
导读
在视频生成领域,精准的运动控制始终是一个核心挑战。用户通常通过拖动轨迹、边界框等稀疏信号来指定物体的运动方式,但现有模型会“字面地”执行这些轨迹,即使它们不完整、不精确或缺乏因果逻辑。例如,当用户画一条轨迹让手移开,但希望多米诺骨牌随后倒塌时,模型往往只让手移动,多米诺骨牌却纹丝不动——这种违反物理常识的现象频繁发生。来自加州大学美熹德分校与Adobe Research的研究团队(Lee Hsin-Ying、Hanwen Jiang、Yiqun Mei、Jing Shi、Ming-Hsuan Yang、Zhixin Shu)在ICML 2026上发表的论文《MotiMotion: Motion-Controlled Video Generation with Visual Reasoning》中,瞄准了这一痛点。
论文的核心创新在于:将运动控制从“直接跟随轨迹”重塑为“推理-生成”问题。他们引入了一个无需训练的视觉语言模型(VLM)推理器,在生成视频之前先对用户输入的轨迹进行精炼、补充因果推理,并想象合理的次要运动;同时提出置信度感知的运动控制方案,让生成器在轨迹可信度高时紧密跟随,在轨迹模糊时更多依赖自身的生成先验来纠正伪影。这里的推理器无需训练;实现上,作者基于Wan 2.2 I2V-A14B训练运动控制后端,并进一步微调其置信度感知控制能力。
值得一读的理由有三:第一,它直接回应了当前运动控制方法缺乏上下文推理的根本局限,并提供了一种轻量级解决方案;第二,论文构建了专门评估交互场景的新基准MotiBench,并同时使用VLM自动评估和人工研究验证,结果全面优于现有方法;第三,该框架与现有运动控制视频生成模型正交,可以即插即用,具有较强的实用价值。
论文基本信息

摘要
当前的运动可控图像到视频生成模型会僵化地跟随用户提供的轨迹,这些轨迹通常稀疏、不精确且因果不完整。这种依赖往往导致不自然或不可信的结果,尤其会遗漏次要因果后果。为了解决这一问题,我们提出了MotiMotion,一个将运动控制重构为推理-生成问题的新框架。为了鼓励因果一致且符合常识的交互,我们利用一个无需训练的视觉语言推理器来精炼主轨迹的图像空间坐标,并想象合理的次要运动。为了进一步提升运动自然度,我们提出了一种置信度感知的控制方案,该方案可以调节引导强度,使模型在高置信度计划下紧密跟随,而在低置信度输入下利用自身生成先验来纠正伪影。为了支撑系统评估,我们构建了一个新的图像到视频基准MotiBench,它包含由运动触发新事件的交互中心场景。基于VLM的评估和人类研究均表明,MotiMotion生成的视频具有更合理的物体行为和交互,并且比现有方法更受欢迎。
引言:论文要解决什么问题
