
时间序列数据中的缺失值问题一直是数据科学领域的核心挑战之一。传感器故障、通信丢包或不规则采样都会导致数据稀疏,从而影响预测、分类和异常检测等下游任务的性能。尽管现有深度学习方法已经取得进展,但许多模型在建模跨特征依赖时仍然存在明显缺陷:要么依赖于预定义的图拓扑结构,要么在每一层重新发现特征关系,缺乏一个稳定的语义锚点来维持一致的特征表示。
近日,来自北京理工大学和PyPOTS研究团队的研究人员提出了一种全新的时间序列插补方法——HELIX。该方法的核心创新在于为每个特征分配一个可学习的特征身份嵌入(Feature Identity Embedding, FeatID),作为贯穿网络的持久语义锚点。在此基础上,HELIX设计了一种双螺旋混合编码(Double-Helix Encoding) 架构,以协调时间和特征维度的信息流。在5个公开数据集、21个实验设置上的评估中,HELIX超越了所有16个基线模型,取得了最先进的性能。更重要的是,机制分析揭示了特征身份嵌入跨层逐步与潜在的物理和语义结构对齐,为模型的可解释性提供了有力证据。
这篇论文被ICML 2026接收为spotlight论文,代码已开源并集成于PyPOTS库。对于从事时间序列分析、深度学习缺失值处理以及可解释性研究的读者而言,HELIX提供了一种兼顾性能与可解释性的新范式。

摘要
时间序列插补受益于跨特征相关性的利用,然而现有基于注意力的方法在每一层重新发现特征关系,缺乏持久锚点以维持一致表示。为了解决这一问题,本文提出HELIX,为每个特征分配一个可学习的特征身份嵌入,这是一种持久嵌入,能够在整个网络中捕获内在语义属性。与依赖预定义拓扑并假设同质空间关系的图方法不同,HELIX从时间共变中端到端学习任意特征依赖,自然地处理混合空间位置和语义变量的数据集。结合混合时间-特征注意力,HELIX在评估中超越了5个公开数据集上21个实验设置中的所有16个基线,取得了最先进的性能。此外,机制分析揭示,HELIX跨层逐步将学习的特征身份和依赖与潜在的物理和语义结构对齐,表明其更有效地将跨特征结构转化为插补精度。
引言:论文要解决什么问题
