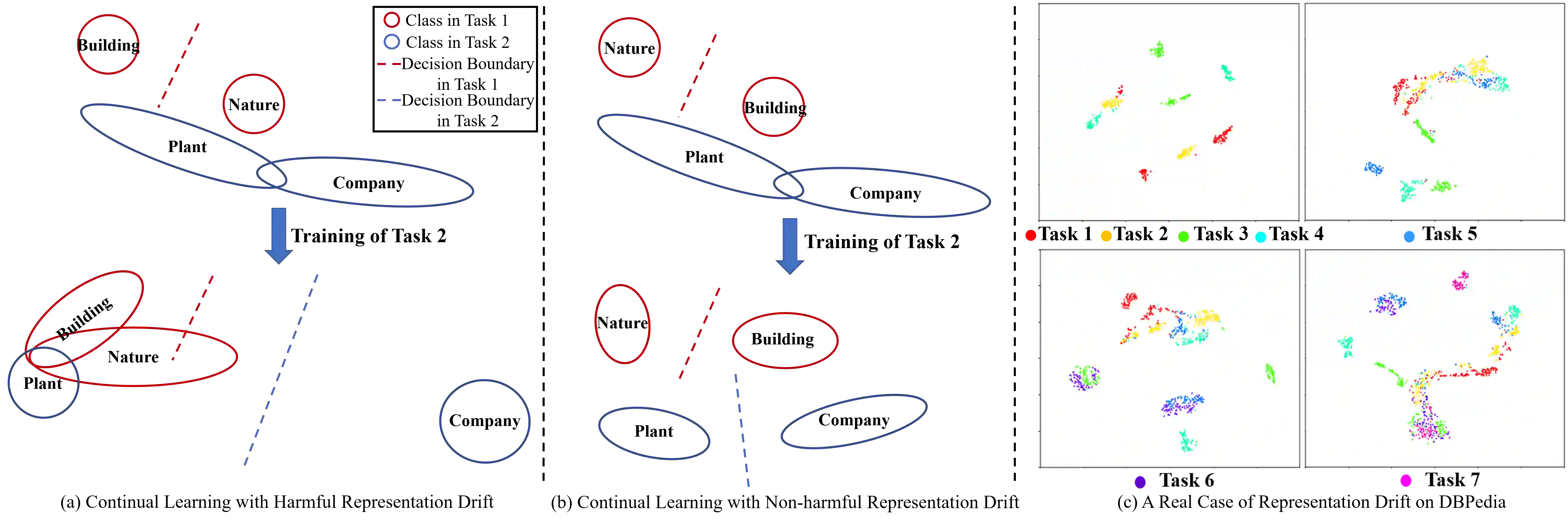
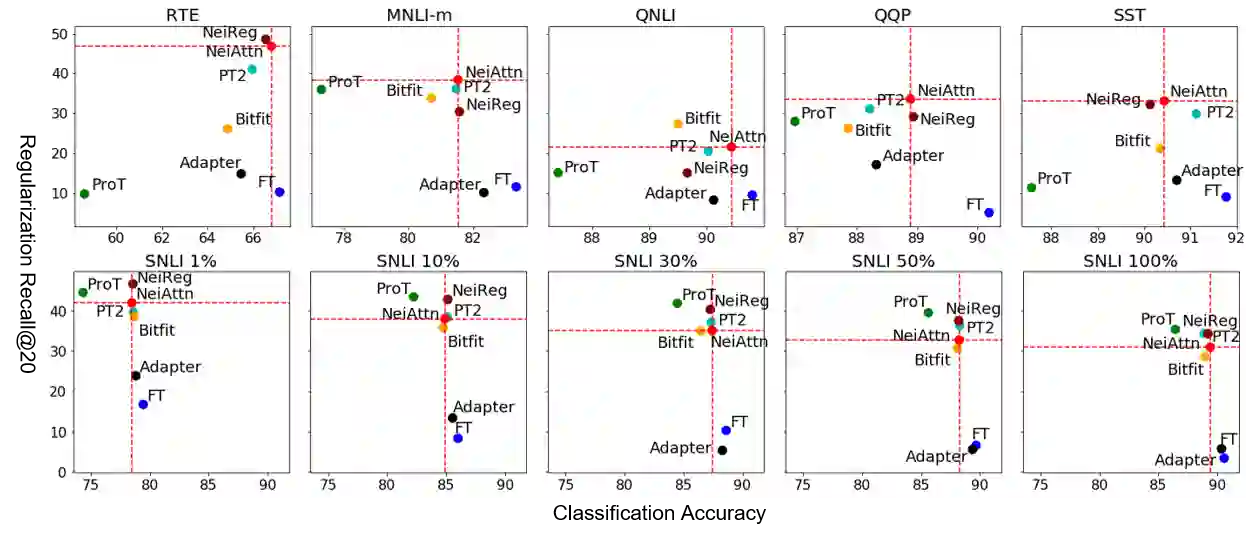
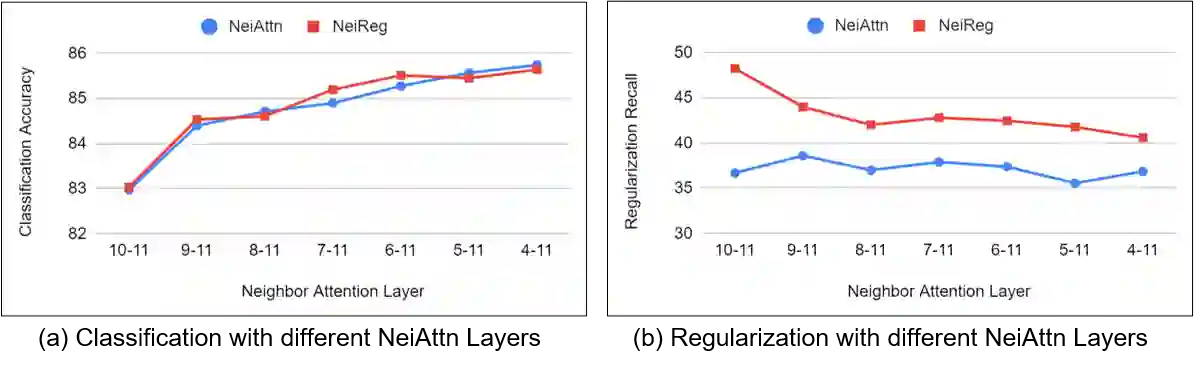
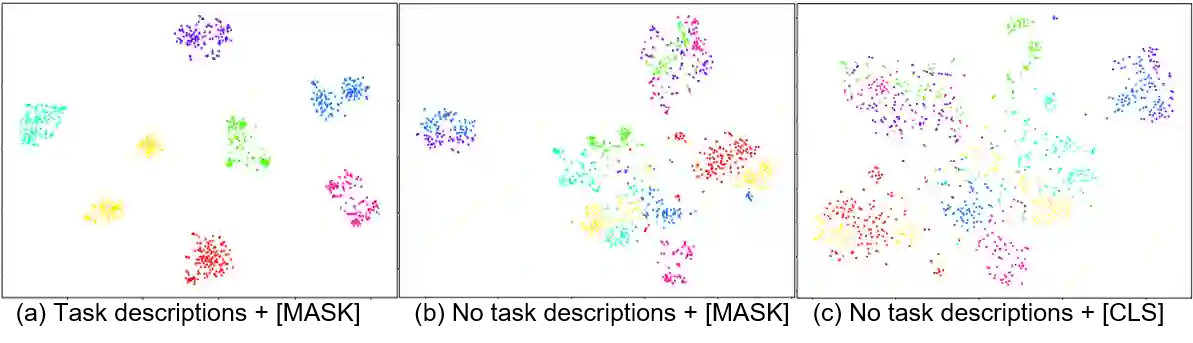
Continual learning (CL) aims to learn a sequence of tasks over time, with data distributions shifting from one task to another. When training on new task data, data representations from old tasks may drift. Some negative representation drift can result in catastrophic forgetting, by causing the locally learned class prototypes and data representations to correlate poorly across tasks. To mitigate such representation drift, we propose a method that finds global prototypes to guide the learning, and learns data representations with the regularization of the self-supervised information. Specifically, for NLP tasks, we formulate each task in a masked language modeling style, and learn the task via a neighbor attention mechanism over a pre-trained language model. Experimental results show that our proposed method can learn fairly consistent representations with less representation drift, and significantly reduce catastrophic forgetting in CL without resampling data from past tasks.
翻译:持续学习旨在随时间顺序学习一系列任务,其中数据分布会在不同任务间发生偏移。当训练新任务数据时,旧任务的数据表征可能发生漂移。某些负面表征漂移会导致本地学习的类别原型与数据表征在任务间相关性降低,进而引发灾难性遗忘。为缓解此类表征漂移,我们提出一种方法,通过寻找全局原型来引导学习过程,并利用自监督信息正则化学习数据表征。具体而言,针对自然语言处理任务,我们将每个任务构建为掩码语言建模形式,并通过预训练语言模型上的邻域注意力机制学习该任务。实验结果表明,所提方法能够学习到一致性较强的表征,有效减少表征漂移,并在无需重采样旧任务数据的情况下显著降低持续学习中的灾难性遗忘。