
在机器人操控领域,视觉-语言-动作(VLA)模型近年来取得了令人瞩目的进展,尤其是在精心设计的清洁基准测试上,它们能够以高成功率执行复杂任务。然而,当这些模型被部署到真实的物理世界时,情况远非理想:相机传感器噪声、运动模糊、雾霾、雨雪等视觉扰动几乎无处不在。一个关键问题随之浮现:当前最先进的VLA模型在面对训练数据中从未出现的视觉退化时,表现如何?北京大学Yiyang Fu、Chubin Zhang等作者与业界合作者在发表于ICML 2026的论文《StableVLA: Towards Robust Vision-Language-Action Models without Extra Data》中,通过系统性实验揭示了一个令人担忧的现象:即使在清洁环境下成功率达到96%的模型,在受到中等程度视觉扰动后,性能可能骤降近50%,某些模式甚至直接跌至0%。更关键的是,这种脆弱性并非个别模型所独有,而是普遍存在于OpenVLA、OpenVLA-OFT、OpenPi-0.5等多个主流VLA架构中。
针对这一痛点,作者提出了一种轻量级的架构级解决方案——信息瓶颈适配器(IB-Adapter)。该模块基于信息瓶颈理论,在视觉编码器与大语言模型(LLM)之间的投影模块中引入通道级协方差建模与Sigmoid门控机制,从而自动过滤视觉输入中的噪声,同时保留任务相关语义。相比传统的MLP投影器,IB-Adapter仅增加不到10M参数,却在无需任何额外数据或数据增强策略的条件下,将基线模型平均性能提升了30%。更令人印象深刻的是,使用0.5B参数的StableVLA(基于小模型),无需在Open X-Embodiment大规模数据集上预训练,就能达到与7B规模SOTA VLA模型相当的鲁棒性。这篇论文不仅为VLA模型的鲁棒性研究提供了理论视角和实用工具,也为机器人领域“少数据、轻模型、高鲁棒”的落地路径提供了有力支撑,值得所有从事机器人感知与控制的研究者仔细研读。
论文基本信息
英文题目 StableVLA: Towards Robust Vision-Language-Action Models without Extra Data 作者 Yiyang Fu, Chubin Zhang, Shukai Gong, Yufan Deng, Kaiwei Sun, Qiyang Min, Qibin Hou, Yansong Tang, Jianan Wang, Daquan Zhou arXiv ID 2605.18287 类别 cs.CV, cs.RO Comments Accepted by ICML 2026 原文链接 http://arxiv.org/abs/2605.18287v1
摘要
