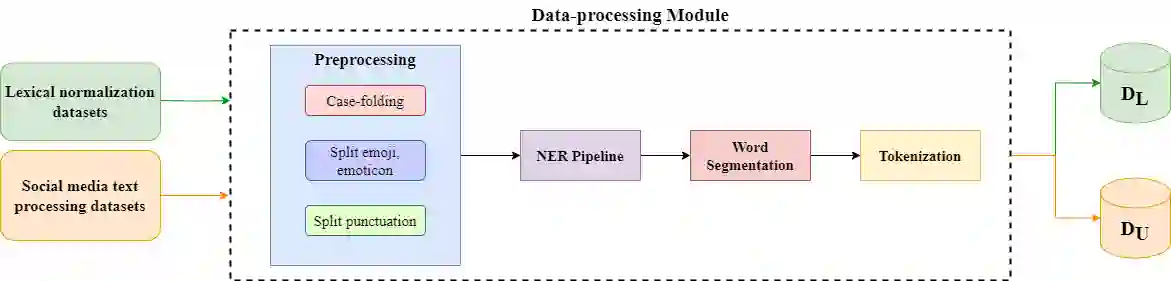
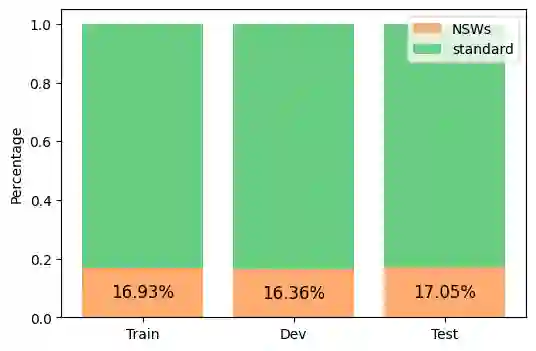
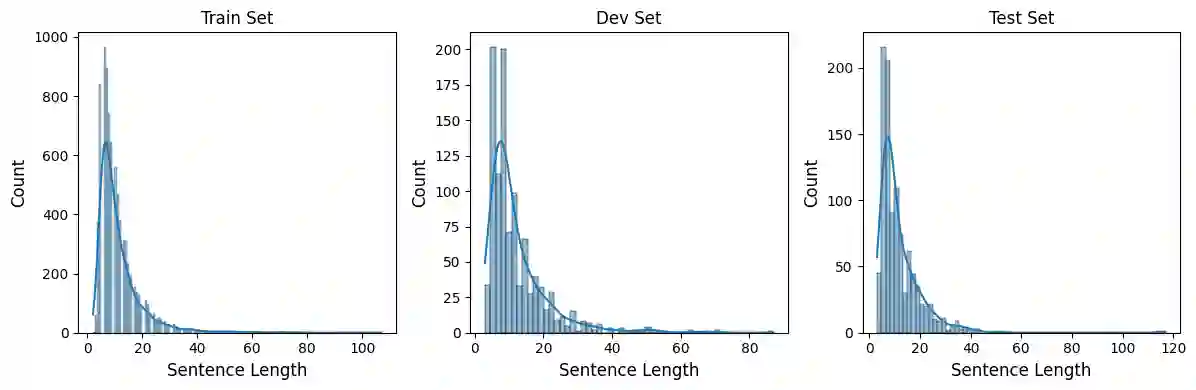
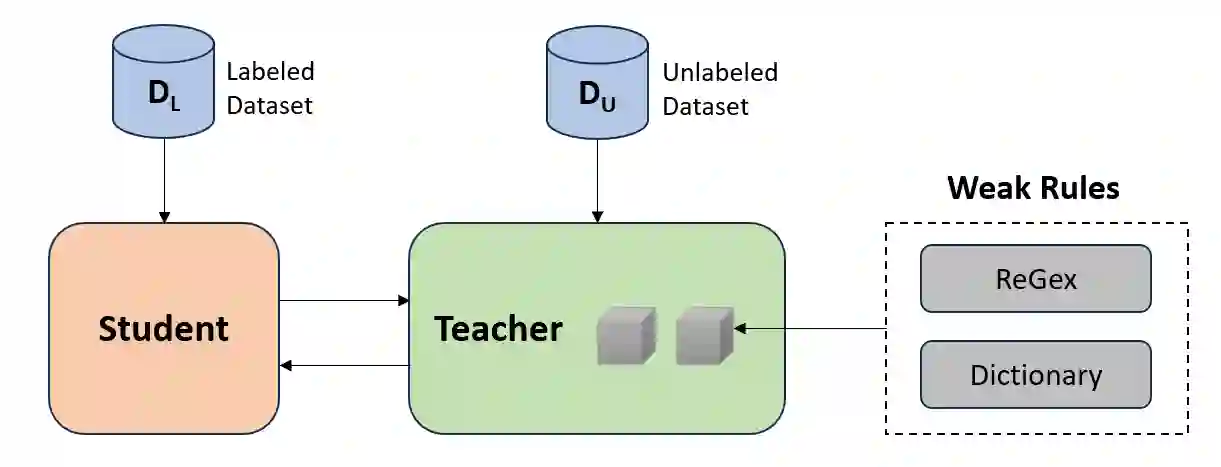
This study introduces an innovative automatic labeling framework to address the challenges of lexical normalization in social media texts for low-resource languages like Vietnamese. Social media data is rich and diverse, but the evolving and varied language used in these contexts makes manual labeling labor-intensive and expensive. To tackle these issues, we propose a framework that integrates semi-supervised learning with weak supervision techniques. This approach enhances the quality of training dataset and expands its size while minimizing manual labeling efforts. Our framework automatically labels raw data, converting non-standard vocabulary into standardized forms, thereby improving the accuracy and consistency of the training data. Experimental results demonstrate the effectiveness of our weak supervision framework in normalizing Vietnamese text, especially when utilizing Pre-trained Language Models. The proposed framework achieves an impressive F1-score of 82.72% and maintains vocabulary integrity with an accuracy of up to 99.22%. Additionally, it effectively handles undiacritized text under various conditions. This framework significantly enhances natural language normalization quality and improves the accuracy of various NLP tasks, leading to an average accuracy increase of 1-3%.
翻译:本研究提出了一种创新的自动标注框架,以解决越南语等低资源语言在社交媒体文本中的词汇规范化挑战。社交媒体数据丰富多样,但其语境中不断演变且多变的语言使得人工标注劳动密集且成本高昂。为解决这些问题,我们提出了一个将半监督学习与弱监督技术相结合的框架。该方法在最小化人工标注工作量的同时,提升了训练数据集的质量并扩展了其规模。我们的框架能自动标注原始数据,将非标准词汇转换为标准化形式,从而提高训练数据的准确性和一致性。实验结果表明,我们的弱监督框架在越南语文本规范化方面具有显著效果,尤其是在利用预训练语言模型时。所提出的框架取得了82.72%的优异F1分数,并保持了高达99.22%的词汇完整性准确率。此外,该框架能有效处理各种条件下的无音调标记文本。本框架显著提升了自然语言规范化的质量,并提高了多种自然语言处理任务的准确性,平均准确率提升了1-3%。