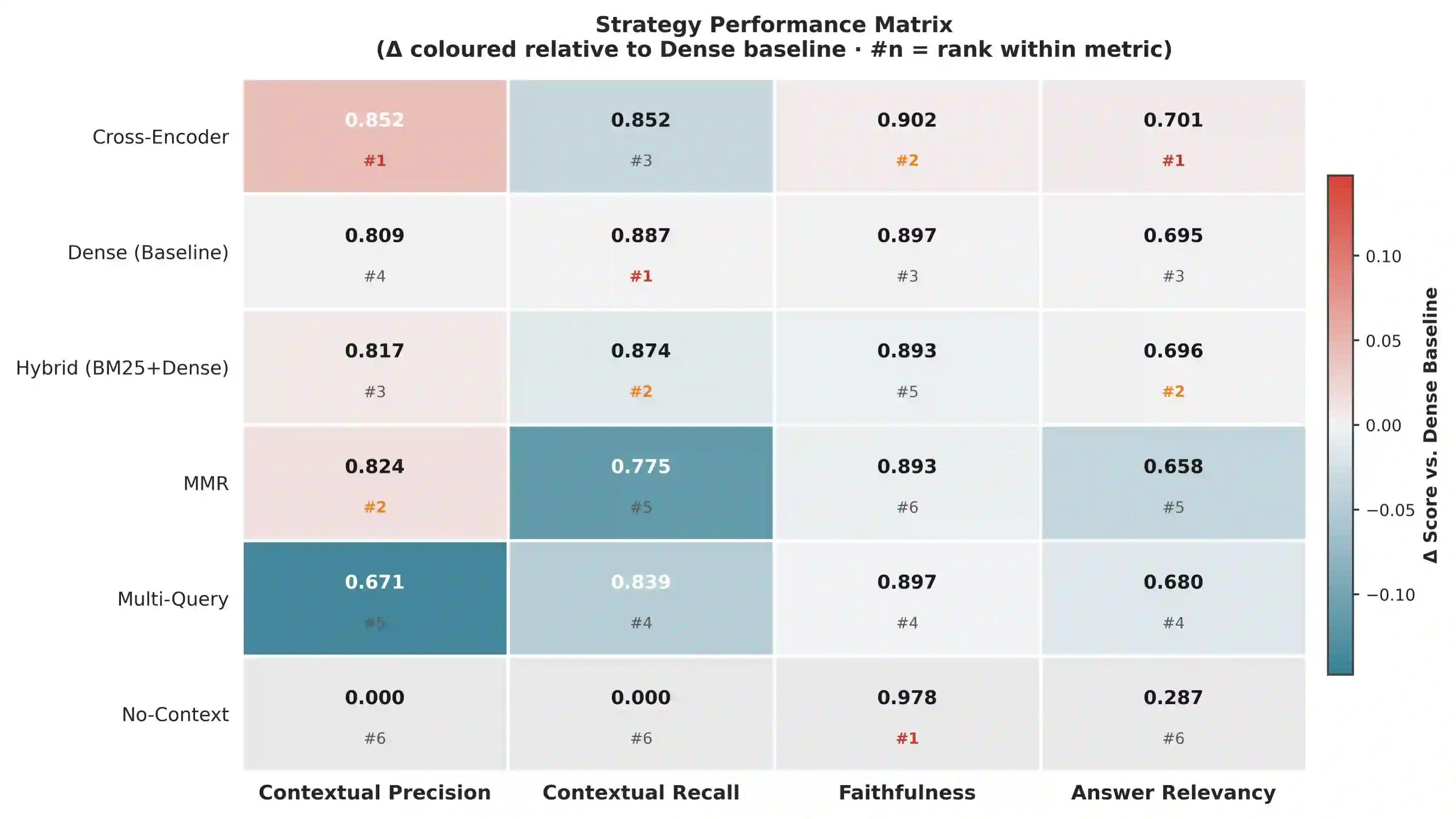
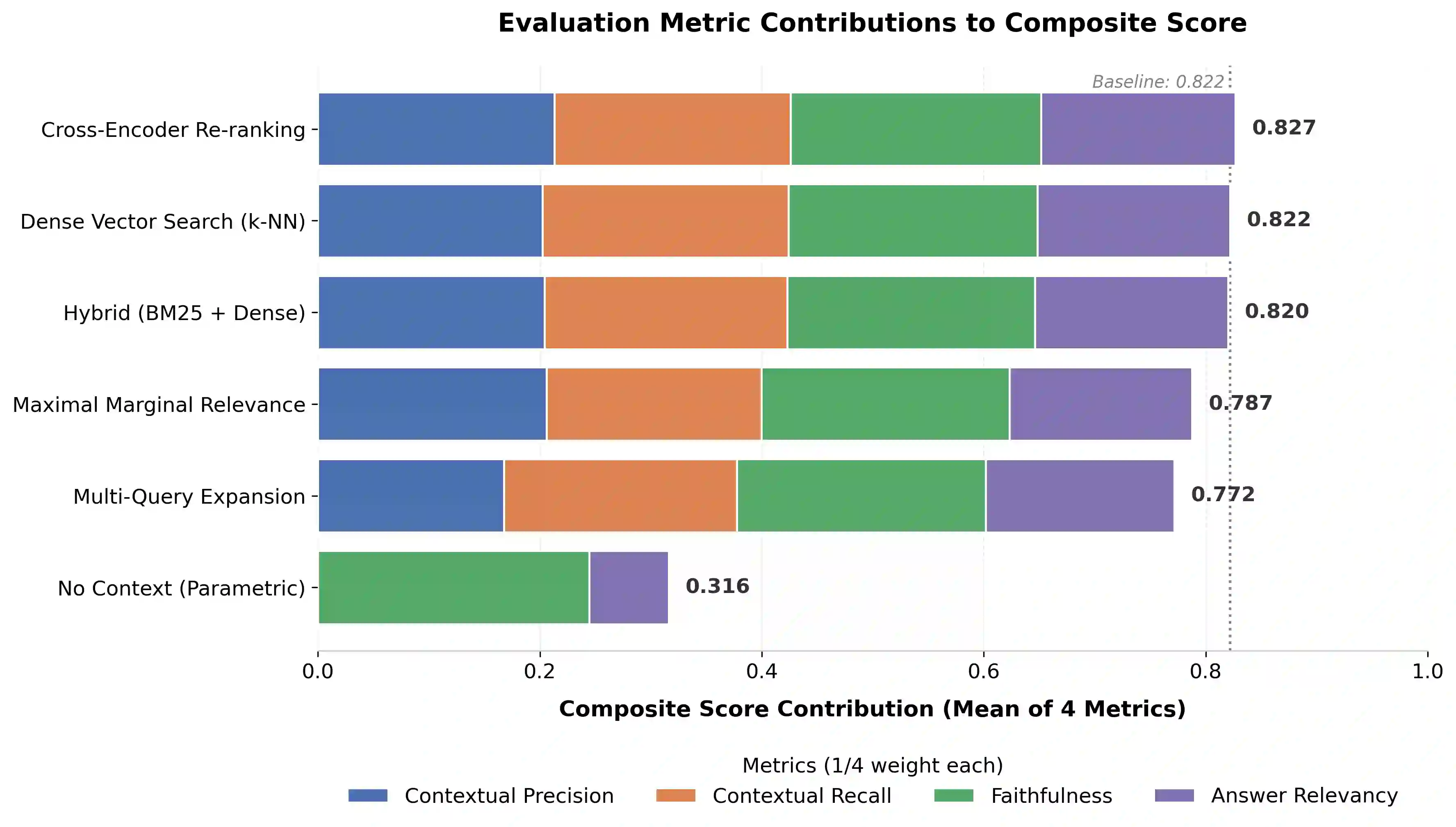
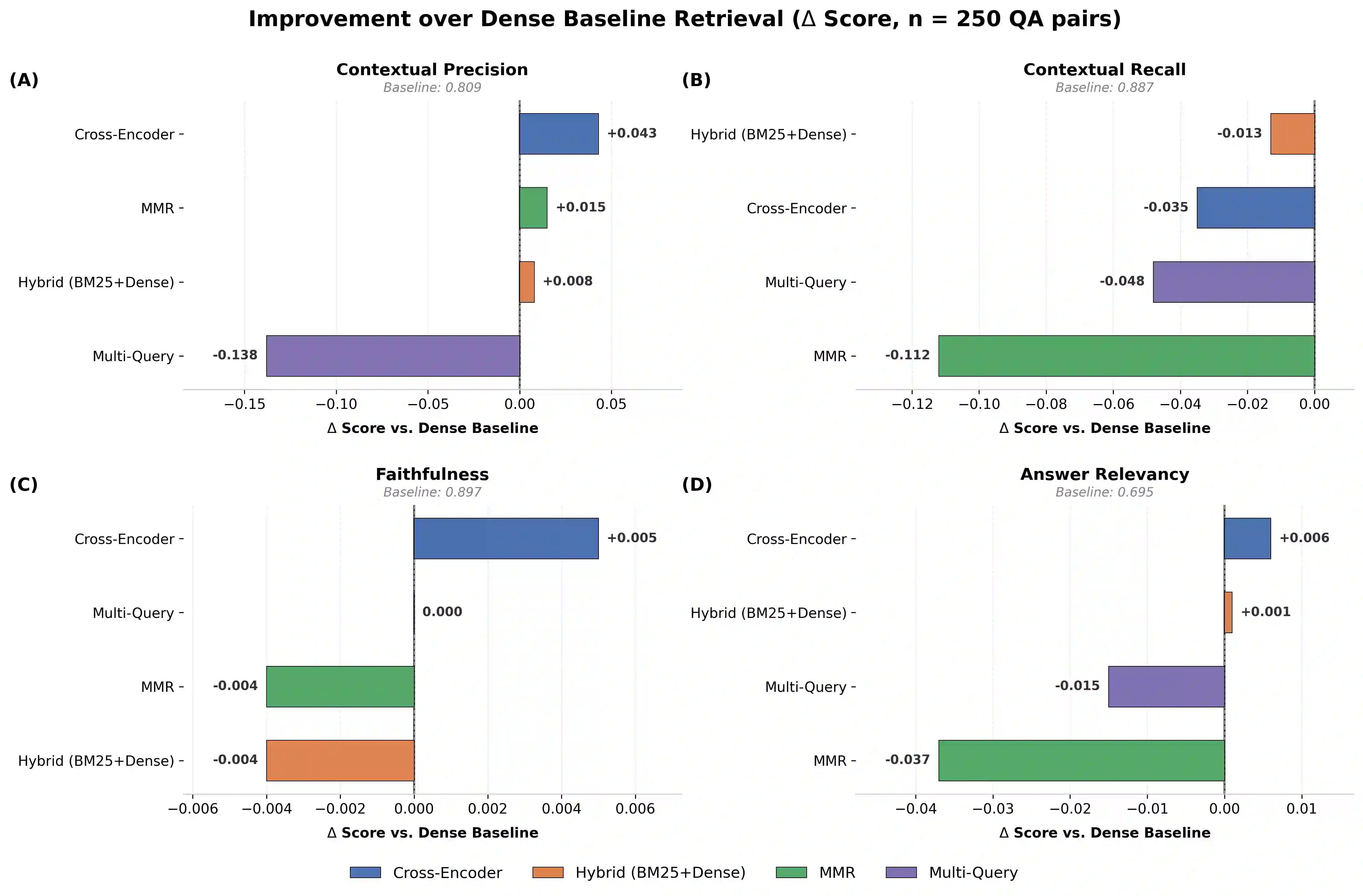
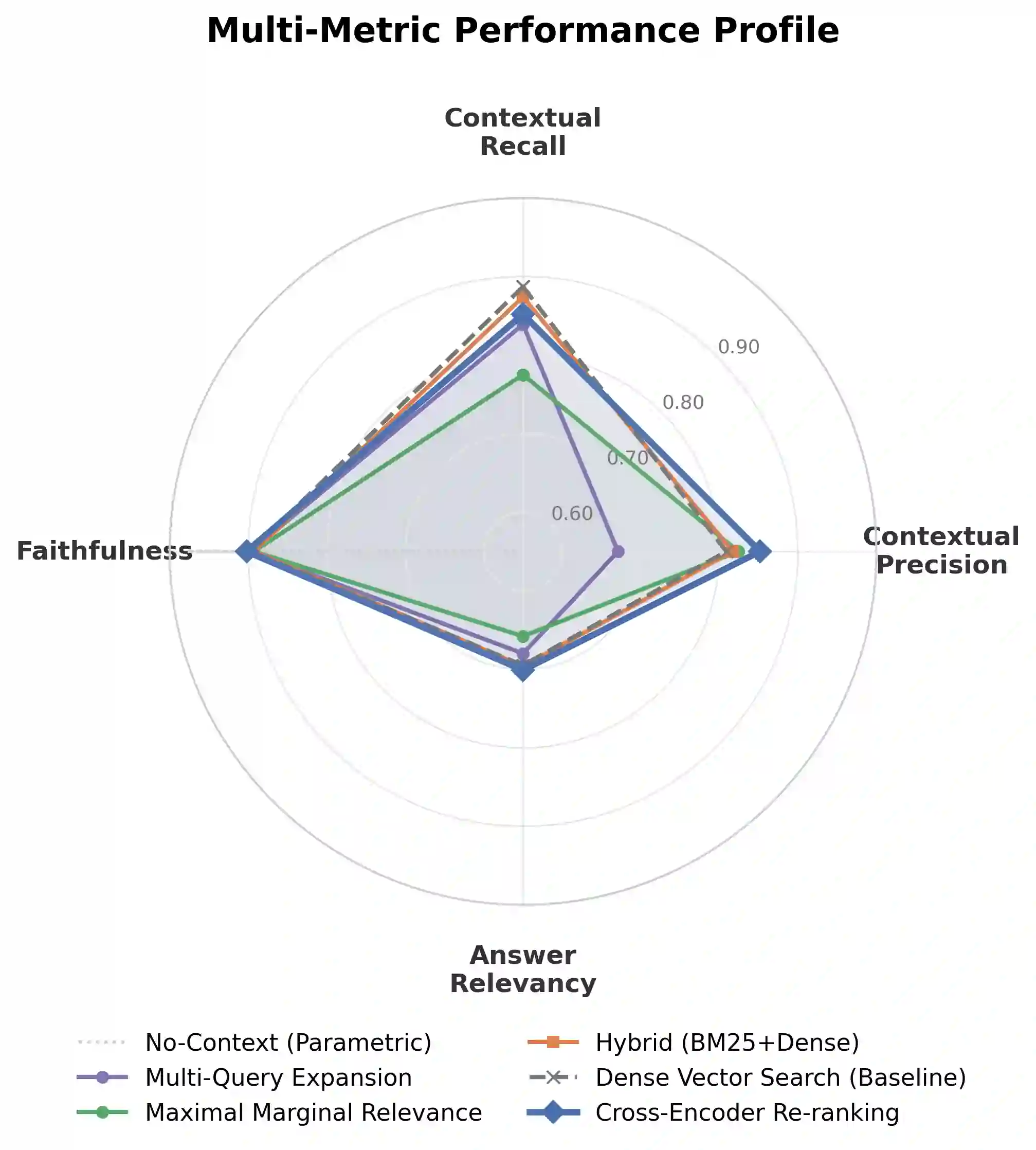
Retrieval-Augmented Generation (RAG) offers a well-established path to grounding large language model (LLM) outputs in external knowledge, yet the question of which retrieval strategy works best in a high-stakes domain such as biomedicine has not received the controlled, multi-metric treatment it deserves. This paper presents a systematic empirical comparison of five retrieval strategies -- Dense Vector Search, Hybrid BM25 + Dense retrieval, Cross-Encoder Reranking, Multi-Query Expansion, and Maximal