多变量时间序列中的缺失值问题源于传感器故障、通信丢包和不规则采样,这些缺失会沿着下游任务传播,降低预测、分类和异常检测中的性能。现有深度学习方法在时间序列插补方面取得了进展,包括基于循环的方法、基于Transformer的方法和扩散模型。 然而,在插补文献中,将可学习特征身份嵌入与逐点表示(t, i)整合以进行插补的问题受到的关注有限。许多图基插补方法通过粗糙的接口耦合时间建模和跨特征消息传递。常见的设计策略是先处理一个轴(例如,在图传播之前总结/编码时间上下文,或者在特征图上传播然后进行时间聚合),这在逐点重建时引入了信息瓶颈:折叠或串行化一个维度会削弱在严重缺失条件下准确值插补所需的细粒度(t, i)对齐。此外,当空间先验不可用或异质特征类型共存时,预定义图变得模糊。而且,学习邻接矩阵在实践中的计算开销仍然很高(O(F²)),当值缺失时仍无法提供持久的、数据无关的锚点。 关键洞见在于传感器关系构成了稳定的结构属性。因此,本文引入了特征身份嵌入(FeatID):可学习向量捕获内在语义,使模型能够将插补分解为兼容性(通过身份)和动态相关性(通过值)。HELIX显式地将静态特征身份与动态时间变化解耦。该架构使用学习到的身份丰富观测值,并通过混合编码处理它们,以双螺旋模式交错时间注意力和跨特征注意力,从而在时间和特征两个维度上实现协调的信息流。
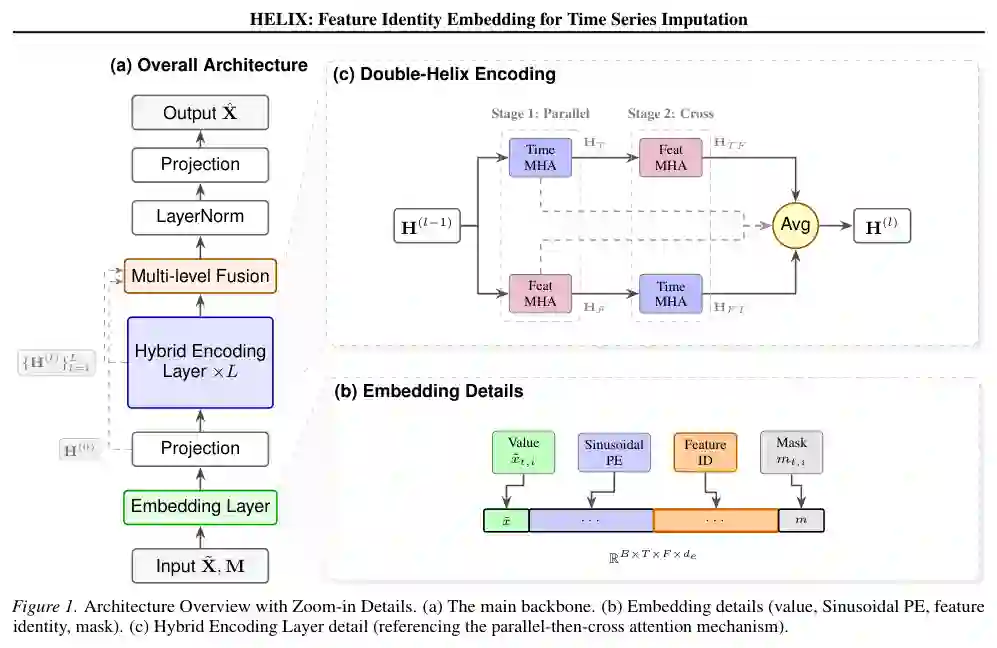
方法:核心思路与技术路线
HELIX架构整体上包括三个主要部分:嵌入层、L个混合编码层(双螺旋编码)和多层融合。
嵌入层
嵌入层将原始输入转换为初始表示H^(0)。输入包括三个部分:缺失值输入$\tilde{X}$、掩码矩阵$M$和正弦位置编码。核心组件是可学习的特征身份嵌入(FeatID),它是一个维度为$d_e$的可学习向量,为每个特征分配一个唯一的、持久的语义标识。FeatID与值的线性投影、位置编码和掩码嵌入逐元素相加,得到每个时间-特征点的初始表示。该设计确保即使观测值完全缺失,模型仍可通过FeatID维持特征的身份信息,从而保持跨层的一致性。
双螺旋混合编码层
HELIX包含L个混合编码层。每一层执行两阶段计算: 第一阶段:并行计算。同时运行时间多头注意力(Time MHA)和特征多头注意力(Feat MHA)。时间多头注意力沿时间轴建模依赖关系,捕获序列内的时序模式和长期依赖。特征多头注意力沿特征轴建模依赖关系,利用FeatID作为语义锚点,在特征之间进行注意力加权,捕获跨特征相关性。