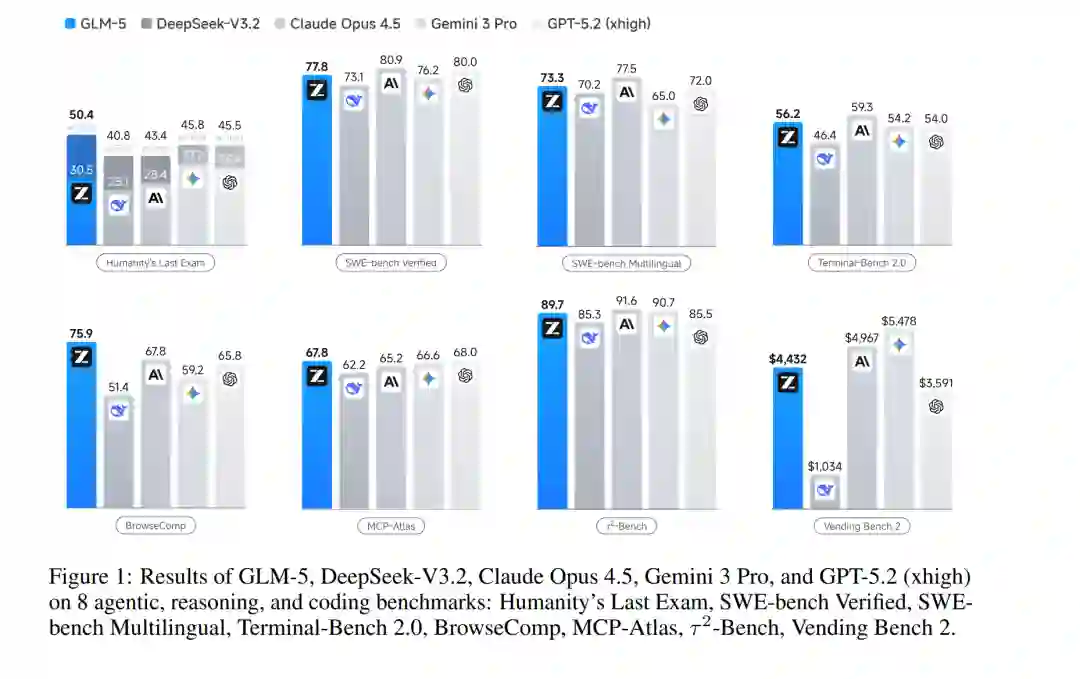
我们推出 GLM-5,这是我们的下一代旗舰模型,旨在克服这些障碍。GLM-5 代表了性能与效率的范式转变,在包括 ArtificialAnalysis.ai、LMArena Text 以及 LMArena Code 在内的主要公开榜单中均达到了 SOTA 地位。更具意义的是,GLM-5 重新定义了真实世界编程的标准,展现出处理复杂端到端软件开发任务的前所未有的能力,其范围远超 SWE-bench 等传统静态基准测试。 结果 (Results)。 图 1 展示了 GLM-5、GLM-4.7、Claude Opus 4.5、Gemini 3 Pro 以及 GPT-5.2 (xhigh) 在 8 项智能体、推理与编程基准测试中的结果,包括:Humanity’s Last Exam [34]、SWE-bench Verified [19]、SWE-bench Multilingual [53]、Terminal-Bench 2.0 [45]、BrowseComp [50]、MCP-Atlas [6]、$\tau^2$-Bench [55; 7] 以及 Vending Bench 2 [3]。平均而言,GLM-5 较上一版本 GLM-4.7 提升了约 20%,与 Claude Opus 4.5 和 GPT-5.2 (xhigh) 持平,且优于 Gemini 3 Pro。 GLM-5 在 Intelligence Index v4.0 中得分 50,成为新的开源权重模型领跑者(参见图 2),较 GLM-4.7 的 42 分实现了 8 分的跨越——这一增长主要由智能体性能的提升以及知识/幻觉问题的改善所驱动。这是开源权重模型首次在 Artificial Analysis Intelligence Index v4.0 上达到 50 分。 由加州大学伯克利分校(UC Berkeley)发起的 LMArena 是一个透明的共享平台,通过数百万个真实任务(包括写作、编程、推理、设计、搜索和创作)的人类判断来评估和比较前沿 AI 能力。海量的人机交互产生了反映真实世界实用性的信号,使其区别于其他静态基准测试。图 3 显示,GLM-5 在文本竞技场(Text Arena)和编程竞技场(Code Arena)中再次蝉联开源模型第一,整体水平与 Claude-Opus-4.5 和 Gemini-3-pro 相当。 智能体的长期一致性(Long-term coherence)正变得愈发重要。编程智能体现已能够自主编写代码数小时,且 AI 模型能够完成的任务长度与广度可能会持续增加。我们使用 Vending-Bench 2 和 CC-Bench-V2 两个基准测试来评估 GLM-5 完成长程任务(long-horizon tasks)的能力。Vending-Bench 2 用于衡量 AI 模型在长期经营业务中的表现:模型需模拟经营一家自动售货机公司长达一年,并根据最终的银行账户余额进行评分。图 4(左)显示,GLM-5 在所有开源模型中排名第一,最终账户余额为 4,432 美元,接近 Claude Opus 4.5,展现出强大的长期规划与资源管理能力。