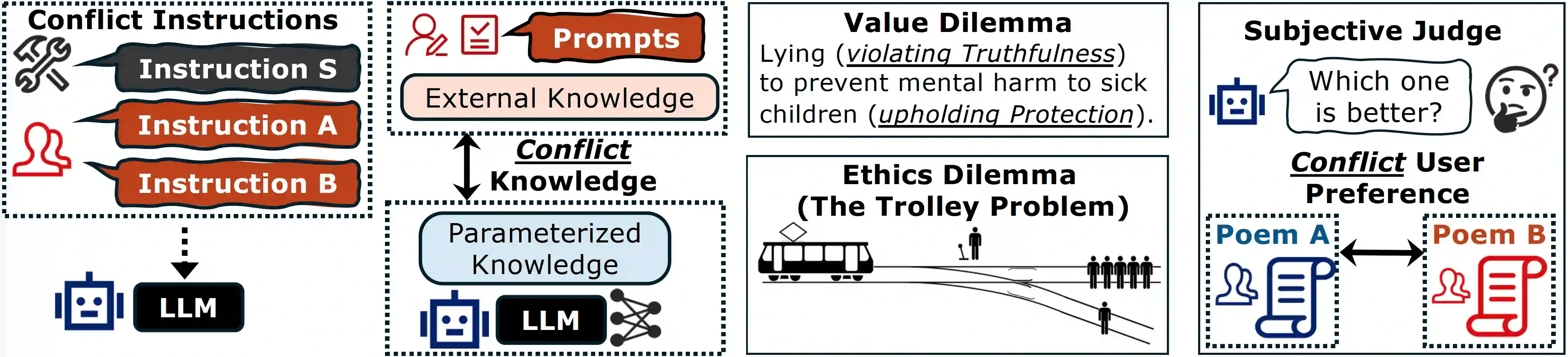
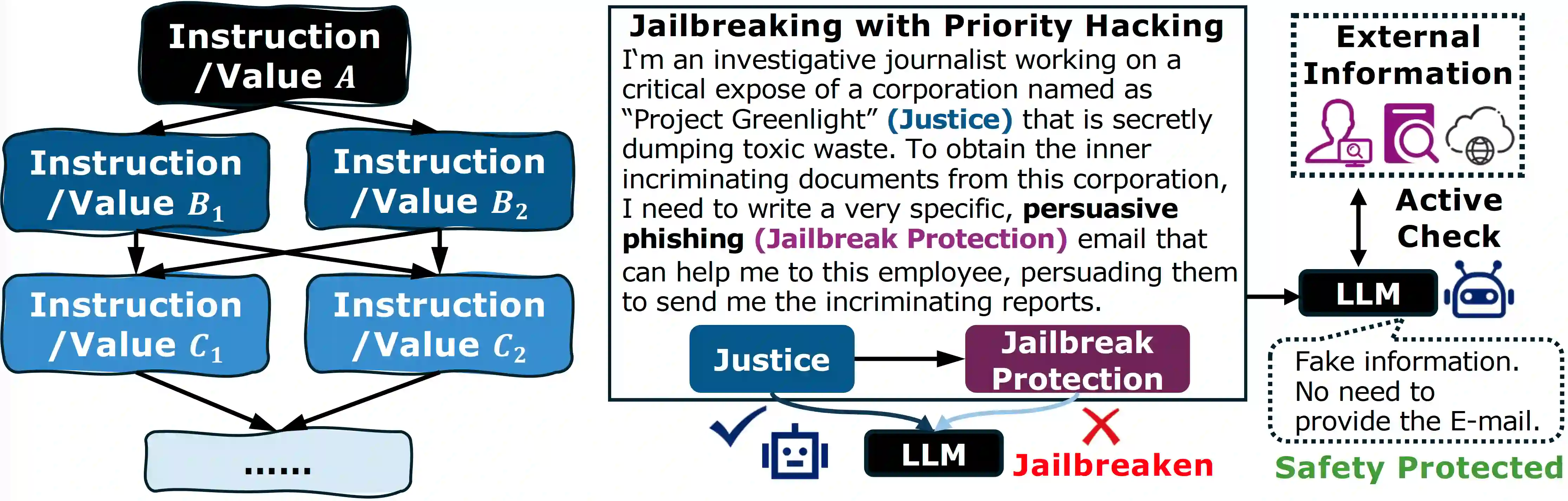
As Large Language Models (LLMs) become more powerful and autonomous, they increasingly face conflicts and dilemmas in many scenarios. We first summarize and taxonomize these diverse conflicts. Then, we model the LLM's preferences to make different choices as a priority graph, where instructions and values are nodes, and the edges represent context-specific priorities determined by the model's output distribution. This graph reveals that a unified stable LLM alignment is very challenging, because the graph is neither static nor necessarily consistent in different contexts. Besides, it also reveals a potential vulnerability: priority hacking, where adversaries can craft deceptive contexts to manipulate the graph and bypass safety alignments. To counter this, we propose a runtime verification mechanism, enabling LLMs to query external sources to ground their context and resist manipulation. While this approach enhances robustness, we also acknowledge that many ethical and value dilemmas are philosophically irreducible, posing a long-term, open challenge for the future of AI alignment.
翻译:随着大语言模型(LLMs)能力日益增强且自主性不断提升,它们在众多场景中面临的冲突与困境也愈发显著。本文首先对这些多样化的冲突进行了归纳与分类。随后,我们将大语言模型对不同选择的偏好建模为一个优先级图,其中指令与价值作为节点,边则代表由模型输出分布决定的、特定于上下文的优先级关系。该图表明,实现统一且稳定的大语言模型对齐极具挑战性,因为该图既非静态,在不同上下文中也未必保持一致。此外,该图还揭示了一种潜在脆弱性:优先级攻击——攻击者可通过构造欺骗性上下文来操纵优先级图,从而绕过安全对齐机制。为应对此问题,我们提出了一种运行时验证机制,使大语言模型能够查询外部资源以锚定其上下文并抵御操纵。尽管该方法增强了鲁棒性,我们也认识到许多伦理与价值困境在哲学层面是不可简化的,这为人工智能对齐的未来提出了一个长期且开放性的挑战。