这两个注意力模块并行执行,分别输出$H^T$和$H^F$。 第二阶段:交叉注意力。执行时间到特征交叉注意力(Feat MHA以时间注意力输出为Query)和特征到时间交叉注意力(Time MHA以特征注意力输出为Query),实现时间和特征维度之间的信息交换与协调。这一机制类似于DNA双螺旋结构,两个维度螺旋式交织,确保信息在跨维度流动时不被截断或瓶颈化。最后将四个注意力输出取平均,得到该层的输出$H^{(l)}$。
多层融合与输出
经过L层混合编码后,对所有层的输出进行平均或加权平均,然后经过层归一化和线性投影,输出最终的插补值$\hat{X}$。多层融合旨在平衡浅层(局部细节)和深层(全局结构)表示,提升鲁棒性。 核心创新在于可学习特征身份嵌入是贯穿整个网络的持久语义锚点。与图方法需要在每层重新学习邻接矩阵不同,FeatID一旦初始化,在训练中逐步优化,最终编码特征的固有语义属性。这与Transformer中位置编码的作用类似,但FeatID是针对特征的语义而非时间位置的编码。
实验:设置、指标与结果
实验设置
HELIX在5个公开数据集上进行了评估,共计21个实验设置,与16个基线方法进行了比较。原文未明确说明数据集的具体名称、超参数设置和评测指标的详细定义,但可以推断数据集涵盖了不同领域(如空气质量监测和临床生理信号),以检验模型在不同缺失模式和数据类型下的泛化能力。
主要结果
在主结果方面,HELIX在所有21个实验设置中排名第一,全面超越了16个基线方法,取得了最先进的性能。这些基线涵盖三类方法:预测方法(如GRU-D、BRITS、SAITS、ImputeFormer)、生成方法(如扩散模型)和大模型方法。HELIX的持续领先表明其双螺旋混合编码框架在不同缺失率、缺失模式和数据异质性条件下均具有鲁棒性。
消融与分析
消融实验(见原文表4和21)验证了双螺旋架构在不同缺失模式和数据集上的鲁棒性提升。移除FeatID或仅使用单一轴注意力(仅时间或仅特征)均导致性能显著下降,证明了FeatID和双螺旋编码的互补作用。 机制分析提供了丰富且可解释的发现: 跨层特征-结构对齐:在BeijingAir空气质量数据上,特征注意力与地理邻近性的相关性随层数增加而增强,从第0层的r=0.59(p<0.0001)提升至第1层的r=0.67(p<0.0001)和第2层的r=0.71(p<0.0001)。