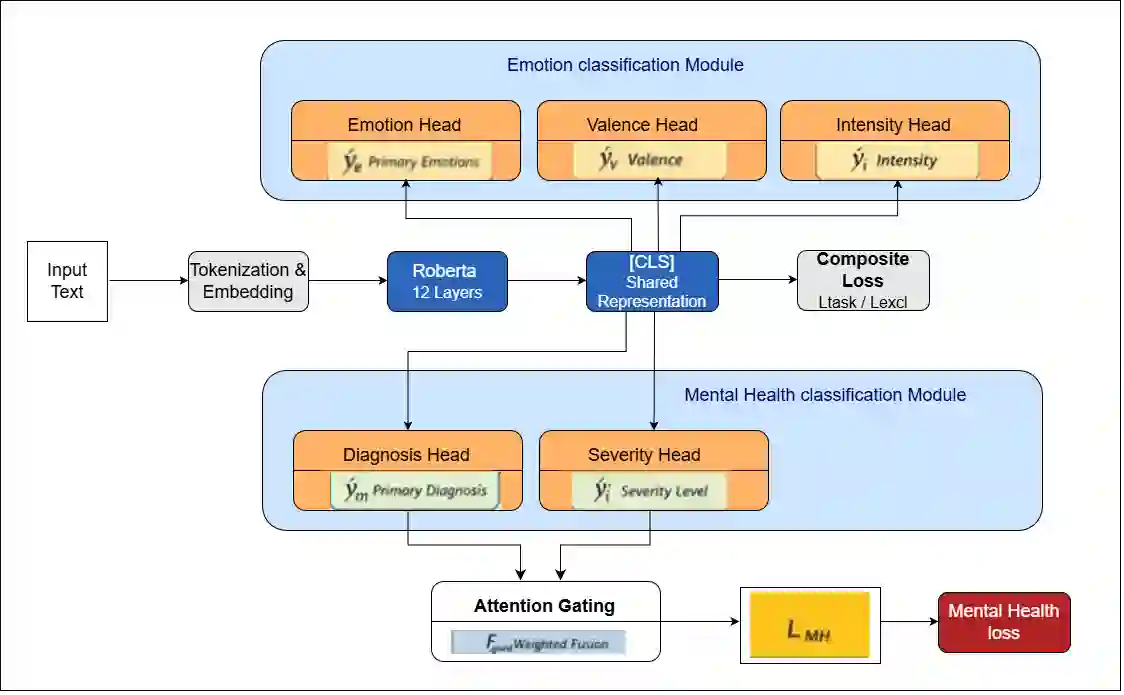
Textual Emotion Classification (TEC) is one of the most difficult NLP tasks. State of the art approaches rely on Large language models (LLMs) and multi-model ensembles. In this study, we challenge the assumption that larger scale or more complex models are necessary for improved performance. In order to improve logical consistency, We introduce CMHL, a novel single-model architecture that explicitly models the logical structure of emotions through three key innovations: (1) multi-task learning that jointly predicts primary emotions, valence, and intensity, (2) psychologically-grounded auxiliary supervision derived from Russell's circumplex model, and (3) a novel contrastive contradiction loss that enforces emotional consistency by penalizing mutually incompatible predictions (e.g., simultaneous high confidence in joy and anger). With just 125M parameters, our model outperforms 56x larger LLMs and sLM ensembles with a new state-of-the-art F1 score of 93.75\% compared to (86.13\%-93.2\%) on the dair-ai Emotion dataset. We further show cross domain generalization on the Reddit Suicide Watch and Mental Health Collection dataset (SWMH), outperforming domain-specific models like MentalBERT and MentalRoBERTa with an F1 score of 72.50\% compared to (68.16\%-72.16\%) + a 73.30\% recall compared to (67.05\%-70.89\%) that translates to enhanced sensitivity for detecting mental health distress. Our work establishes that architectural intelligence (not parameter count) drives progress in TEC. By embedding psychological priors and explicit consistency constraints, a well-designed single model can outperform both massive LLMs and complex ensembles, offering a efficient, interpretable, and clinically-relevant paradigm for affective computing.
翻译:文本情感分类是自然语言处理领域最具挑战性的任务之一。当前最先进的方法依赖于大语言模型和多模型集成。本研究挑战了“提升性能必须依赖更大规模或更复杂模型”的假设。为提高逻辑一致性,我们提出了CMHL——一种新颖的单模型架构,通过三项关键创新显式建模情感的逻辑结构:(1) 联合预测基本情感、效价与强度的多任务学习;(2) 基于罗素环状模型的心理驱动辅助监督;(3) 新型对比矛盾损失函数,通过惩罚互不相容的预测(例如对喜悦与愤怒同时赋予高置信度)来强化情感一致性。仅使用1.25亿参数,我们的模型在dair-ai Emotion数据集上以93.75%的F1分数(对比基线86.13%-93.2%)超越了参数量56倍的大语言模型与小语言模型集成,创造了新的最优性能。我们进一步在Reddit自杀监控与心理健康数据集上展示了跨领域泛化能力:相比MentalBERT、MentalRoBERTa等领域专用模型,以72.50%的F1分数(对比68.16%-72.16%)和73.30%的召回率(对比67.05%-70.89%)实现超越,该召回率提升意味着对心理健康危机信号的检测敏感度显著增强。本研究表明:驱动文本情感分类进步的核心是架构智能(而非参数量)。通过嵌入心理学先验与显式一致性约束,一个精心设计的单模型能够超越庞杂的大语言模型与复杂集成系统,为情感计算提供高效、可解释且具临床实用价值的新范式。