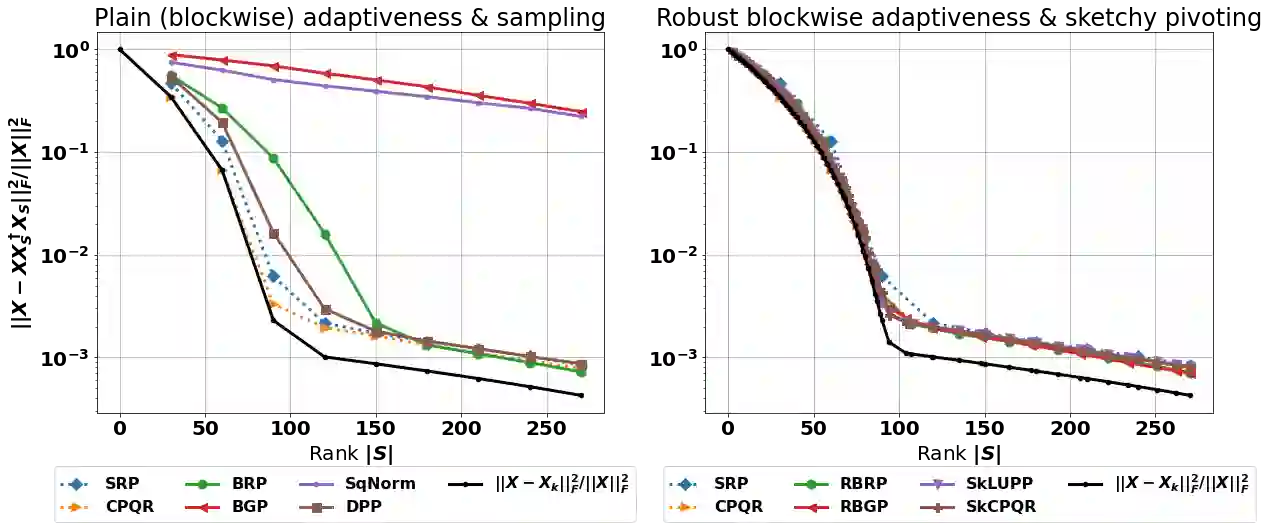
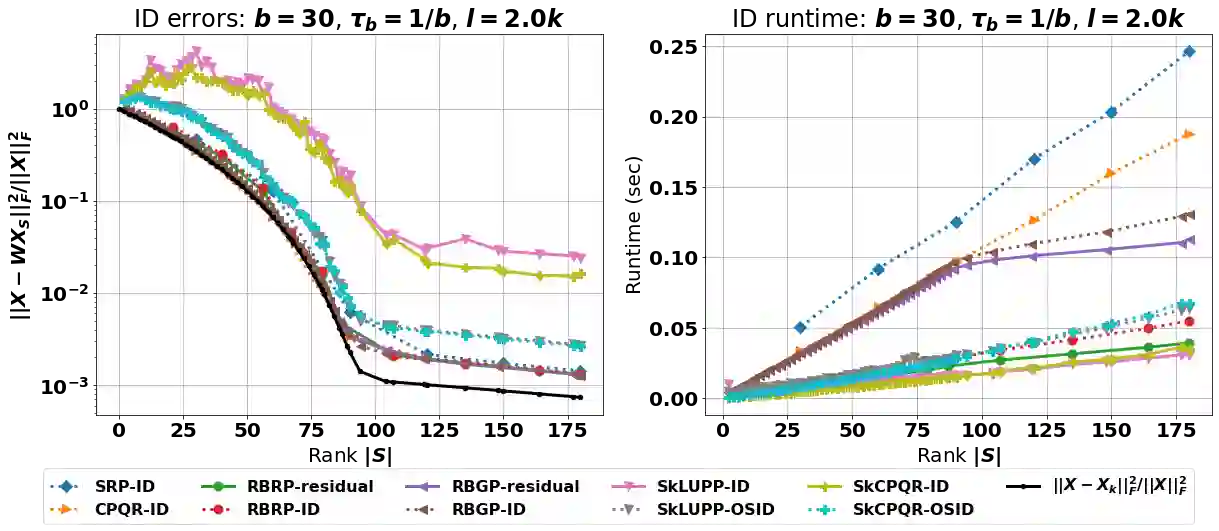
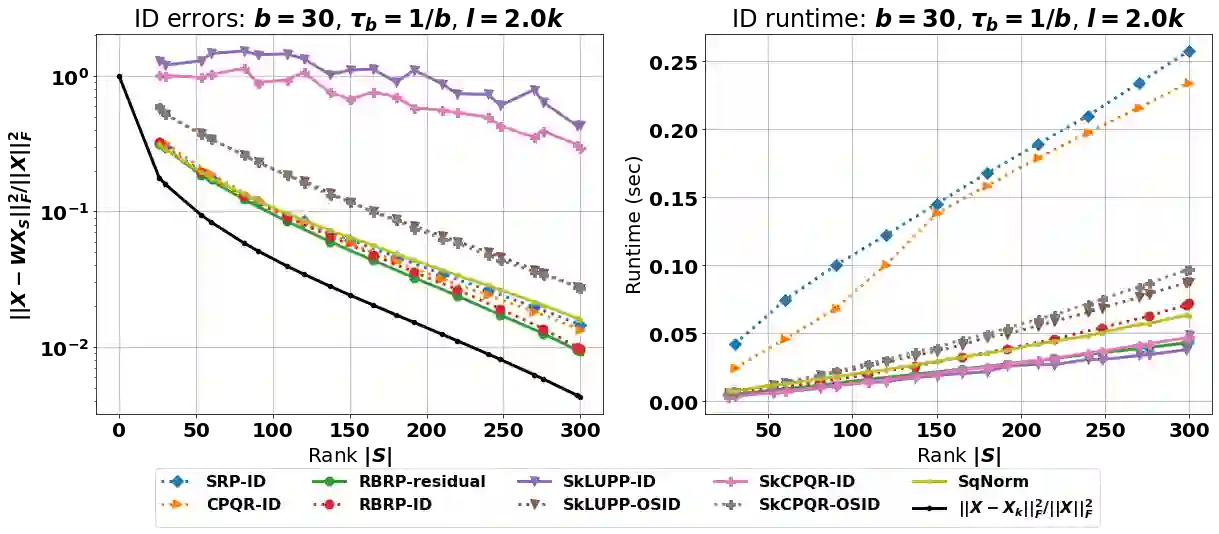
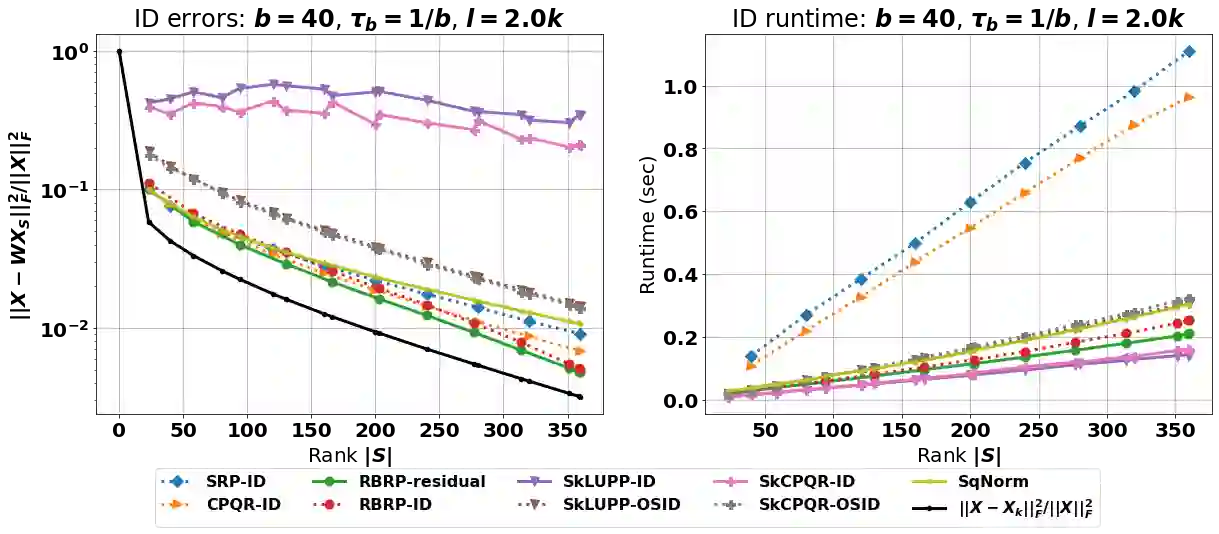
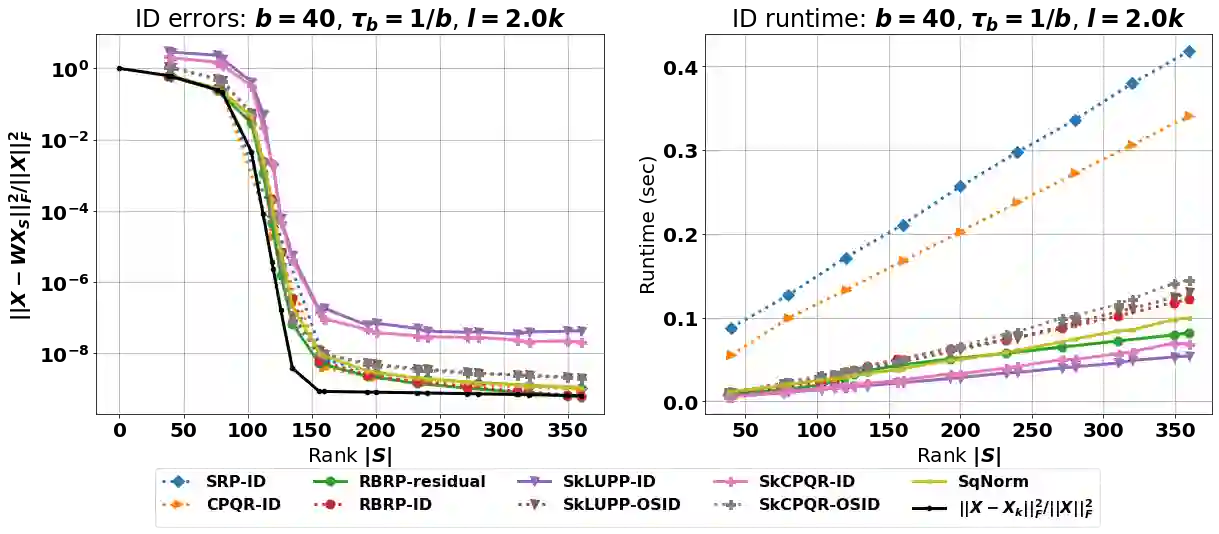
The interpolative decomposition (ID) aims to construct a low-rank approximation formed by a basis consisting of row/column skeletons in the original matrix and a corresponding interpolation matrix. This work explores fast and accurate ID algorithms from five essential perspectives for empirical performance: (a) skeleton complexity that measures the minimum possible ID rank for a given low-rank approximation error, (b) asymptotic complexity in FLOPs, (c) parallelizability of the