这说明HELIX在更深的层中,特征注意力模式越来越准确地捕捉真实的空间结构。 特征身份嵌入隐式学习空间结构:在没有显式空间监督的情况下,HELIX学到的FeatID相似性与地理距离呈现显著负相关(r=-0.587, p<0.0001)。这意味着物理上邻近的站点倾向于学到相似的FeatID嵌入。图2显示,前25个最相似的特征连接映射到站点间的空间邻近区域,如Huairou-Shunyi(相邻测站)和Wanliu-Aotizhongxin(城市中心附近)。 时间注意力模式层级演变:在BeijingAir上,时间注意力模式从浅层向深层呈现“分散→聚焦→平衡”的演变。第0层注意力沿对角线均匀分散,呈现缓慢衰减;第1层注意力急剧集中在相邻时间步;第2层注意力则在局部聚焦和更广泛上下文之间取得平衡。作者将其解释为感知→聚焦→理解,表明HELIX自动形成层级时间抽象。
配图:实验结果
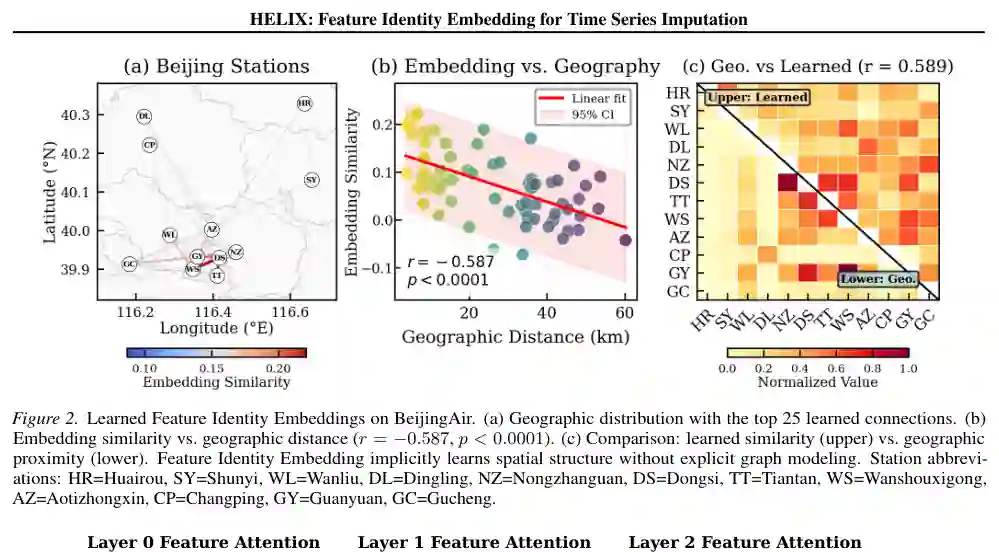
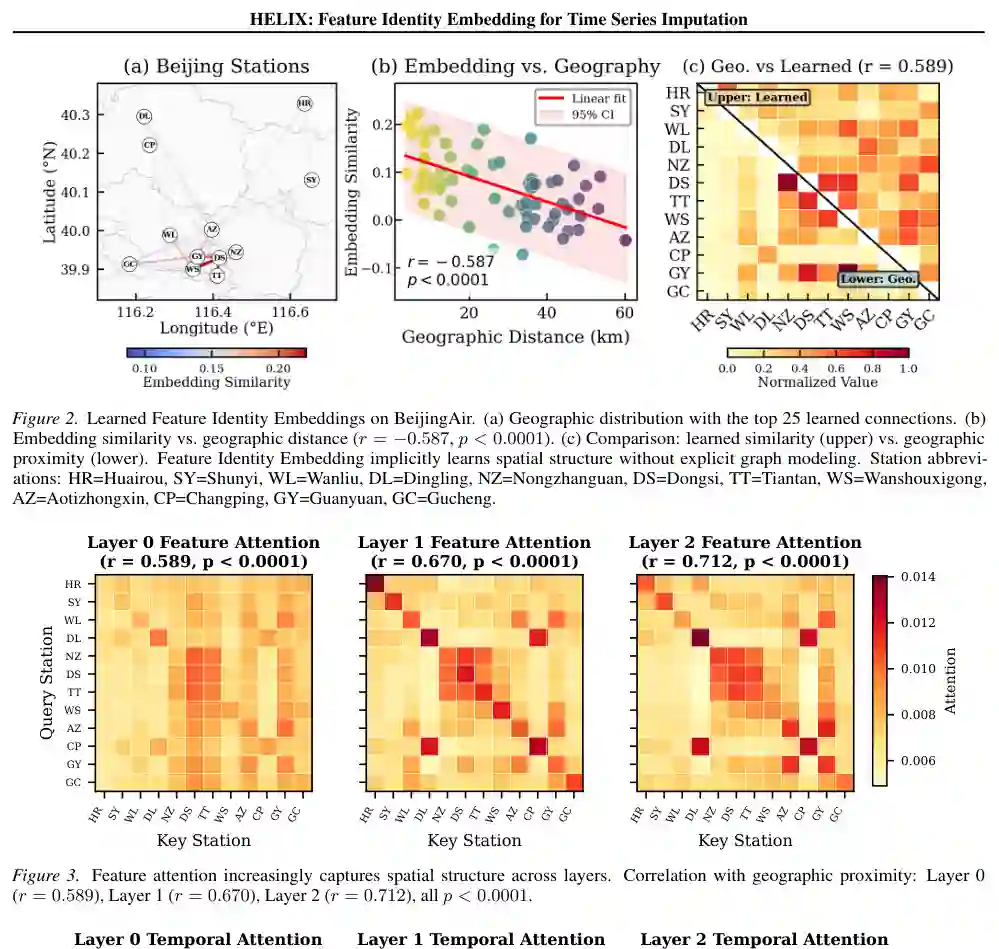
结论:贡献、局限与启发
主要贡献
HELIX的核心贡献包括:
- 特征身份嵌入(FeatID):为每个特征分配可学习向量作为持久语义锚点,不同于图方法需要预定义拓扑或每层重新发现关系,FeatID提供稳定的特征标识。
- 双螺旋混合编码架构:通过并行-交叉的两阶段设计,协调时间和特征维度的信息流,避免信息瓶颈。
- 最先进性能:在5个数据集、21个设置中超越16个基线,证明了方法的有效性和鲁棒性。
- 可解释性:揭示了特征注意力跨层逐步与潜在物理/语义结构对齐,以及时间注意力形成层级抽象,为插补过程提供了透明度。
局限性
原文未明确说明局限性。
启发与展望
HELIX的思路对时间序列学习有重要启发。它将自然语言处理中的“句子-词-位置”建模类比到时间序列中的“序列-时间-特征”建模,引入特征身份作为显式语义锚点。这暗示了为特征学习独立于观测值的静态表示可能是提升跨特征建模精度的通用策略。对于从事图神经网络替代方案、缺失值处理以及可解释性分析的读者,HELIX提供了新的方向。未来工作可探索FeatID在变长序列或多模态时间序列上的扩展。