训练数据集不可能覆盖所有可能的视觉扰动,这意味着当视觉-语言-动作(VLA)模型在真实世界不完美视觉条件下运行时,其鲁棒性面临根本性挑战。本文基于当前最先进的VLA模型进行系统性研究,揭示了一个关键问题:当引入训练数据中不存在的视觉扰动时,模型的性能会显著下降。为缓解这一问题,作者提出了一种基于信息论的轻量级适配器模块,称为信息瓶颈适配器(IB-Adapter),该模块选择性地过滤视觉输入中的潜在噪声。IB-Adapter无需任何额外数据或数据增强策略,平均可将基线模型性能提升30%,同时仅增加不到10M参数,展现了显著的效率与效果。更进一步,即使使用14倍小的骨干网络(0.5B参数)且未在Open X-Embodiment数据集上预训练,所提出的StableVLA模型也能达到与7B规模最先进VLA模型相竞争的鲁棒性。在参数开销可忽略(<10M)的前提下,StableVLA在长时任务上保持了准确性,并在合成及物理视觉退化条件下超越了OpenPi。项目网站、GitHub和HuggingFace模型已公开。
引言:论文要解决什么问题
现有VLA模型的评估主要依赖于精心设计的、视觉条件受控的基准环境。然而,真实世界的机器人部署不可避免地会遭遇传感器噪声、运动模糊、天气干扰等视觉退化,这些扰动在精心整理的数据集中几乎不存在。这种基准与真实环境之间的差异导致了一个明显的性能鸿沟。例如,当前性能领先的VLA-Adapter模型在清洁数据下成功率高达96%,但一旦注入自然视觉扰动,性能平均下降近50%,某些模式(如严重模糊)下甚至会降至0%。这一脆弱性不仅限于VLA-Adapter,作者还确认OpenVLA、OpenVLA-OFT、OpenPi-0.5等模型也表现出类似的系统性退化。 面对这一问题,常见的增强鲁棒性策略依赖于使用额外数据进行预定义的扰动训练或数据扩增。然而,这种方法面临两个根本局限:第一,模拟真实世界扰动的无限组合空间在计算上不可行;第二,用扩增数据训练往往导致模型记忆特定噪声模式,而非学习鲁棒的不变特征,从而限制了其泛化到未见扰动的能力。因此,作者提出了一个核心问题:能否通过架构设计实现内在鲁棒性,而不依赖暴力数据缩放? 通过一系列经验实验,作者发现脆弱性的一个重要来源是连接视觉编码器与LLM骨干网络的投影模块。在无噪声输入下,经过视觉编码器和投影模块处理后的特征一致性还尚可;但在噪声输入下,投影模块输出的特征一致性严重下降(例如,从0.70降至0.30),表明该模块充当了全通滤波器,不加区分地传播噪声。这一观察为后续设计提供了关键动机。 基于信息瓶颈理论的内在特征选择性质,作者提出了一种全新的模块结构——IB-Adapter,用于连接视觉分支和LLM骨干。通过简单地将VLA-Adapter中原有的适配器模块替换为IB-Adapter并重新训练,在合成视觉扰动下平均性能提升了35.2%;在真实机器人实验中,在抓取放置任务上性能提升了31.7个百分点。由于在视觉扰动下表现出的强大鲁棒性,该模型被命名为StableVLA。值得注意的是,StableVLA保留了VLA-Adapter的轻量训练流程,仅通过适配器级别的架构替换(无额外训练数据),就超越了参数规模大14倍的OpenVLA以及使用更多数据训练的π-0.5等强基线。