图 4(右)进一步展示了在我们内部评估套件 CC-Bench-V2 上的结果。GLM-5 在前端、后端及长程任务上均显著优于 GLM-4.7,缩小了与 Claude Opus 4.5 的差距。 方法 (Methods)。 图 5 展示了 GLM-5 的整体训练流程。我们的基座模型训练始于 27 万亿(27T)token 的海量语料库,并在早期阶段优先考虑编程与推理数据。随后,我们采用了独特的“中阶训练”(Mid-training)阶段,将上下文长度从 4K 逐步扩展至 200K,重点针对长文本智能体数据,以确保复杂工作流中的稳定性。在后训练(Post-Training)阶段,我们超越了标准的监督微调(SFT),实现了一套序列化强化学习流水线:从推理 RL(Reasoning RL)开始,随后是智能体 RL(Agentic RL),最后以通用 RL(General RL)收尾。至关重要的是,我们在整个过程中采用了同策略跨阶段蒸馏(On-Policy Cross-Stage Distillation),以防止灾难性遗忘,确保模型在成为强力通用模型的同时,保留其敏锐的推理优势。总而言之,GLM-5 性能的飞跃主要源于以下技术贡献:
第一,我们采用了 DSA(DeepSeek Sparse Attention) [9],这是一种创新的架构,可显著降低训练与推理成本。虽然 GLM-4.5 通过标准 MoE 架构提升了效率,但 DSA 允许 GLM-5 根据 token 的重要性动态分配注意力资源,在不牺牲长文本理解或推理深度的情况下大幅降低计算开销。凭借 DSA,我们将模型参数扩展至 744B,并将训练 token 预算增加到 28.5T。
第二,我们设计了一套全新的异步强化学习基础设施。基于 GLM-4.5 中初始化的 “slime” 框架和解耦采样引擎(decoupled rollout engines),新基础设施进一步将生成过程与训练过程解耦,以最大化 GPU 利用率。该系统允许大规模探索智能体轨迹,消除了此前阻碍迭代速度的同步瓶颈,显著提升了强化学习后训练流水线的效率。
第三,我们提出了新型异步智能体强化学习(Asynchronous Agent RL)算法,旨在增强自主决策的质量。在 GLM-4.5 中,我们利用迭代自蒸馏和结果监督来训练智能体;而对于 GLM-5,我们开发了异步算法,使模型能够持续从多样化的长程交互中学习。这些算法专门针对动态环境中的规划与自纠错能力进行了优化,直接促成了我们在真实编程场景中的主导地位。
最后,另一项技术贡献在于 GLM-5 从第一天起就实现了对中国 GPU 生态的全栈适配。我们成功完成了从底层算子内核(kernels)到上层推理框架的深度优化,覆盖了华为昇腾(Ascend)、摩尔线程(Moore Threads)、海光(Hygon)、寒武纪(Cambricon)、昆仑芯(Kunlunxin)、沐曦(MetaX)和燧原(Enflame)等七大主流国产芯片平台。
凭借这些进步,GLM-5 不仅是一个更强大的模型,更为下一代 AI 智能体提供了更高效、更实用的基石。我们将 GLM-5 开源给社区,以进一步推进高效、智能体化通用智能的前沿。