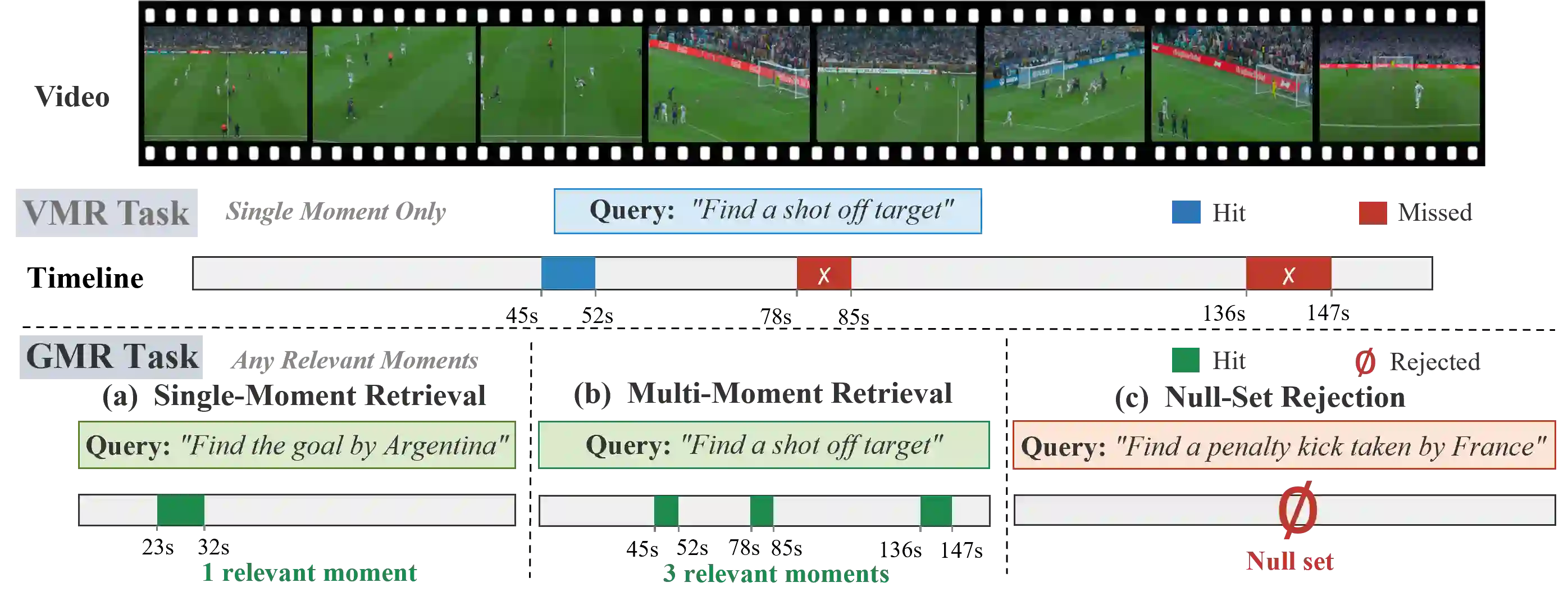
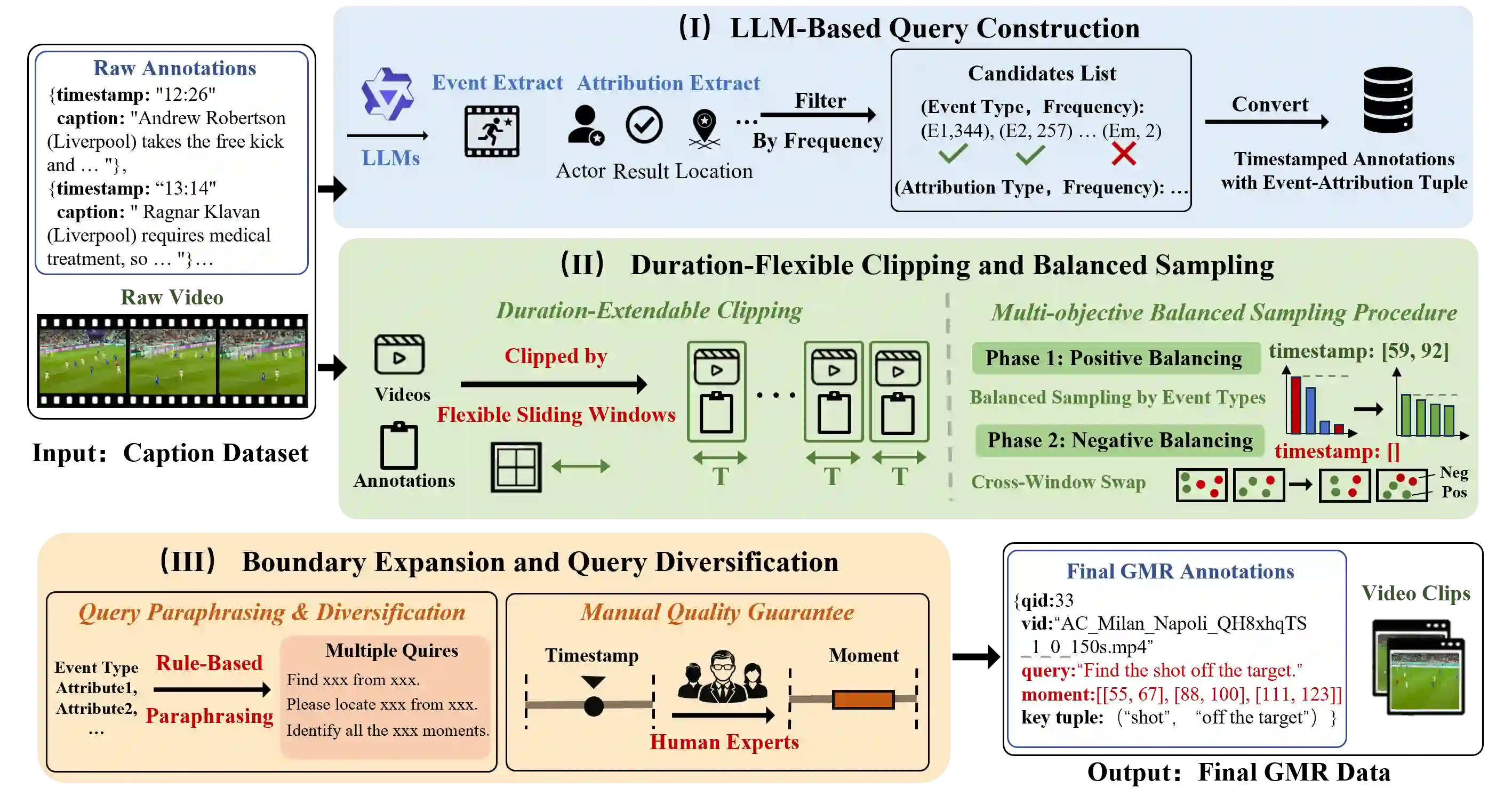
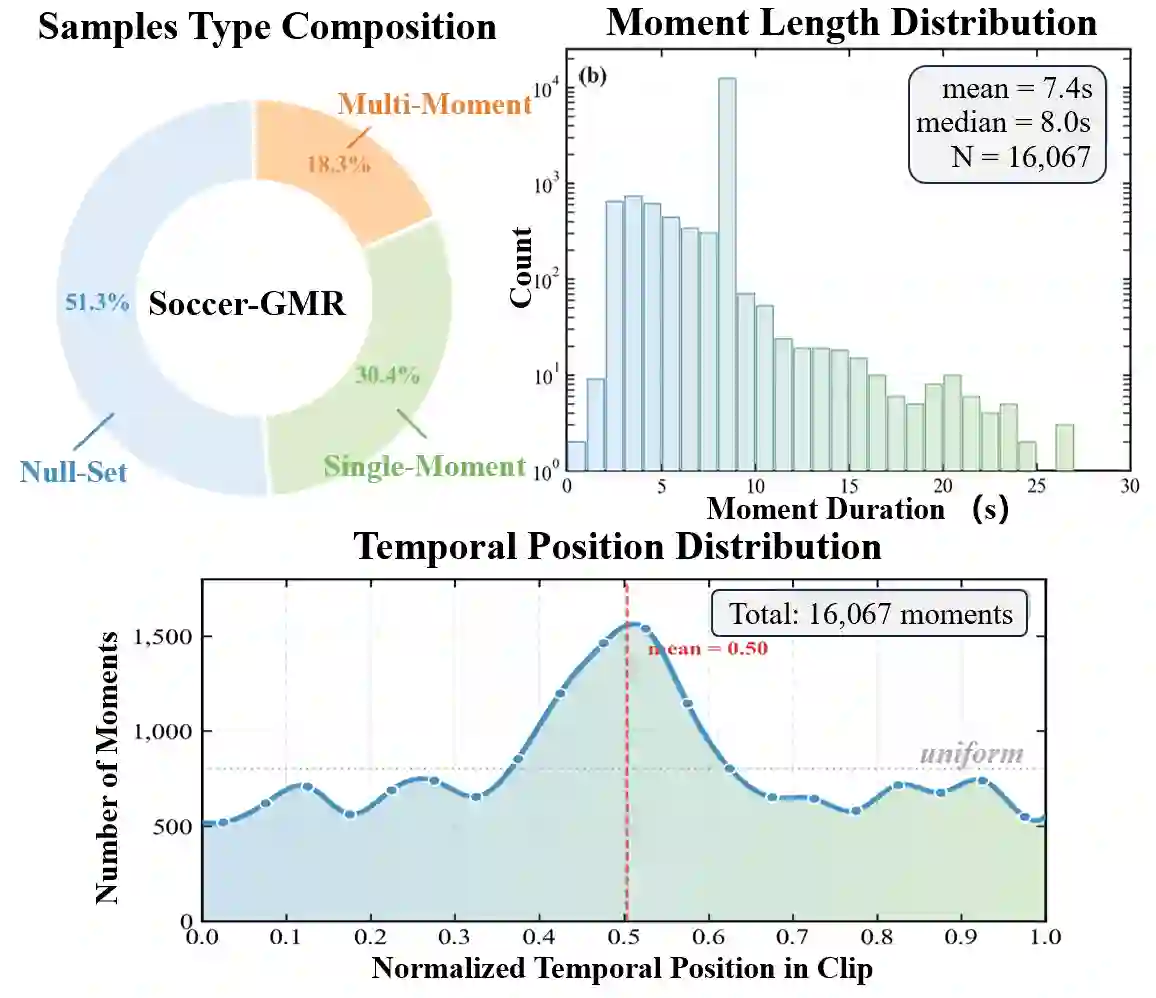
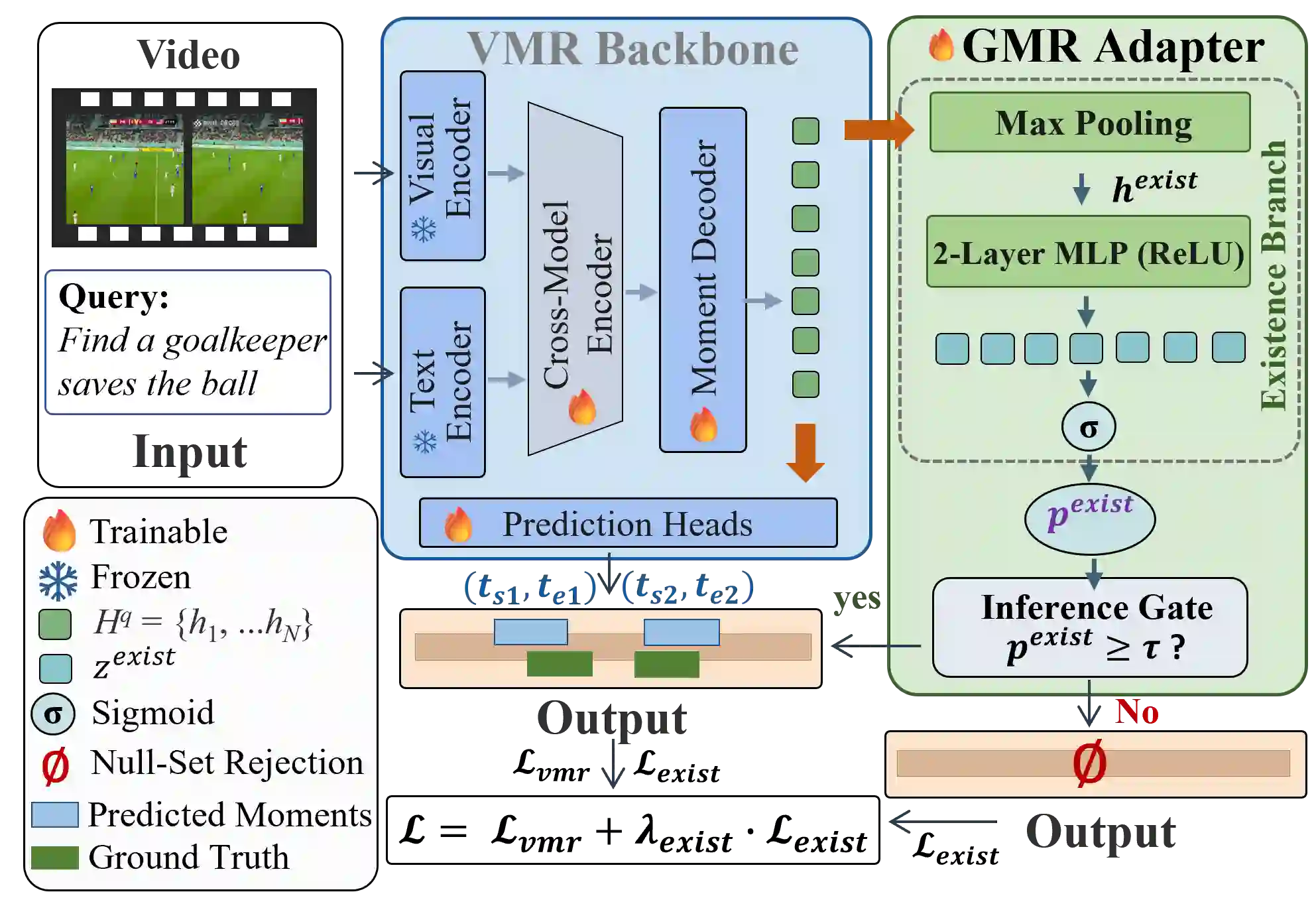
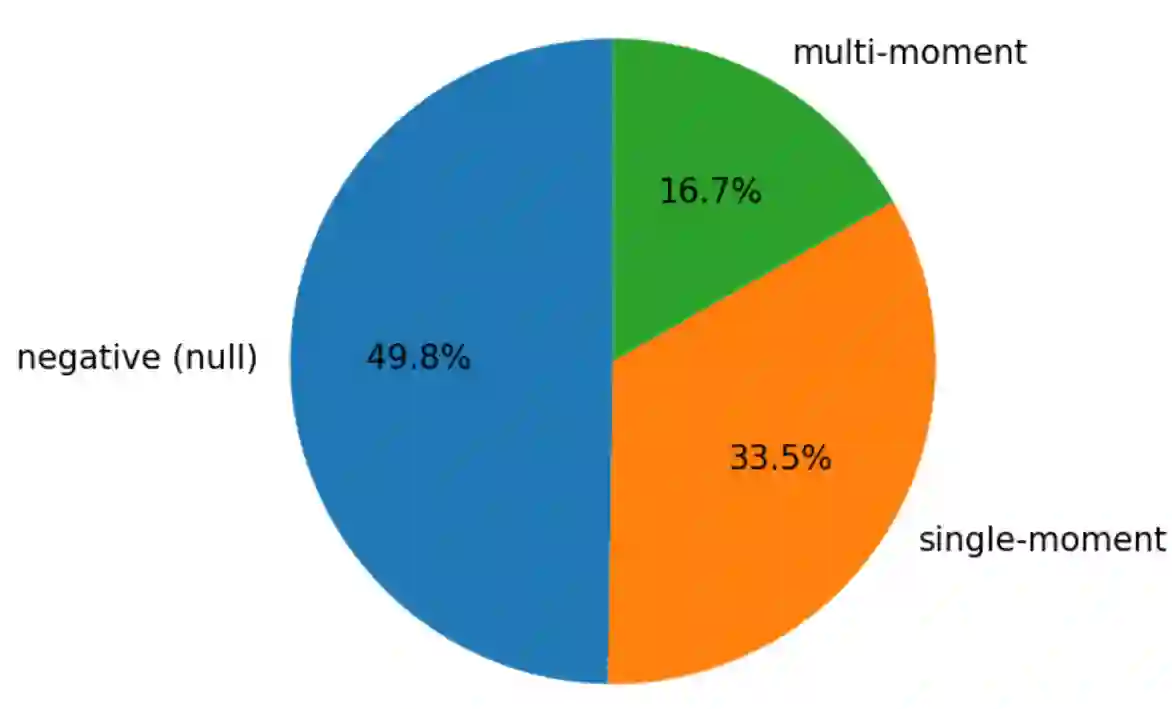
Video Moment Retrieval (VMR) aims to localize temporal segments in videos that correspond to a natural language query, but typically assumes only a single matching moment for each query. This assumption does not always hold in real-world