Marginal Relevance (MMR) -- within a biomedical question-answering RAG pipeline. All strategies share a fixed generation model (GPT-4o-mini), a common vector store (ChromaDB), and OpenAI's text-embedding-3-small embeddings, ensuring that observed differences are attributable to retrieval alone. Evaluation is conducted on 250 question-answer pairs drawn from a preprocessed subset of the BioASQ benchmark (rag-mini-bioasq) using four DeepEval metrics: contextual precision, contextual recall, faithfulness, and answer relevancy, each reported with 95% confidence intervals. A no-context ablation is included as a lower bound. Cross-Encoder Reranking achieves the best composite score (0.827) and highest contextual precision (0.852), confirming that query-document interaction yields measurable retrieval gains. Multi-Query Expansion, despite its recall-oriented design, produces the weakest contextual precision (0.671), suggesting naive query diversification introduces retrieval noise. MMR sacrifices answer relevancy for diversity, while the Dense baseline (composite 0.822) falls within 0.005 points of the top strategy. All RAG conditions dramatically outperform the no-context ablation on answer relevancy (0.658-0.701 vs. 0.287), confirming the practical value of retrieval. The full pipeline, hyperparameters, and evaluation code are publicly available.
翻译:检索增强生成(RAG)为将大语言模型(LLM)的输出锚定于外部知识提供了成熟途径,然而在高风险领域(如生物医学)中,何种检索策略表现最优这一问题,尚未得到受控的、多指标的系统性评估。本文针对生物医学问答RAG流水线,对五种检索策略——稠密向量检索、混合BM25+稠密检索、交叉编码器重排序、多查询扩展及最大边际相关性(MMR)——开展了系统的实证比较。所有策略均共享固定的生成模型(GPT-4o-mini)、通用向量数据库(ChromaDB)以及OpenAI的text-embedding-3-small嵌入模型,从而确保观测到的差异仅源于检索环节本身。实验基于从BioASQ基准(rag-mini-bioasq)预处理子集中提取的250个问答对,采用DeepEval框架的四个指标(上下文精确率、上下文召回率、忠实度及答案相关性)进行评估,每个指标均附有95%置信区间,并纳入无上下文消融实验作为性能下限。结果显示:交叉编码器重排序取得最优综合得分(0.827)及最高上下文精确率(0.852),证实查询-文档交互可带来可衡量的检索增益;多查询扩展虽以召回优化为设计目标,但上下文精确率最低(0.671),表明朴素的查询多样化会引入检索噪声;MMR为多样性牺牲了答案相关性;而稠密基线策略(综合得分0.822)与最优策略的差距不足0.005分。所有RAG条件在答案相关性上均显著优于无上下文消融实验(0.658-0.701 vs. 0.287),验证了检索的实际价值。完整流水线、超参数及评估代码均已公开。