本文的主要贡献包括:(1)经验证明当前SOTA VLA模型在合成与真实机器人场景中对视觉扰动高度脆弱,且脆弱性关联于投影模块;(2)提出基于信息瓶颈的无数据解决方案IB-Adapter,在零样本扰动设定下平均提升35.2%性能;(3)所提StableVLA(0.5B)在LIBERO基准上达到与7B模型竞争的鲁棒性,在真实机器人任务中超越OpenPi。
方法:核心思路与技术路线
3.1 从信息瓶颈视角看模态对齐
标准的VLA模型由三个主要部分组成:视觉编码器E、可学习的投影器ϕ用于模态对齐、以及基于LLM的策略模型π。给定观察图像I和文本指令T,编码器提取视觉令牌Xv = E(I) ∈ R^(N×Dv),投影器将其映射到LLM嵌入空间:Z = ϕ(Xv) ∈ R^(N×D),之后LLM自回归地预测动作a = π(Concat(Z, XT)),其中XT为文本令牌嵌入。在开放世界环境中,视觉输入I由任务相关语义和任务无关扰动(如传感器噪声)共同组成。现有的VLA投影器主要采用MLP层实现。从信息瓶颈(IB)视角来看,这种简单的投影器充当“全通滤波器”,会不加区分地最大化互信息I(Xv; Z)。为了强制实现内在鲁棒性,作者将模态对齐建模为一个IB问题: min_ϕ(Z|Xv) LIB = I(Xv; Z) - β I(Z; S) 其中Z是压缩后的表示,过滤扰动同时保留目标干净代码S(即预测动作a所需的真实任务相关语义)。系数β控制压缩与信息保留之间的权衡。关键洞察在于:虽然现代ViT编码器在空间维度上有效利用了IB驱动的分组机制,但对于VLA投影器而言,在通道维度上执行这种分组更为关键,因为视觉编码器输出中语义和噪声往往异质地分布在不同的通道上。这引出了IB-Adapter的设计:将每个通道视为一个信息单元进行IB优化,通过建模通道间依赖关系来识别鲁棒的语义子空间并抑制不相关的噪声。作者进一步给出了理论推导(Proposition 3.1):在Gaussian和潜结构假设下,最优表示Z的迭代更新步骤对应于一种通道级注意力操作: Z = V · σ(β Q^⊤ K) 其中Q, K, V是Xv的线性投影,σ(·)为归一化函数:在分类潜结构下为Softmax,在独立Bernoulli潜结构下为Sigmoid。该推导将IB驱动的分组扩展到通道维度,使过滤能够动态抑制噪声通道并突出稳定特征,在特征传播到下游策略模型之前建立表示鲁棒性。
3.2 信息瓶颈适配器 (IB-Adapter)
为了在模态对齐阶段实施IB原理,作者提出IB-Adapter。与独立处理通道的MLP不同,IB-Adapter建模通道间协方差来识别并放大鲁棒语义信号。设X' ∈ R^(N×D)为输入特征(如中间投影器特征),该机制包含三个关键组件:子空间协方差建模、Sigmoid门控和非线性特征变换。 子空间协方差建模采用多头设计来捕捉H个不同语义子空间的关联。