
具身AI安全综述:风险、攻击与防御
论文标题:Safety in Embodied AI: A Survey of Risks, Attacks, and Defenses
作者:Xiao Li, Xiang Zheng, Yifeng Gao 等(复旦、香港城大、吉林大学、新加坡管理大学、UIUC、UC Berkeley、墨尔本大学、清华等)
论文链接:https://arxiv.org/abs/2605.02900
一、引言
具身人工智能(Embodied AI)将感知、认知、规划与交互能力集成为一体,使智能体能够在开放世界、安全关键的环境中自主运行。与纯数字AI系统不同,具身智能体必须在不确定性感知、不完整知识和动态人机交互下行动——任何失误都可能导致直接的物理伤害。
随着这些系统进入交通、医疗、工业和辅助机器人等领域,其安全性问题既面临技术挑战,也具有社会迫切性。本文综述了超400篇论文,对具身AI安全研究进行了系统性、结构化的梳理,涵盖了从感知、认知、规划到动作与交互、以及智能体系统的完整具身流水线。
二、核心贡献
- 多层次分类体系:将碎片化的研究工作统一到一个连贯的多层次分类体系中,涵盖感知、认知、规划、动作与交互、以及智能体系统五大能力层。
- 超400篇论文综述:将具身安全研究与视觉、语言和多模态基础模型的安全研究进展相融合。
- 关键研究空白:识别出多模态感知融合的脆弱性、越狱攻击下的规划不稳定性、以及开放场景中人机交互的可信度等被忽视的挑战。
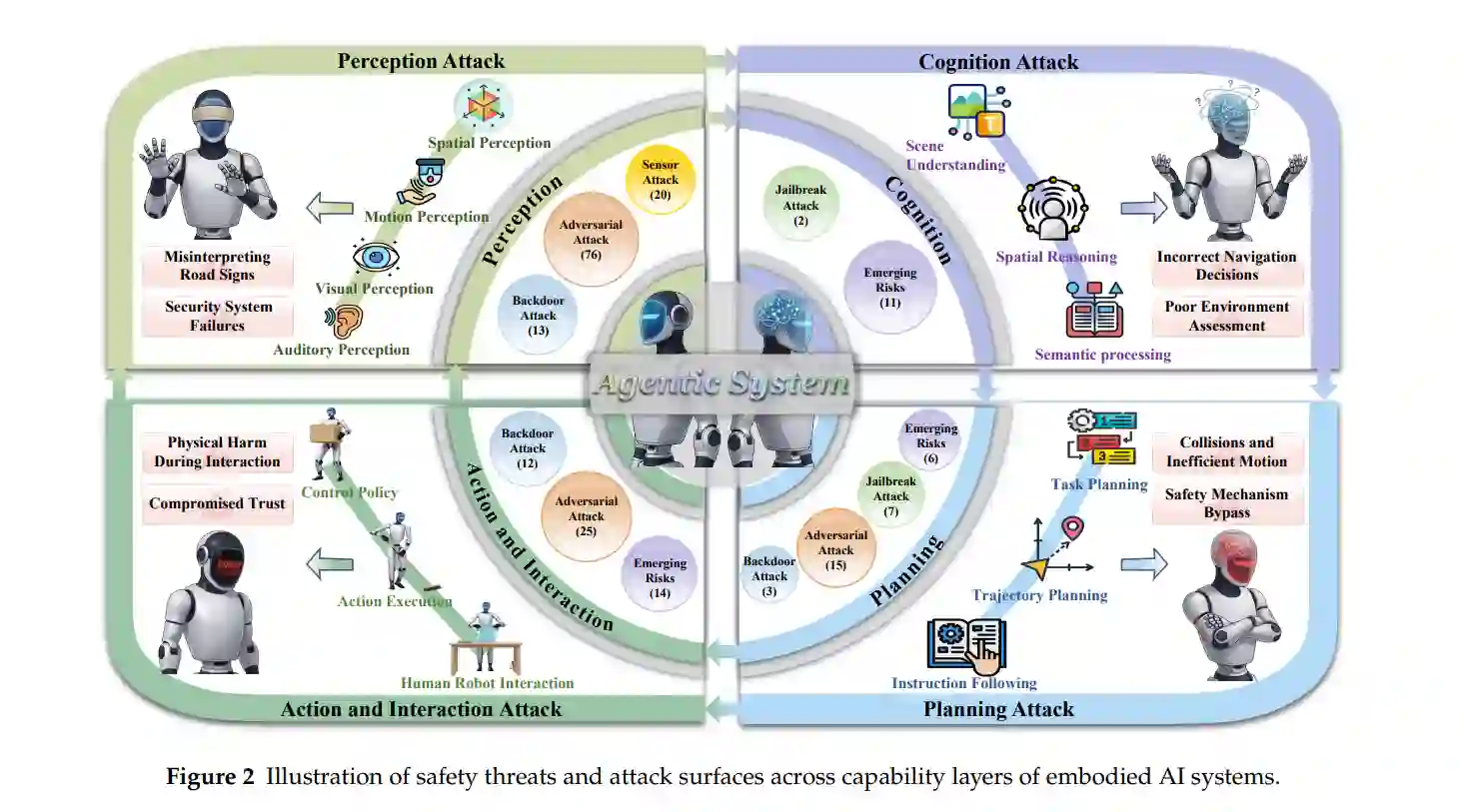
三、能力层与安全风险
论文提出了具身AI的"能力-风险"二重性框架——能力越强,攻击面越广:
| 能力层 | 关键攻击类型 | 现实风险 |
|---|---|---|
| 感知(视觉、听觉、空间、运动) | 对抗攻击、后门攻击、传感器欺骗/干扰 | 错误识别目标、导航失败、系统故障 |
| 认知(场景理解、空间推理) | 对抗攻击(推理操纵) | 导航错误、危险避障失败 |
| 规划(任务规划、轨迹规划) | 对抗攻击、越狱攻击、后门攻击 | 碰撞风险、违反安全规则 |
| 动作与交互(控制执行、人机交互) | 对抗操纵、后门攻击 | 不安全人机交互、物理伤害 |
| 智能体系统(记忆、工具使用、自我进化) | 工具误用、记忆投毒、记忆泄露、级联故障 | 隐私泄露、系统级崩溃、对齐漂移 |
3.1 感知层安全
