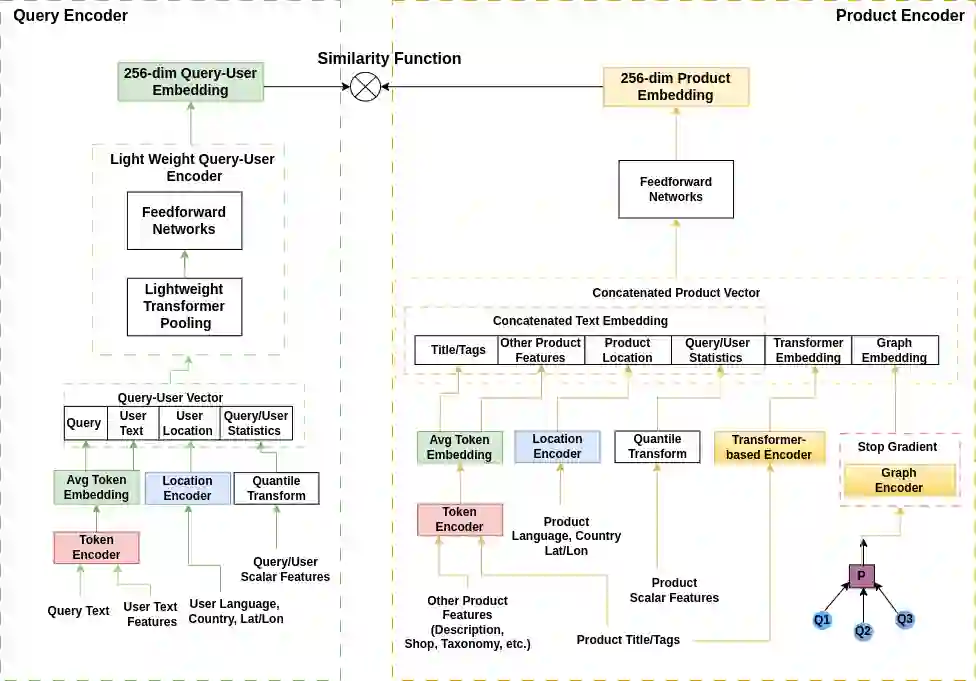
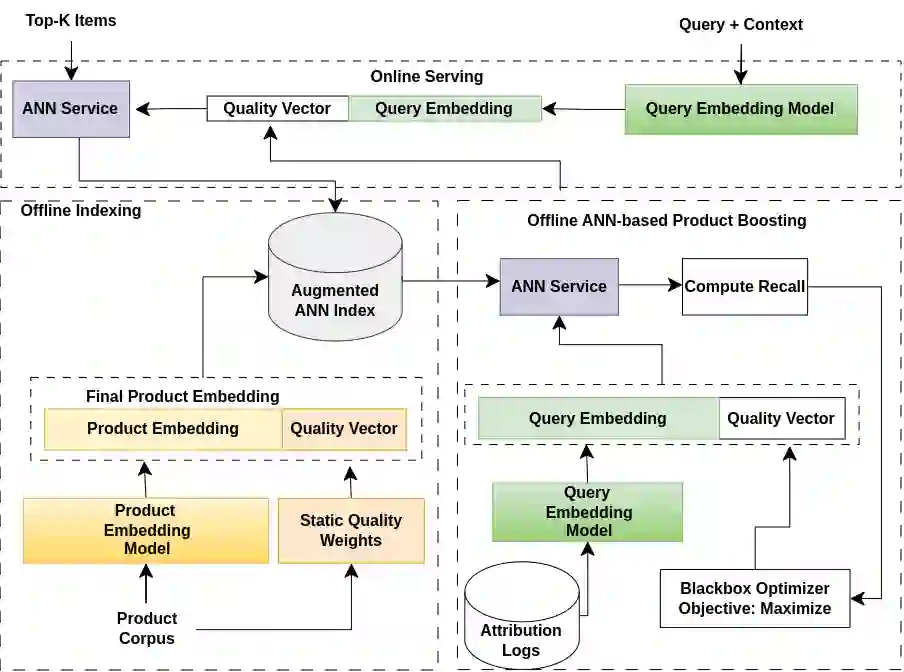
Embedding-based neural retrieval is a prevalent approach to address the semantic gap problem which often arises in product search on tail queries. In contrast, popular queries typically lack context and have a broad intent where additional context from users historical interaction can be helpful. In this paper, we share our novel approach to address both: the semantic gap problem followed by an end to end trained model for personalized semantic retrieval. We propose learning a unified embedding model incorporating graph, transformer and term-based embeddings end to end and share our design choices for optimal tradeoff between performance and efficiency. We share our learnings in feature engineering, hard negative sampling strategy, and application of transformer model, including a novel pre-training strategy and other tricks for improving search relevance and deploying such a model at industry scale. Our personalized retrieval model significantly improves the overall search experience, as measured by a 5.58% increase in search purchase rate and a 2.63% increase in site-wide conversion rate, aggregated across multiple A/B tests - on live traffic.
翻译:基于嵌入的神经检索是解决产品搜索中尾部查询常见语义鸿沟问题的主流方法。相比之下,热门查询通常缺乏上下文且意图宽泛,此时用户历史交互提供的额外上下文会有所帮助。本文分享我们解决这两类问题的新方法:首先处理语义鸿沟问题,随后提出端到端训练的个性化语义检索模型。我们提出学习一个融合图嵌入、Transformer嵌入和基于词项的嵌入的端到端统一嵌入模型,并分享我们在性能与效率间取得最优权衡的设计选择。我们总结了在特征工程、困难负样本采样策略以及Transformer模型应用方面的经验,包括新颖的预训练策略和其他提升搜索相关性、实现工业级规模部署的技术。我们的个性化检索模型显著改善了整体搜索体验,通过多轮在线A/B测试的综合数据显示:搜索购买率提升5.58%,全站转化率提升2.63%。