输入X'被划分为H个头[X'1, ..., X'H],每个头X'h ∈ R^(N×d)具有通道维度d=D/H。对每个头h,通过可学习投影Wq ∈ R^(d×d)得到查询Qh = X'h Wq ∈ R^(N×d),而键Kh = X'h通过输入特征的恒等映射定义。这种恒等键设计确保后续协方差计算根植于视觉令牌的内在几何流形,从而保留可能被冗余投影削弱的高频空间线索。为建模通道间依赖,沿序列维度N聚合关联,计算Gram矩阵Gh = Q^⊤_h Kh ∈ R^(d×d),其中每个元素Gh[i,j]表示所有空间令牌上通道i和j之间的协方差。 Sigmoid子空间门控为了将语义簇与独立噪声分离,对Gram矩阵应用可学习的Sigmoid门控函数:Ah = σ(Gh · τh) ∈ [0,1]^(d×d),其中τh是可学习温度参数。使用Sigmoid门控函数在理论上由通道的独立Bernoulli潜结构假设驱动。表示非相关传感器噪声的通道应与语义承载通道表现出低协方差,从而使门控值接近零。与Softmax不同,Sigmoid允许每个通道对独立地被抑制,不强制概率竞争,从而更灵活地进行噪声过滤。 非线性特征变换:经过门控后的注意力图Ah与值Vh结合进行重构,经过非线性变换和非线性激活(如GELU)后输出最终特征Zh。整个流程可形式化为: Zh = f_nonlinear( Vh · Ah ) 其中Vh = X'h Wv,Wv为可学值投影。
3.3 融合鲁棒语义与高频细节的混合架构:Fused IB-Adapter
尽管IB-Adapter在抑制噪声方面表现出色,但纯粹的IB架构可能会过于激进地压缩高频空间细节,而这些细节对于精细操纵(如精确抓取)至关重要。为此,作者提出了核心贡献——Fused IB-Adapter,它是一种混合架构,将IB-Adapter与标准MLP并联,从而同时保留鲁棒语义和高频细节。 具体地,对于输入特征X',Fused IB-Adapter的输出由两部分组成:
- 一个分支使用IB-Adapter处理,负责过滤噪声、提取鲁棒语义。
- 另一个分支使用标准MLP(含线性变换与激活函数)处理,保留精细空间信息。
两个分支的输出通过可学习权重进行相加或拼接(原文采用相加),最终输出特征既包含去噪的语义聚类,又保留了空间结构。这种设计使得StableVLA在低噪声场景下仍能保持清洁输入的性能,同时在高噪声场景下通过IB分支提供鲁棒性。整个StableVLA框架中,将VLA-Adapter原有的线性瓶颈替换为Fused IB-Adapter,其他部分保持不变,从而以极小的参数增量(<10M)实现了显著的鲁棒性提升。
配图:方法结构

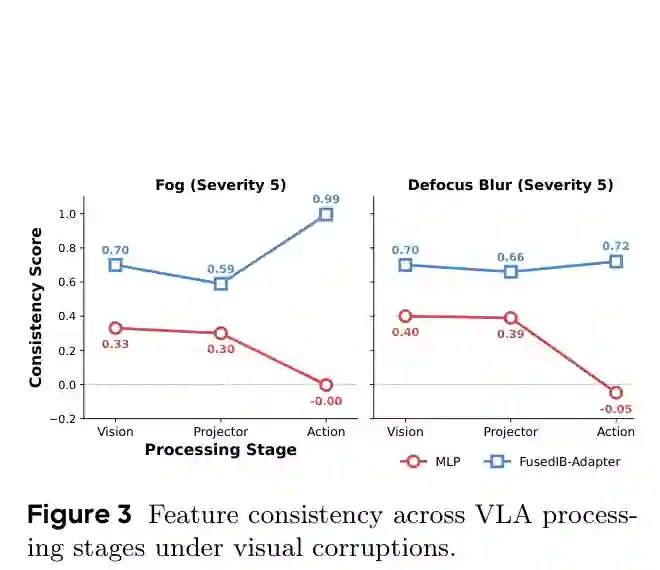
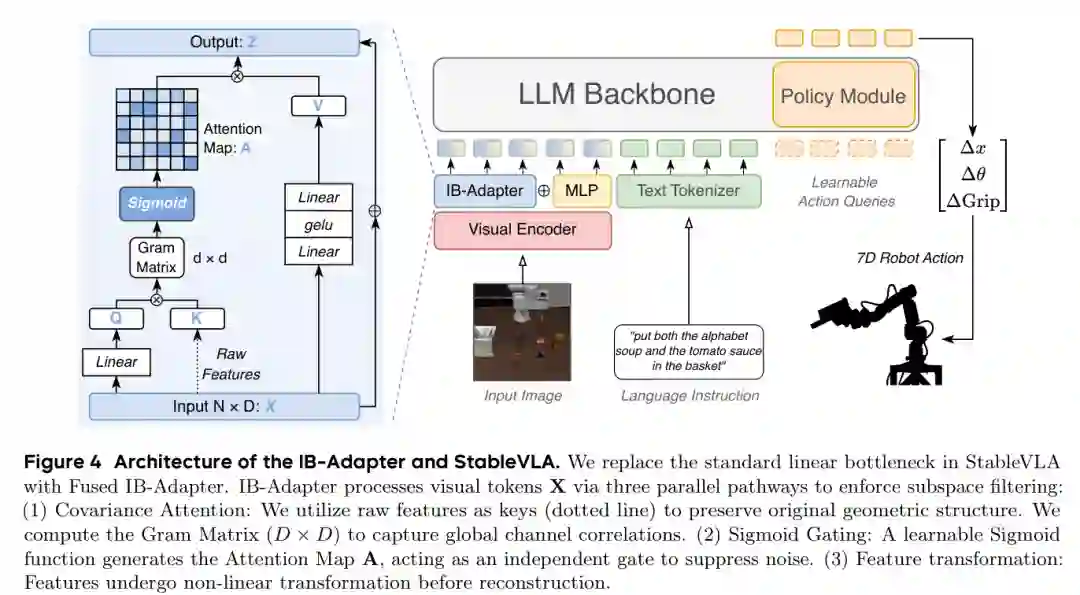
实验:设置、指标与结果
4.1 基准设置