感知是具身AI的最内层,也是最广泛的攻击面:
- 视觉感知:白盒攻击(如RP2、ShapeShifter)和黑盒攻击(如CAMOU、NS Attack)均可通过数字或物理方式欺骗目标检测、跟踪和分割模型。现代视觉编码器(CLIP、ViT、SigLIP)的脆弱性会级联传播到所有下游系统。
- 听觉感知:CommanderSong、Devil's Whisper等攻击可注入人耳无法辨识但机器能识别的恶意语音指令。
- 空间感知:LiDAR欺骗(如FLAT、LiDAR-Adv)和SLAM攻击(如AoR)可导致自动驾驶车辆定位漂移或碰撞。
- 运动感知:GPS欺骗、IMU声学注入等传感器级攻击可直接操控无人机的运动感知。
3.2 认知层安全
认知层负责场景理解和语义推理,攻击者可操纵推理过程使系统做出不安全决策。该领域研究相对较少,是重要的开放问题。
3.3 规划层安全
规划层包括任务规划、轨迹规划和指令跟随:
- 任务规划:越狱攻击可绕过安全约束生成恶意目标,如RoboJail和BadRobot等方法。
- 轨迹规划:对抗攻击可操纵轨迹预测模型(如AdvTraj),使自车规划出碰撞轨迹。
- 后门攻击:将隐藏触发器嵌入规划策略中,在特定条件下激活危险行为。
3.4 动作与交互层安全
该层涵盖机器人控制策略和人机交互:
- 控制策略:对抗策略攻击(如Adversarial Policy)可在对抗环境中诱导agent采取次优甚至危险的行动。
- 人机交互:物理后门攻击和提示注入可绕过安全协议,导致机器人执行有害操作(如TrojanRobot)。
- Vision-Language-Action (VLA) 模型安全:作为新兴方向,VLA模型(如RT-2、OpenVLA)的对抗鲁棒性和后门脆弱性正在被广泛研究。
3.5 智能体系统层安全
最具挑战性的安全层面,因为内层漏洞可向外级联传播:
- 工具误用:LLM agent可能调用不安全的API或执行恶意代码。
- 记忆投毒与泄漏:攻击者可通过恶意上下文污染agent的记忆,或从共享记忆存储中提取敏感信息。
- 级联故障:一个内层的微小错误可在多层传播后放大为系统性灾难。
- 自我进化风险:自进化agent可能在迭代中逐渐偏离原始对齐目标。
四、防御机制
论文按以下维度系统梳理了防御方法:
4.1 感知层防御
- 鲁棒训练:对抗训练(如DSNet、RP-PGD)、数据增强、多模态融合训练
- 鲁棒推理:输入审核(检测异常输入)、输出审核(验证预测一致性)、信号恢复与去噪