scenarios, where queries may correspond to multiple or no moments. Thus, we formulate Generalized Moment Retrieval (GMR), a unified setting that requires retrieving the complete set of relevant moments or predicting an empty set. To enable systematic study of GMR, we introduce Soccer-GMR, a large-scale benchmark built on challenging soccer videos that reflect general GMR scenarios, with realistic negative and positive queries. The benchmark is constructed via a duration-flexible semi-automated pipeline with human verification, enabling scalable data generation while maintaining high annotation quality. We further design a unified evaluation protocol with complementary metrics tailored for null-set rejection, positive-query localization, and end-to-end GMR performance. Finally, we establish strong baselines across two modeling paradigms: a lightweight plug-and-play GMR adapter for discriminative VMR models, and a GMR-tailored GRPO reward for fine-tuning multimodal large language models (MLLMs). Extensive experiments show consistent gains across all metrics and expose key limitations of current methods, positioning GMR as a more realistic and challenging benchmark for video-language understanding.
翻译:视频时刻检索(Video Moment Retrieval, VMR)旨在定位视频中与自然语言查询相对应的时间片段,但通常假设每个查询仅有一个匹配时刻。这一假设在现实场景中并不总是成立,因为查询可能对应多个时刻或没有时刻。为此,我们定义了广义时刻检索(Generalized Moment Retrieval, GMR),这是一种统一的任务设定,要求检索完整的相关时刻集合或预测空集。为了系统研究GMR,我们引入了Soccer-GMR,这是一个基于挑战性足球视频构建的大规模基准数据集,反映了通用的GMR场景,包含真实的负样本和正样本查询。该基准通过一种时长灵活的半自动化流程构建,并辅以人工验证,从而在保持高标注质量的同时实现可扩展的数据生成。我们进一步设计了一套统一的评估协议,采用互补的指标,分别针对空集拒绝、正样本查询定位以及端到端GMR性能进行评价。最后,我们跨两种建模范式建立了强基线:一种用于判别式VMR模型的轻量级即插即用GMR适配器,以及一种专为GMR设计的GRPO奖励函数,用于微调多模态大语言模型(MLLMs)。大量实验表明,在所有指标上均取得了一致提升,并揭示了当前方法的关键局限性,从而将GMR定位为视频-语言理解领域中一个更现实且更具挑战性的基准。