当前的运动可控视频生成模型(如基于拖动轨迹、边界框序列或流图的控制器)在操作层面取得了显著进展,但它们存在一个根本假设:用户能够手动指定物理有效且语义合理的轨迹。然而,在实际应用中,用户提供的轨迹往往是稀疏、粗略且不精确的。例如,描述一个铰链门的运动弧线,或者指定多个物体在碰撞后的连锁反应,对用户而言极其困难。现有模型将这些不完美的输入当作“神谕”来严格执行,忽略了物理和逻辑上的空白。 论文通过具体例子揭示了问题的严重性。在图1所示的场景中,用户提供一条轨迹以“抬起阻挡多米诺骨牌的手”,但生成模型仅执行了手的抬起动作,而多米诺骨牌并未倒塌;类似地,“转动时钟的分针”这隐含了时针应同步移动的机械耦合,但模型只让分针转动,时针保持不动。这些失败表明了模型缺乏对视觉上下文的推理能力——它们无法理解“移开手”是“导致骨牌倒塌”的前提条件,也无法从“分针转动”推理出“时针联动”的因果效应。现有方法本质上只是“像素搬运工”,而非世界模拟器。 论文进一步指出,这一局限源于当前方法将运动控制视为纯信号跟随任务,忽略了规划阶段。用户输入的轨迹传达了用户的意图,但意图背后的因果链、物体属性、物理规律需要额外的推理来补全。MotiMotion正是为了填补这一空白而提出:它引入一个训练无关的VLM推理器,在生成之前对输入进行因果推理,将稀疏用户意图转化为富含物理细节的控制信号。同时,为了处理推理结果可能不准确的情况,它设计了一个置信度感知机制,让生成器根据推理结果的置信度来自适应地调整引导强度。这样,系统既利用了VLM的世界知识,又保留了视频生成模型自身的先验,从而生成符合物理和常识的视频。
方法:核心思路与技术路线
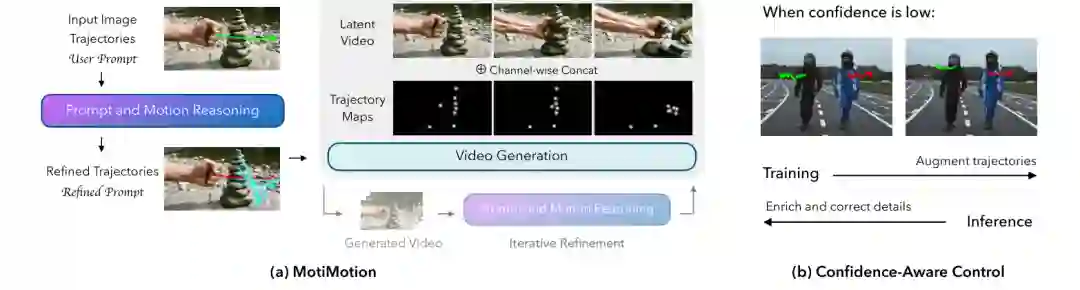
组件一:上下文与运动推理器(Context and Motion Reasoner)
该推理器基于现成的高性能VLM,论文实现中使用Gemini 3.1 Pro作为运动推理 agent。它的输入包括:当前帧图像、用户标注的轨迹(以图像空间坐标序列表示)、以及可选的文本提示。输出则是经过精炼的轨迹坐标和额外的次要轨迹。 推理器的工作流程分为两步:
- 主轨迹精炼:用户提供的轨迹往往位置不准或轨迹形状不合理(如不自然的加速曲线)。VLM根据图像上下文(如物体形状、材质、场景布局)来推断合理的运动路径。例如,对于一个铰链门,VLM会理解其旋转轴位置,将用户线性轨迹修正为圆弧轨迹。精炼后的主轨迹坐标通过VLM的文本输出直接生成,再映射回图像空间。
- 次要运动想象:这是推理器最具创新的部分。VLM依据世界知识,推测用户未显式指定但应当发生的次级运动。例如,当用户只画了手移开的轨迹,VLM会理解移除障碍物后多米诺骨牌应依次倒塌,因此额外生成一组轨迹用于控制每个骨牌的倒下;对于时钟示例,VLM会识别分针和时针的联动关系,生成时针同步移动的轨迹。这些次要轨迹同样以坐标序列形式输出,并与原轨迹合并成完整的运动计划。