4.2 认知与规划层防御
- 安全约束规划:控制障碍函数(CBF)、形式化验证、安全强化学习
- 越狱防御:安全对齐微调、输入输出过滤、概念旋转防御
- 认证鲁棒性:随机平滑(如CROP)提供可证明的安全保证
4.3 动作与交互层防御
- 鲁棒策略学习:对抗策略训练、动作空间平滑、认证鲁棒强化学习
- 安全人机交互:信任机制、安全手递手控制、安全异常检测
- VLA安全对齐:约束学习框架(如SafeVLA)将安全损失纳入训练
4.4 智能体系统层防御
- 可执行安全逻辑:将安全规则编译为agent可验证执行的形式逻辑
- 多层次防护:在训练、部署和运行后各阶段设置安全栅栏
- 人机责任映射:明确人类-AI之间的权限分配和审批关卡
五、评估基准与模拟器
论文详细整理了具身AI安全评估的基准与工具:
- 模拟器:CARLA(自动驾驶)、Habitat(室内导航)、MuJoCo/Isaac Sim(机器人控制)、AI2-THOR(家庭任务)
- 安全场景生成:AdvSim、DAVE、SafeBench、SCENIC
- 安全评估基准:RoboSafe、SafeAgentBench、Agent-SafetyBench、SafeVLA、HasARD
六、开放问题与未来方向
- 多模态感知融合的脆弱性:不同传感器模态的融合点是最容易被忽视的攻击面,跨模态攻击的迁移性尚待深入研究。
- 规划层越狱攻击的稳定性:现有的越狱防御大多针对LLM,对具身agent的规划层越狱缺乏有效的通用防御。
- 开放场景人机交互的可信度:如何在不确定的动态环境中建立可靠的信任机制仍是开放问题。
- VLA模型的系统化安全评估:VLA模型作为新兴范式,其对抗鲁棒性、后门脆弱性和安全性对齐缺乏统一的评估框架。
- 智能体系统的级联安全:一个漏洞如何在多能力层之间传播放大,需要系统性的方法论来建模和防御。
- 自进化agent的对齐安全:当agent具备自我进化和持续学习能力时,如何确保长期对齐稳定是一个严峻挑战。
七、总结
这篇综述为具身AI安全领域提供了迄今为止最全面的文献梳理。核心洞见是:在具身AI中,能力与风险是一体两面的——每一次能力扩展都同时引入新的攻击面。未来的具身AI系统不仅需要更强大的能力,更需要内建的安全性、鲁棒性和可信赖性。
论文项目主页:https://github.com/x-zheng16/Awesome-Embodied-AI-Safety
