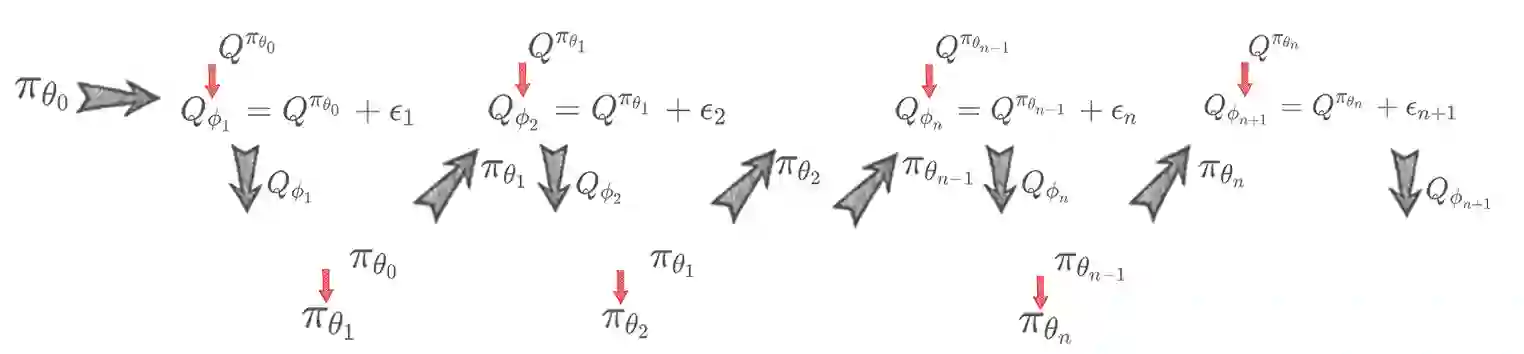
On error of value function inevitably causes an overestimation phenomenon and has a negative impact on the convergence of the algorithms. To mitigate the negative effects of the approximation error, we propose Error Controlled Actor-critic which ensures confining the approximation error in value function. We present an analysis of how the approximation error can hinder the optimization process of actor-critic methods.Then, we derive an upper boundary of the approximation error of Q function approximator and find that the error can be lowered by restricting on the KL-divergence between every two consecutive policies when training the policy. The results of experiments on a range of continuous control tasks demonstrate that the proposed actor-critic algorithm apparently reduces the approximation error and significantly outperforms other model-free RL algorithms.
翻译:值函数错误必然会造成高估现象,并对算法的趋同产生消极影响。 为了减轻近似差错的负面影响, 我们提议错误控制动作- 批评, 以确保将近似差错限制在值函数中。 我们分析近似差如何会阻碍动作- 批评方法的优化过程。 然后, 我们得出Q 函数相近差的上限, 并发现在培训政策时, 可以通过限制每两条连续政策之间的 KL 调整幅度来降低错误。 对一系列连续控制任务进行实验的结果显示, 拟议的动作- 批评算法显然减少了近似差, 大大优于其他无模型的 RL 算法 。