

尽管训练范式正在快速演进,大型视觉—语言模型(LVLM)的解码器骨干仍在根本上植根于残差连接 Transformer 架构。因此,解析其内部模块的不同作用,对于理解模型机制并指导架构优化至关重要。尽管以往的统计方法已经提供了有价值的基于归因的洞见,但它们往往缺乏统一的理论基础。为弥合这一差距,我们提出了一个基于信息论与几何学的统一框架,用以量化残差更新的几何性质与熵特征。将该统一框架应用于 LVLM 后,我们揭示了一种根本性的功能解耦:注意力充当一种保持子空间的算子,侧重于重配置;而前馈网络(FFN)则作为扩展子空间的算子,驱动语义创新。值得注意的是,进一步实验表明,将学习得到的注意力权重替换为预定义取值(例如高斯噪声),在大多数数据集上相较于原始模型能够取得相当甚至更优的性能。这些结果暴露出当前机制中严重的资源错配与冗余,表明最先进的 LVLM 实际上是在“注意力中迷失”,而非高效利用视觉上下文。我们的代码已在此链接公开。
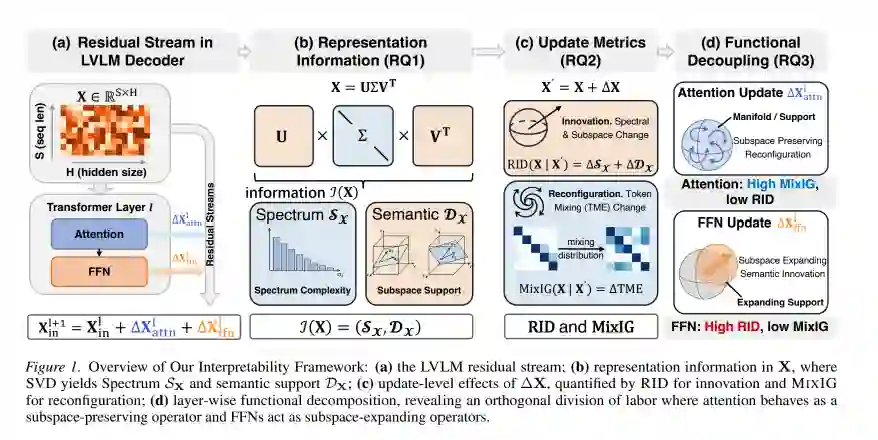
大型视觉—语言模型(LVLM)通过将基于 Transformer 的序列建模扩展到对自然语言与视觉信号的联合处理,已从大型语言模型(LLM)迅速演进而来(Vaswani et al., 2017)。早期的视觉—语言表征学习(例如对比式预训练)建立了强大的图像—文本对齐能力,使后续 LVLM 能够将其作为视觉 grounding 接口加以利用(Radford et al., 2021)。随后,LVLM 越来越多地将预训练视觉编码器与 LLM 骨干统一起来,从而在大规模条件下实现少样本多模态泛化与指令跟随行为(Alayrac et al., 2022; Li et al., 2023a; Liu et al., 2023; Hao et al., 2025)。与此同时,面向推理的范式进一步赋予这些模型更强的审慎思考与问题求解行为(Wei et al., 2022; Jaech et al., 2024; Guo et al., 2025; Zhang et al., 2025b; Tan et al., 2025)。尽管架构与训练创新发展迅速,主流 LVLM 家族在根本上仍然建立在 Transformer 架构之上(Vaswani et al., 2017)。 从可解释性视角来看,标准 Transformer 层由两个核心子模块组成,即多头自注意力与前馈网络(FFN);每个子模块都由残差连接包裹,因此每个子模块都会产生一个加性更新,并将其写回共享的残差流表征中(Vaswani et al., 2017; Elhage et al., 2021; Skean et al., 2025)。一种常见的工作假设认为,注意力模块是在上下文推理的主要承载结构,可实现依赖上下文的算法,例如归纳/复制型机制(Olsson et al., 2022)。相比之下,FFN 通常被刻画为用于存储和检索分布式关联,表现得类似键—值记忆,其被激活的模式能够诱导出类似浅层 n-gram 延续的下一词元分布(Geva et al., 2021; Edelman et al., 2024)。 为探究这一模块化假设,注意力可解释性研究主要采取统计视角,即将注意力相关信号视为可测量的代理变量,并通过经验分布(Zhou et al., 2024; Kahardipraja et al., 2025)、相关性(Jain & Wallace, 2019; Abnar & Zuidema, 2020)以及受控干预(Serrano & Smith, 2019; Nam et al., 2025)来归因其功能。近来,这一统计工具箱进一步扩展到 LVLM 解码器中的视觉注意力分析,其中注意力将文本与视觉词元连接起来。经验分析揭示了视觉注意力汇聚(visual attention sink)(Kang et al., 2025)和视觉注意力漂移(visual attention drift)(Liu et al., 2025; Guan et al., 2026)等系统性现象,这些现象共同表明,模型往往未能向真正有信息量的视觉证据分配足够的注意力。尽管已有这些进展,LVLM 的模块级可解释性仍然缺乏一个统一的信息论与几何框架,来刻画并显式对比不同子模块在多模态设置下如何贡献于表征结构。相比之下,LLM 表征分析文献已经利用这类视角来评估不同深度上的表征质量(Razzhigaev et al., 2024; Wei et al., 2024),并研究联合动态过程(Skean et al., 2025; Tian et al., 2023)。这一空白促使我们将这些原则性视角引入 LVLM 分析,以弥补缺失的研究维度,并支持模块特定且模态有根基的比较。 为弥合这一理论空白,我们提出了一个基于信息论与微分几何的统一框架,用于量化并对比 LVLM 残差流计算中模块级功能贡献。通过在表征空间中采用流形假设(Bengio et al., 2013),我们引入两个互补指标:表征信息差异(Representation Information Discrepancy, RID)与混合信息增益(Mixing Information Gain, MixIG)。这些指标将残差更新的贡献分解为两种不同的几何效应:创新(innovation)与重配置(reconfiguration)。其中,创新量化外部信息注入,即语义子空间扩展或谱复杂度改变;重配置则度量已有支撑集内信息的熵式重新分布。我们在涵盖三种主流架构的 15 个最先进 LVLM 上,基于广泛的多模态基准开展了大量实验。我们的分析揭示了两项深刻洞见:首先,我们定量验证了 Transformer 残差流计算中一种鲜明的功能解耦:注意力主要执行熵式重配置,并保持既有表征支撑;而 FFN 则通过引入新的语义方向主导创新。基于这种分工,我们进一步诊断出当前 LVLM 中一种系统性病理:解码器视觉注意力往往无法围绕与问题相关的视觉证据执行有意义的混合,而是表现出显著冗余,经常迷失于对信息性更新贡献有限的交互模式之中。 我们的主要贡献总结如下: • 理论框架:我们提出了一种基于流形假设的严格形式化方法,用于定义表征信息。我们引入 RID 与 MixIG 作为一组对偶指标,以量化残差更新的几何影响与熵影响,从而提供一种用于探测表征动态的通用工具。 • 模块级可解释性:我们对 Transformer 块内部不同角色给出了定量解释。我们证明,注意力与 FFN 运行于正交机制之中——分别对应重配置与创新——从而以几何证据支撑了模块化假设。 • 经验诊断:我们揭示了 LVLM 设计中的关键低效性。我们的结果强调,尽管架构不断扩展,当前模型在视觉处理过程中仍存在严重的信息冗余,这表明视觉词元的整合往往计算代价高昂,却在信息层面较为稀疏。