值得注意的是,整个推理过程是无需训练的。论文强调,VLM的世界知识来自大规模预训练,因此可以直接零样本地完成该任务。这避免了为特定视频生成模型训练专用推理器的需要,使MotiMotion能够即插即用于任何支持轨迹控制的后端模型。 此外,推理器还支持迭代推理-生成循环(如图5所示)。如果初次生成的视频仍存在缺陷(如时钟分针转了但生成模型误解释为缩放),VLM可以基于上次生成的视频帧进行新一轮推理,修改轨迹并重新生成,直至满足要求。这个闭环提升了复杂场景的容错性。
组件二:置信度感知运动控制器(Confidence-Aware Motion Controller)
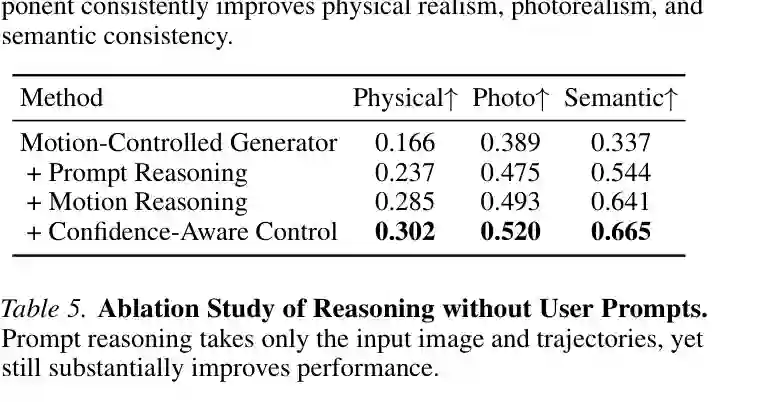
即使有VLM推理,生成的轨迹依然可能在某些区域置信度较低(例如,VLM对次要运动的位置不太确定,或者用户输入的原始区域本身模糊)。此时,如果严格遵循这些低质量的轨迹,反而可能导致不自然的运动。因此,论文提出一种置信度感知的控制方案,在生成阶段动态调节对轨迹的跟随强度。 具体实现方式如下:运动控制通常通过引导(guidance)机制实现——在扩散模型的采样过程中,将运动约束(如光流、对应点约束)作为条件去噪。MotiMotion为每个轨迹点关联一个置信度分数,该分数由VLM推理器在规划阶段自动估计(例如,VLM对某个次要运动预测的置信度,或者基于轨迹平滑度计算)。在生成时,高置信度轨迹点施加强引导,使物体严格按该路径运动;低置信度轨迹点则施加弱引导,鼓励生成器利用自身的生成先验来“填补”细节。例如,当VLM对多米诺骨牌倒塌的方向不太确定时,低置信度区域容许生成模型根据对物理模拟的隐式理解来决定更自然的倒向。 这种设计平衡了外部规划和内部先验,避免了在模糊区域出现刚性的“轨迹复制”导致的伪影。论文通过图3的定性比较展示了优势:在“使用工具”场景中,用户只画了人手移动的粗略轨迹,MotiMotion正确生成了工具和物体的互动(如锤子敲击钉子),而对比方法(MagicMotion、Wan-Move以及去掉推理器的消融版)要么遗漏了工具-物体交互,要么产生了违反物理的位移。
实验:设置、指标与结果
实验基准:MotiBench
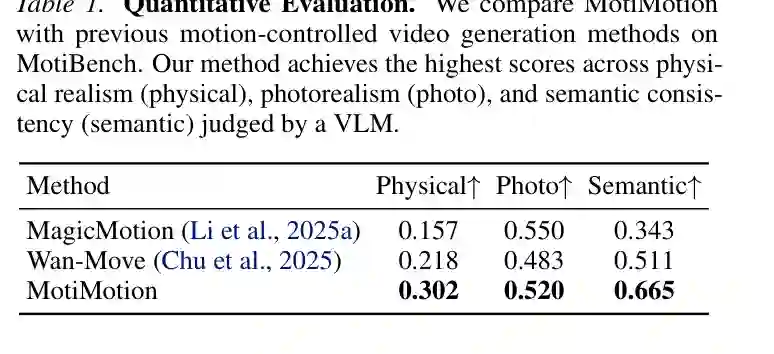
为了系统评估模型对交互中心和因果推理场景的生成能力,论文构建了一个新的基准数据集MotiBench。与现有运动控制基准(如点跟踪数据集)不同,MotiBench专门聚焦于交互中心场景——即运动触发新事件(如碰撞、连接、工具使用、机制变化)。数据集包含多个类别:碰撞(Collision)、约束变化(Constraint Change)、流动(Flow)、工具机制(Tool Mechanism)、常见物体(Common Objects)等。每一条样本包含一张起始图像、用户提供的轨迹(稀疏且不精确)以及文本提示。