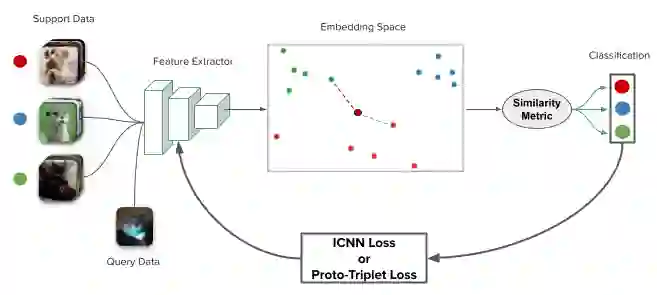
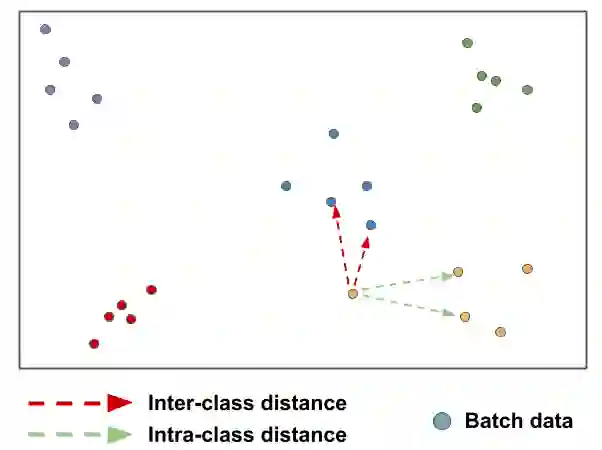
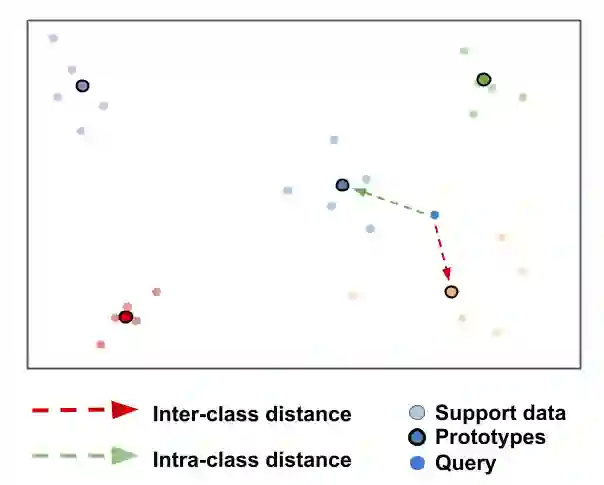
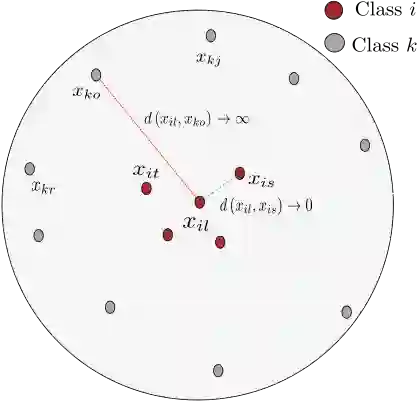
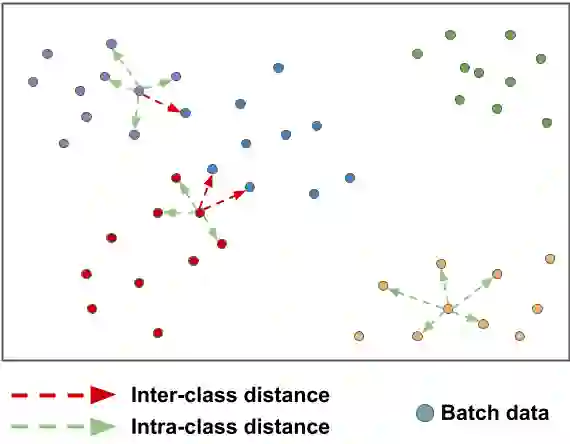
Few-shot learning is a challenging area of research that aims to learn new concepts with only a few labeled samples of data. Recent works based on metric-learning approaches leverage the meta-learning approach, which is encompassed by episodic tasks that make use a support (training) and query set (test) with the objective of learning a similarity comparison metric between those sets. Due to the lack of data, the learning process of the embedding network becomes an important part of the few-shot task. Previous works have addressed this problem using metric learning approaches, but the properties of the underlying latent space and the separability of the difference classes on it was not entirely enforced. In this work, we propose two different loss functions which consider the importance of the embedding vectors by looking at the intra-class and inter-class distance between the few data. The first loss function is the Proto-Triplet Loss, which is based on the original triplet loss with the modifications needed to better work on few-shot scenarios. The second loss function, which we dub ICNN loss is based on an inter and intra class nearest neighbors score, which help us to assess the quality of embeddings obtained from the trained network. Our results, obtained from a extensive experimental setup show a significant improvement in accuracy in the miniImagenNet benchmark compared to other metric-based few-shot learning methods by a margin of 2%, demonstrating the capability of these loss functions to allow the network to generalize better to previously unseen classes. In our experiments, we demonstrate competitive generalization capabilities to other domains, such as the Caltech CUB, Dogs and Cars datasets compared with the state of the art.
翻译:小样本学习是一个具有挑战性的研究领域,旨在仅通过少量标注样本学习新概念。近年来基于度量学习的方法通常借鉴元学习策略,该策略通过利用支持集(训练)和查询集(测试)的片段式任务,学习这两个集合间的相似度比较度量。由于数据匮乏,嵌入网络的学习过程成为小样本任务的关键环节。先前的研究虽采用度量学习方法解决该问题,但未能充分强化潜在空间的特性及不同类别在该空间中的可分性。本文提出两种考虑嵌入向量重要性的损失函数,通过分析少量数据的类内距离与类间距离来优化学习。第一种损失函数为Proto-Triplet Loss,其基于原始三元组损失进行针对性改进,以更好地适配小样本场景。第二种损失函数(命名为ICNN损失)基于类内与类间最近邻得分,可有效评估训练网络生成的嵌入质量。通过大规模实验设置,我们的结果表明:在miniImageNet基准测试中,与其他基于度量的小样本学习方法相比,准确率显著提升2%,证明这些损失函数能使网络更好地泛化至未见类别。实验同时表明,与现有最先进方法相比,本方法在Caltech CUB、Dogs及Cars等其他领域数据集上展现出具有竞争力的泛化能力。