基准数据集:选取广泛使用的LIBERO基准(包含四个任务套件:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal、LIBERO-Long),每个套件含10个子任务,每个子任务评估50个回合,报告平均成功率(0-100%)。此外,使用CALVIN基准评估零样本泛化性能,要求模型在未见过的环境中完成预定义序列的1000个任务,每个任务由5个子任务组成,报告平均完成子任务数(0-5)。 扰动协议:采用ImageNet-C的扰动协议,使用imagecorruptions库提供的19种扰动,涵盖四大类:噪声(高斯噪声、散粒噪声、脉冲噪声等)、模糊(散焦模糊、运动模糊等)、天气(雾、雪、霜冻等)和数字(亮度、对比度、弹性变换等)。所有扰动定义5个严重度级别,实验聚焦于高严重度区间(级别3-5)以严格测试架构稳定性。每个扰动类型在清洁、级别3、4、5设置下评估。为节省计算成本,除LIBERO-Spatial使用全部19种扰动外,其余三个套件和CALVIN排除了玻璃模糊(Glass Blur),使用18种扰动。 训练协议:StableVLA将VLA-Adapter框架中的MLP投影器替换为Fused IB-Adapter,并从零开始在LIBERO和CALVIN上训练。训练时仅使用轻微的几何(裁剪)和光度(颜色抖动)扩增以防止过拟合,不暴露任何评估所用的扰动,也不使用任何专门的鲁棒性技术(如对抗训练)。因此,对扰动数据的评估严格属于零样本架构泛化测试。 基线模型:包括VLA-Adapter、OpenVLA、OpenVLA-OFT和OpenPi-0.5,涵盖从0.5B到7B不同规模的模型。
4.2 主要结果
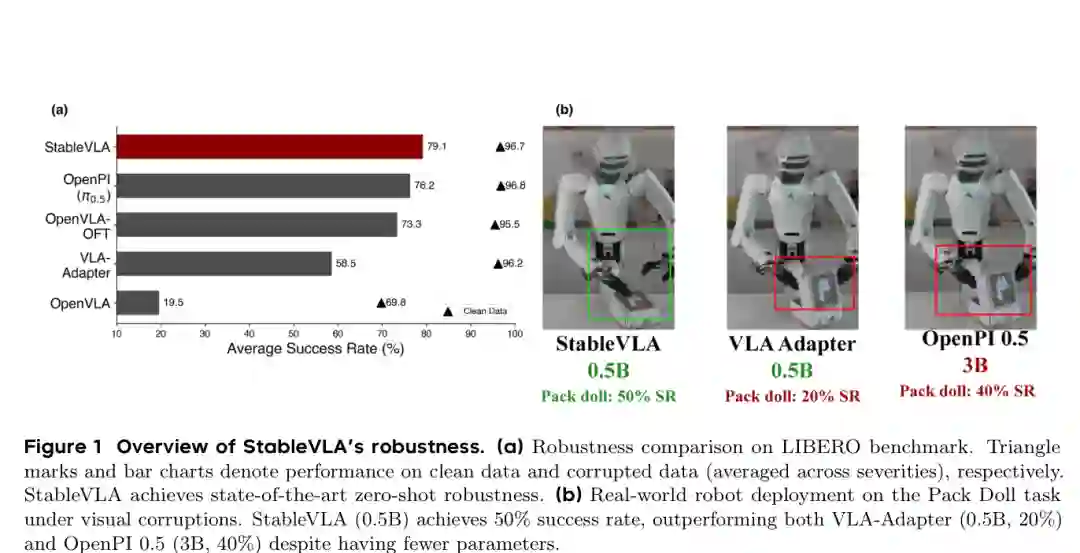
全面鲁棒性分析:在LIBERO上,StableVLA在所有任务套件和所有扰动严重度级别下展现出最优或次优的零样本鲁棒性。与共享相同架构的VLA-Adapter相比,在严重度5级下,四个任务套件的性能提升范围达40.2%至139.6%。在CALVIN上,StableVLA在所有扰动级别下均完成更多任务。雷达图(图5a)显示,StableVLA在几乎所有扰动类别上优于VLA-Adapter,并与OpenPi-0.5和OpenVLA-OFT等大规模模型竞争,尽管StableVLA参数量仅为0.5B且未在Open X-Embodiment上预训练,但其鲁棒性已达到与7B级模型相当的水平。 真实机器人部署:在Pack Doll任务中,机器人需通过拾取和放置动作将娃娃装入包装盒。视频背景包含意外光照变化和运动模糊等真实扰动。StableVLA(0.5B)达到50%成功率,显著优于VLA-Adapter(0.5B,20%)和OpenPi-0.5(3B,40%),尽管参数量更少。此外,在清洁设置下,StableVLA保持了与VLA-Adapter相当或更优的性能,表明Fused IB-Adapter未损害清洁场景下的表现。 