MotiBench的设计目的是检验模型能否理解隐含的因果链并生成合理的后续。 根据原文,MotiBench包含62张pre-event图像:每张图像都处在事件即将发生但尚未发生的状态,例如支撑物即将被移走、门闩即将释放、流体即将被吹动或工具即将触发机械反应。这种设定刻意避免把完整运动结果直接暴露给模型,迫使模型从静态视觉结构、粗略轨迹和提示中推断后续动态。因此,MotiBench不是单纯衡量轨迹跟随误差,而是衡量模型能否理解“轨迹背后的因果后果”。
评估指标
论文采用两类互补评估方式,并将自动评测与人工偏好研究结合起来:
- VLM自动评估:使用一个独立的高性能VLM(与推理器不同)作为评判者,对生成的视频进行多项指标打分,包括“物体行为合理性”“交互自然性”“轨迹跟随精度”“物理一致性”等。VLM根据视频帧序列输出1-5的评分。这种方式可大规模重复,减少人工偏倚。
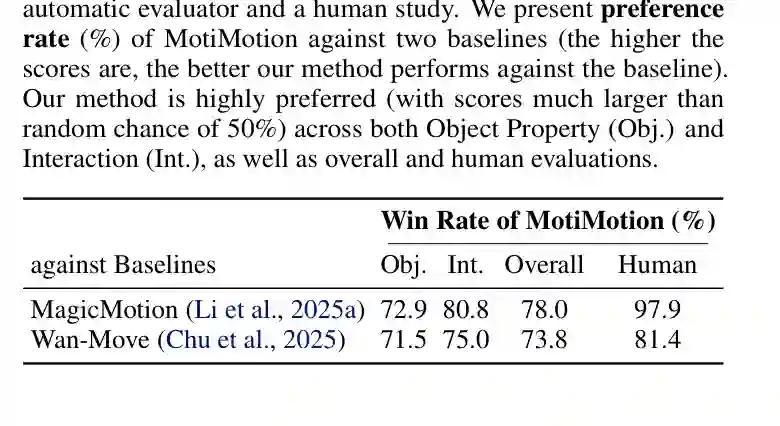
- 人类研究:招募标注者对MotiMotion与对比方法的生成视频进行偏好比较。标注者被展示同一提示下的两个视频,要求选择“更合理、更自然”的一个。研究采用成对比较设计,收集了多个场景的偏好率。
主要结果

消融与分析
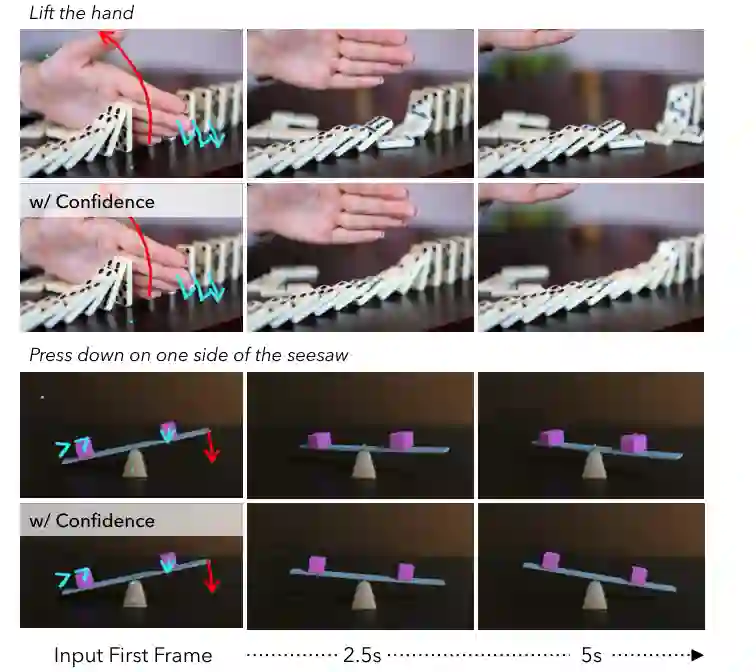

结论:贡献、局限与启发
主要贡献
- 提出了推理-生成框架:将运动控制从字面跟随提升为因果推理后生成,在运动可控视频生成中引入VLM规划阶段,推理器本身无需训练,并可与现有轨迹控制视频生成后端结合。
- 置信度感知控制:根据轨迹置信度动态调节引导强度,平衡了外部规划和内部先验,提升了运动自然度。
- 新基准MotiBench:填补了交互中心场景评估的空白,为后续研究提供了标准测试床。
- 显著性能提升:在MotiBench上,MotiMotion通过VLM评估和人类研究均优于现有方法,特别是在物理合理性和因果一致性方面。
局限性
原文未明确说明局限性。根据论文内容可推测,其局限性可能包括:依赖VLM的推理质量(若VLM对特定场景理解有误,则规划阶段可能引入错误);推理阶段增加计算开销(但论文强调训练无关的开销有限);以及当前框架仅针对单个物体或简单交互,复杂多物体动态场景可能仍需进一步测试。但原文未明确提及,故不予添加。
启发
MotiMotion的工作启示了我们:视频生成中的控制不应止步于信号跟随,而应更多利用多模态大模型的推理能力。其“规划-生成”两阶段范式、置信度感知的融合方式,可推广到其他条件控制任务(如基于文本的时序控制、基于布局的生成)。此外,MotiBench的构建思路——聚焦交互中心场景——也提醒社区当前的基准评估需要更关注因果关系而非纯粹视觉相似性。未来工作可探索:更复杂的多步骤因果推理、VLM与扩散模型的端到端联合优化、以及开放世界条件下的物理模拟能力。