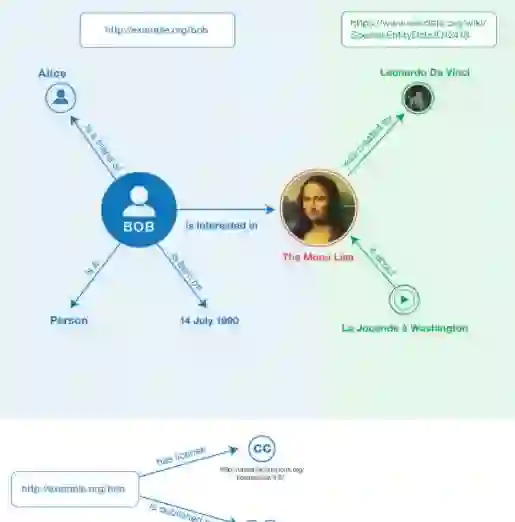
This paper addresses the harmonization of metadata from diverse repositories of language resources (LRs). Leveraging linked data and RDF techniques, we integrate data from multiple sources into a unified model based on DCAT and META-SHARE OWL ontology. Our methodology supports text-based search, faceted browsing, and advanced SPARQL queries through Linghub, a newly developed portal. Real user queries from the Corpora Mailing List (CML) were evaluated to assess Linghub capability to satisfy actual user needs. Results indicate that while some limitations persist, many user requests can be successfully addressed. The study highlights significant metadata issues and advocates for adherence to open vocabularies and standards to enhance metadata harmonization. This initial research underscores the importance of API-based access to LRs, promoting machine usability and data subset extraction for specific purposes, paving the way for more efficient and standardized LR utilization.
翻译:本文针对来自不同语言资源(LR)存储库的元数据协调问题展开研究。利用关联数据与RDF技术,我们将多源数据整合至基于DCAT和META-SHARE OWL本体的统一模型中。通过新开发的Linghub门户平台,我们的方法支持基于文本的检索、分面浏览及高级SPARQL查询。研究通过评估语料库邮件列表(CML)中的真实用户查询,检验了Linghub满足实际用户需求的能力。结果表明,虽然存在部分局限性,但多数用户请求能成功获得响应。本研究揭示了当前元数据存在的显著问题,倡导遵循开放词汇表与标准以提升元数据协调性。这项初步研究强调了基于API访问语言资源的重要性,通过促进机器可操作性及面向特定目的的数据子集提取,为更高效、标准化的语言资源利用铺平道路。