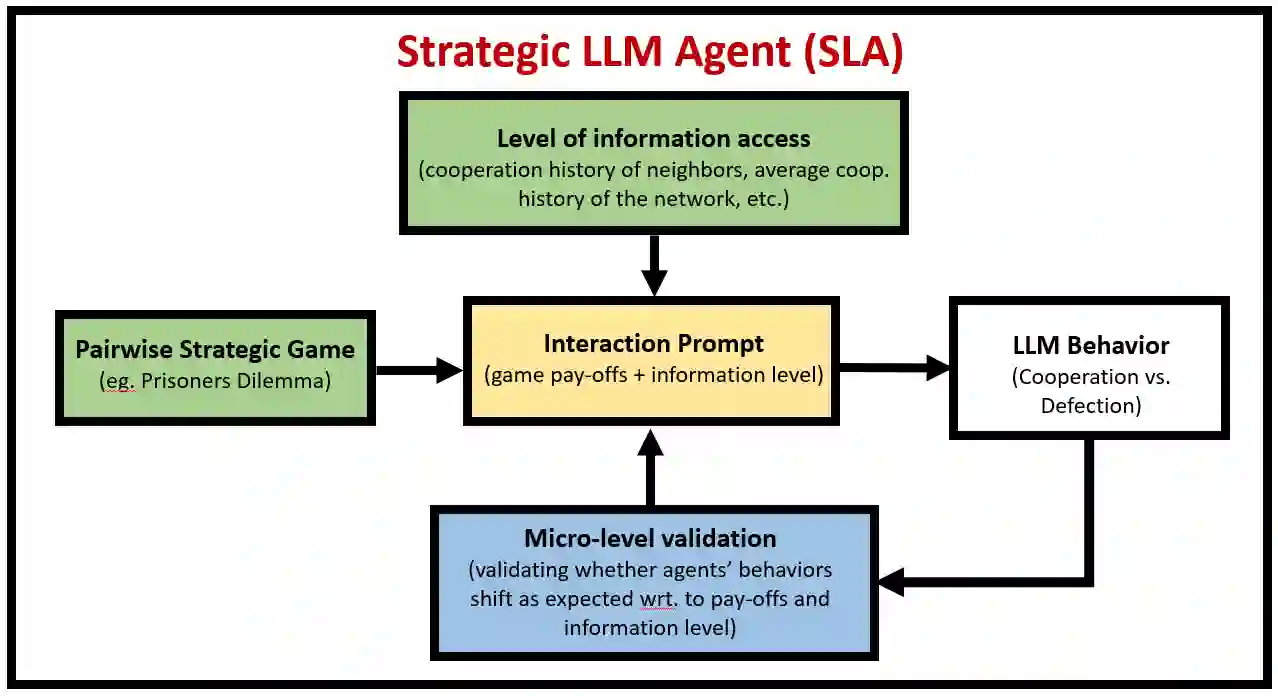
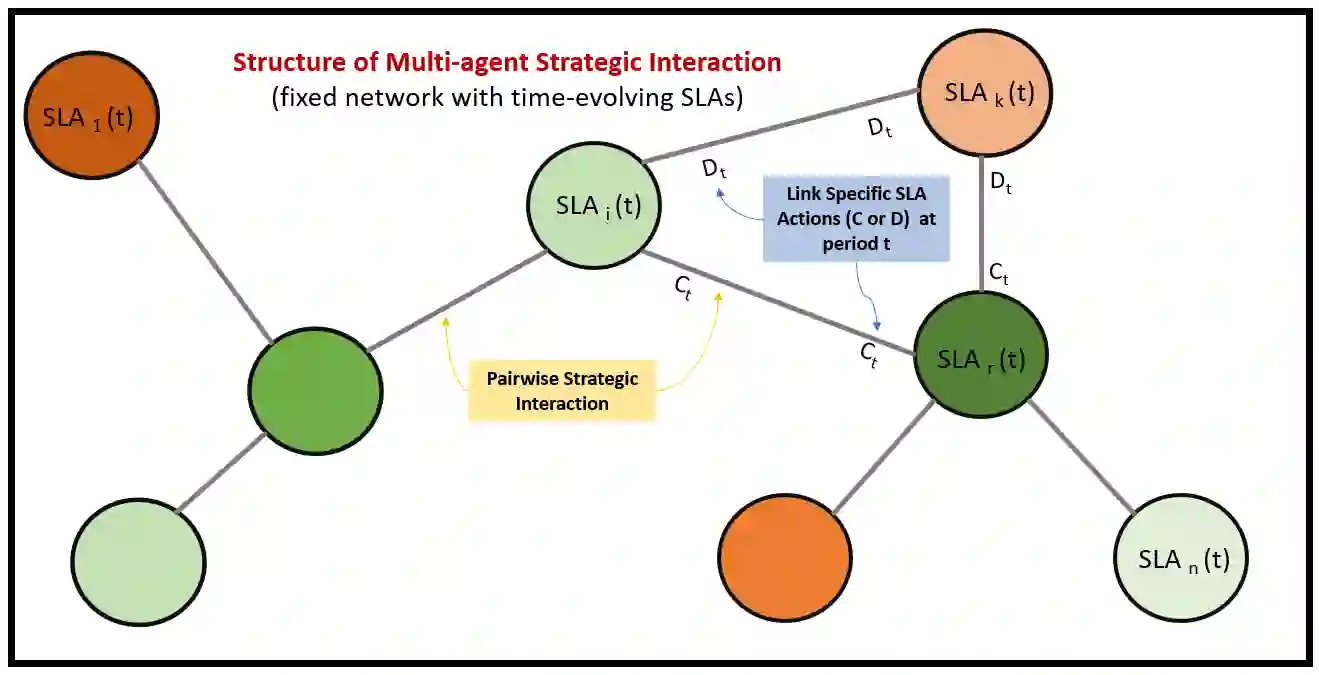
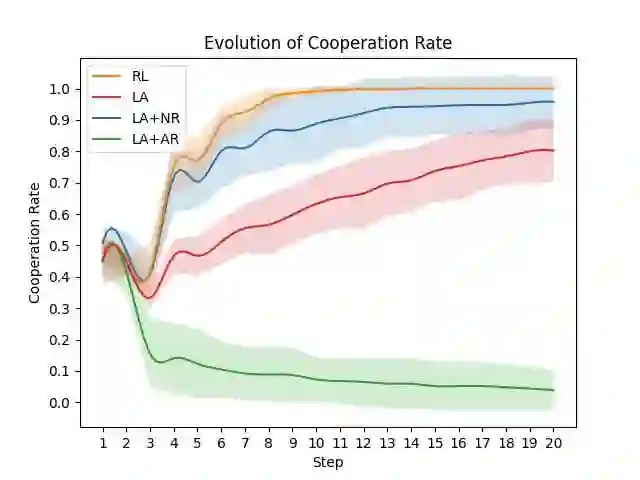
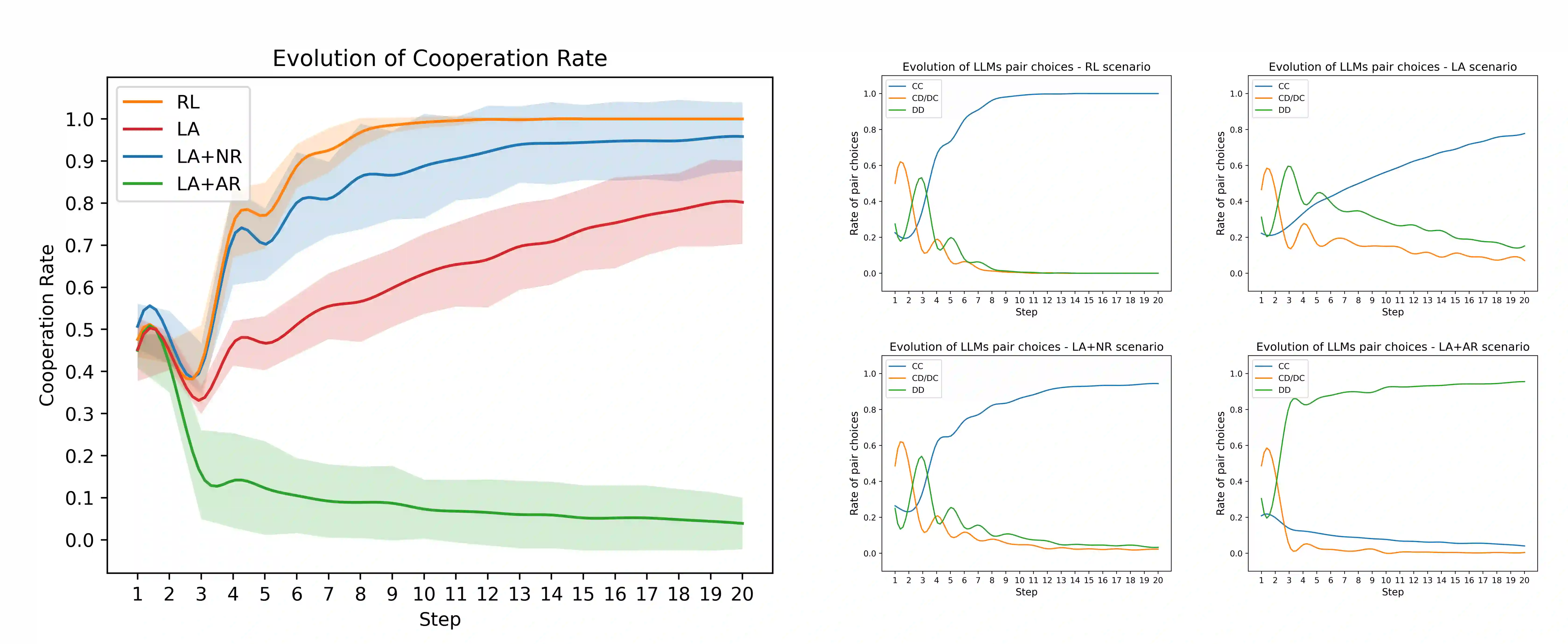
This paper introduces a novel framework combining LLM agents as proxies for human strategic behavior with reinforcement learning (RL) to engage these agents in evolving strategic interactions within team environments. Our approach extends traditional agent-based simulations by using strategic LLM agents (SLA) and introducing dynamic and adaptive governance through a pro-social promoting RL agent (PPA) that modulates information access across agents in a network, optimizing social welfare and promoting pro-social behavior. Through validation in iterative games, including the prisoner dilemma, we demonstrate that SLA agents exhibit nuanced strategic adaptations. The PPA agent effectively learns to adjust information transparency, resulting in enhanced cooperation rates. This framework offers significant insights into AI-mediated social dynamics, contributing to the deployment of AI in real-world team settings.
翻译:本文提出了一种创新框架,该框架将作为人类策略行为代理的大型语言模型(LLM)智能体与强化学习(RL)相结合,使这些智能体能够在团队环境中参与不断演化的策略互动。我们的方法通过使用策略性LLM智能体(SLA),并引入一个具有亲社会促进作用的RL智能体(PPA)来实现动态自适应的治理机制,从而扩展了传统的基于智能体的模拟。PPA智能体通过调节网络中智能体间的信息访问权限,优化社会福利并促进亲社会行为。通过在包括囚徒困境在内的迭代博弈中进行验证,我们证明了SLA智能体展现出细致入微的策略适应能力。PPA智能体能够有效地学习调整信息透明度,从而显著提升合作率。该框架为理解AI介导的社会动态提供了重要见解,有助于AI在现实世界团队环境中的部署。