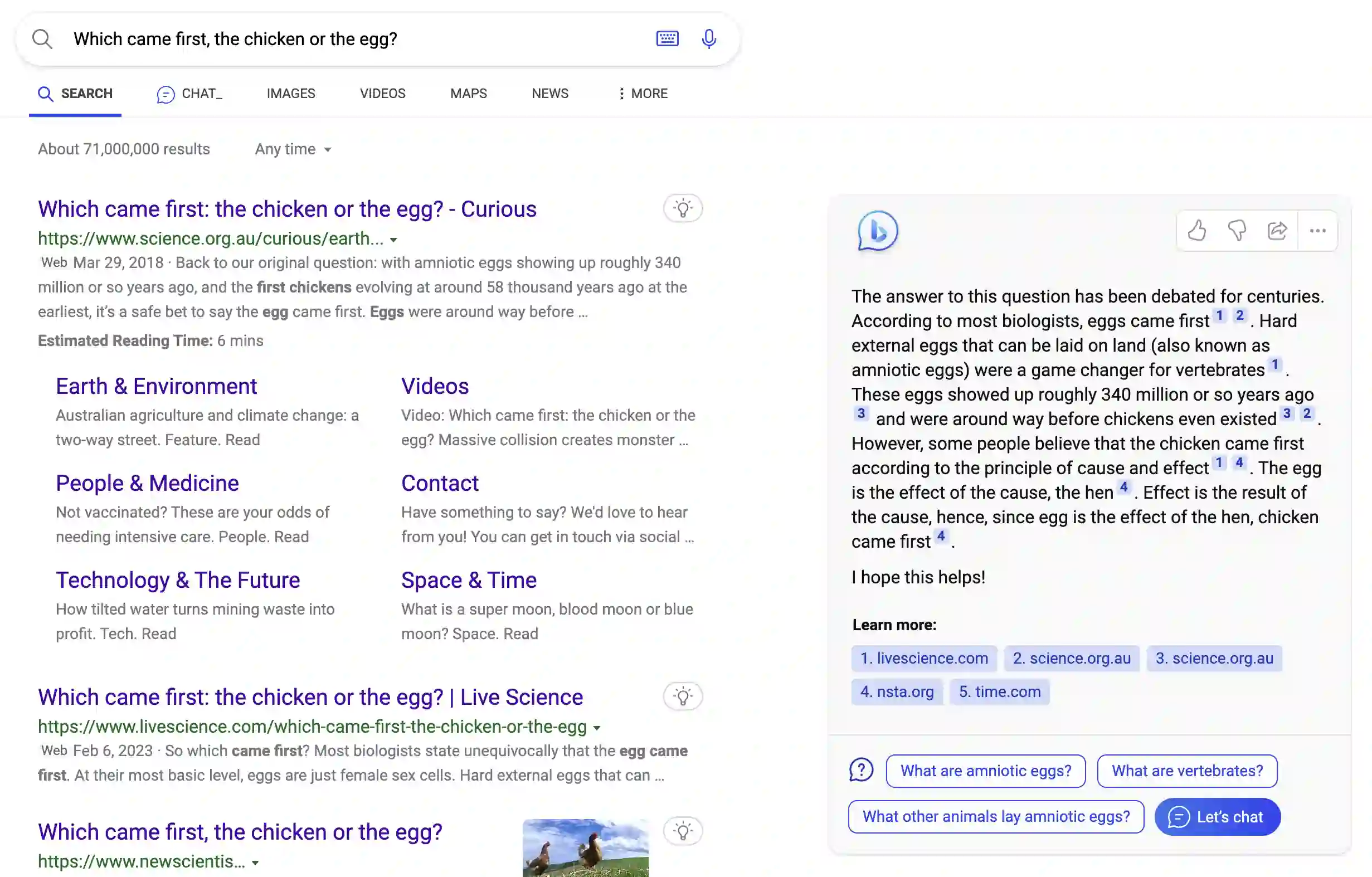
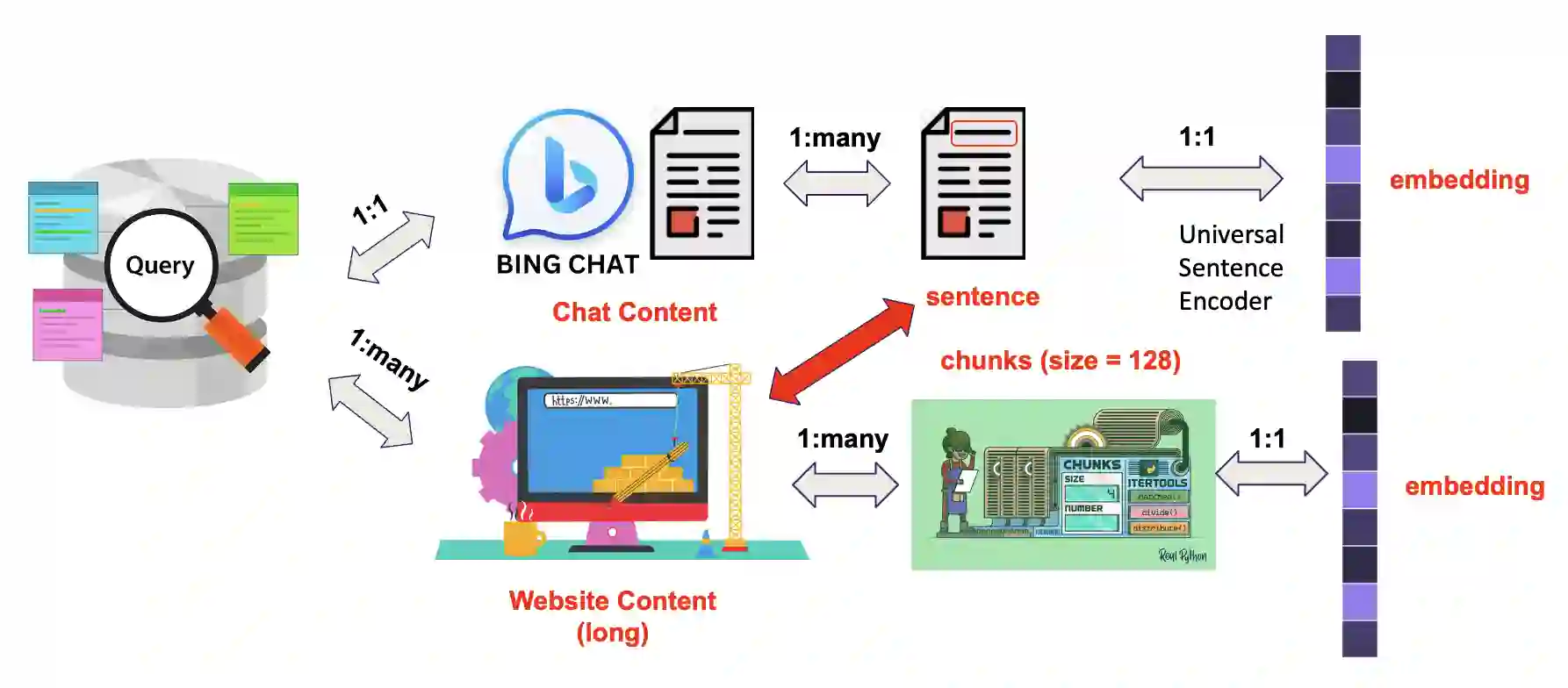
In the domain of digital information dissemination, search engines act as pivotal conduits linking information seekers with providers. The advent of chat-based search engines utilizing Large Language Models (LLMs) and Retrieval Augmented Generation (RAG), exemplified by Bing Chat, marks an evolutionary leap in the search ecosystem. They demonstrate metacognitive abilities in interpreting web information and crafting responses with human-like understanding and creativity. Nonetheless, the intricate nature of LLMs renders their "cognitive" processes opaque, challenging even their designers' understanding. This research aims to dissect the mechanisms through which an LLM-powered chat-based search engine, specifically Bing Chat, selects information sources for its responses. To this end, an extensive dataset has been compiled through engagements with New Bing, documenting the websites it cites alongside those listed by the conventional search engine. Employing natural language processing (NLP) techniques, the research reveals that Bing Chat exhibits a preference for content that is not only readable and