特征可视化分析:为揭示机制,作者对Fused IB-Adapter和标准MLP的输出特征进行K-Means聚类(K=2)。在脉冲噪声下(一种高频、空间独立扰动),标准MLP产生弥散特征,将任务相关区域与背景混淆,且在高噪声下进一步恶化;而Fused IB-Adapter的输出保持紧凑、以对象为中心的语义聚类。这一差异归因于协方差驱动的Sigmoid门控:随机扰动与对象结构相关性低,产生低Gram矩阵值,被Sigmoid门抑制,从而输出干净的特征表示。
配图:实验结果
结论:贡献、局限与启发
主要贡献:本文系统验证了当前SOTA VLA模型在面对未见视觉扰动时存在的严重脆弱性,并定位了投影模块是脆弱性的关键来源。基于信息瓶颈理论,提出了轻量级IB-Adapter,通过通道级协方差建模与Sigmoid门控实现噪声过滤。进一步提出Fused IB-Adapter混合架构,在保持清洁任务性能的同时显著提升鲁棒性。所构建的StableVLA(0.5B参数)无需额外数据或数据扩增,仅通过<10M参数的适配器替换,即实现了平均30%的性能提升,并在多个基准和真实机器人任务中达到或超越7B级模型的鲁棒性。该工作首次证明,通过精心的架构设计无需暴力数据缩放即可实现VLA模型的强鲁棒性,为低参数、高效率的机器人学习提供了新路径。 局限性:原文未明确阐述局限性,但可以推测:(1)当前评估主要基于合成扰动和有限真实场景(Pack Doll任务),更广泛真实环境(如剧烈光照变化、物理遮挡等)下的表现有待验证;(2)IB-Adapter的理论推导基于Gaussian和独立Bernoulli潜结构假设,可能不完全适用于所有类型的视觉退化;(3)Fused IB-Adapter的并联设计引入了一个超参数(两个分支的权重),虽简单固定但可能需要针对不同任务微调。此外,论文未探讨IB-Adapter是否适用于多模态输入(如深度、触觉)或动态场景(如视频输入)。 启发与展望:该研究启发我们重新审视VLA模型的鲁棒性来源,提示在架构设计层面嵌入先验知识(如信息瓶颈)可能比单纯扩大数据更高效。未来方向包括:将IB-Adapter推广到其他跨模态对齐场景(如文本-图像检索、视觉问答)、探索自适应门控阈值、结合对抗训练进行互补,以及研究在强化学习在线微调过程中的鲁棒性保持。对于从业者而言,本文提供了一个立即可用的轻量级模块——只需替换VLA模型中的投影器,即可在不增加过多计算负担的条件下显著提升部署鲁棒性。
原文信息
论文原文链接:http://arxiv.org/abs/2605.18287v1 项目网站:https://dagroup-pku.github.io/StableVLA/ 代码仓库(HuggingFace):https://huggingface.co/DAGroup-PKU/StableVLA GitHub(HumanNet子模块):https://github.com/DAGroup-PKU/HumanNet/tree/main/src/model/StableVLA