computational bottleneck as matrix-matrix multiplications, (d) error-revealing property that enables automatic rank detection for given error tolerances without prior knowledge of target ranks, (e) ID-revealing property that ensures efficient construction of the optimal interpolation matrix after selecting the skeletons. While a broad spectrum of algorithms have been developed to optimize parts of the aforementioned perspectives, practical ID algorithms proficient in all perspectives remain absent. To fill in the gap, we introduce robust blockwise random pivoting (RBRP) that is parallelizable, error-revealing, and exact-ID-revealing, with comparable skeleton and asymptotic complexities to the best existing ID algorithms in practice. Through extensive numerical experiments on various synthetic and natural datasets, we empirically demonstrate the appealing performance of RBRP from the five perspectives above, as well as the robustness of RBRP to adversarial inputs.
翻译:插值分解旨在构建由原始矩阵中的行/列骨架基和相应插值矩阵构成的低秩近似。本文从经验性能的五个关键角度探索快速且精确的插值分解算法:(a)骨架复杂度,度量给定低秩近似误差下可实现的最小插值分解秩;(b)浮点运算次数下的渐进复杂度;(c)以矩阵乘法作为计算瓶颈的可并行性;(d)误差揭示特性,能够在无需预先知晓目标秩的情况下,针对给定误差容限自动检测秩;(e)插值分解揭示特性,确保在选择骨架后高效构建最优插值矩阵。尽管已有大量算法针对上述部分角度进行优化,但能够全面兼顾所有角度的实用插值分解算法仍然缺失。为填补这一空白,我们提出鲁棒分块随机主元选取——该算法兼具可并行性、误差揭示与精确插值分解揭示特性,其骨架复杂度与渐进复杂度均能与实践中现有的最优插值分解算法相媲美。通过在多种合成与自然数据集上的大量数值实验,我们从上述五个角度实证展示了RBRP算法的优异性能,以及其对对抗性输入数据的鲁棒性。