formally structured, but also demonstrates lower perplexity levels, indicating a unique inclination towards text that is predictable by the underlying LLM. Further enriching our analysis, we procure an additional dataset through interactions with the GPT-4 based knowledge retrieval API, unveiling a congruent text preference between the RAG API and Bing Chat. This consensus suggests that these text preferences intrinsically emerge from the underlying language models, rather than being explicitly crafted by Bing Chat's developers. Moreover, our investigation documents a greater similarity among websites cited by RAG technologies compared to those ranked highest by conventional search engines.
翻译:在数字信息传播领域,搜索引擎作为连接信息寻求者与提供者的关键枢纽。基于大语言模型(LLM)和检索增强生成(RAG)的聊天式搜索引擎(以Bing Chat为例)的出现,标志着搜索生态系统的演进飞跃。它们在解读网络信息、构建具有类人理解和创造力的响应时展现出元认知能力。然而,LLM的复杂性使其“认知”过程不透明,甚至挑战了设计者的理解。本研究旨在剖析由LLM驱动的聊天式搜索引擎(具体为Bing Chat)为其响应选择信息源的机制。为此,我们通过与新必应互动编制了大规模数据集,记录了其引用的网站以及传统搜索引擎列出的网站。运用自然语言处理(NLP)技术,研究发现Bing Chat偏好内容不仅可读性高、结构规范,而且具有较低困惑度,这表明其对底层LLM可预测文本具有独特倾向。为进一步丰富分析,我们通过与基于GPT-4的知识检索API互动获取额外数据集,揭示RAG API与Bing Chat之间存在一致的文本偏好。这一共识表明,这些文本偏好本质上源于底层语言模型,而非Bing Chat开发者的刻意设计。此外,我们的研究记录显示,与常规搜索引擎排名最高的网站相比,RAG技术引用的网站之间具有更高的相似性。