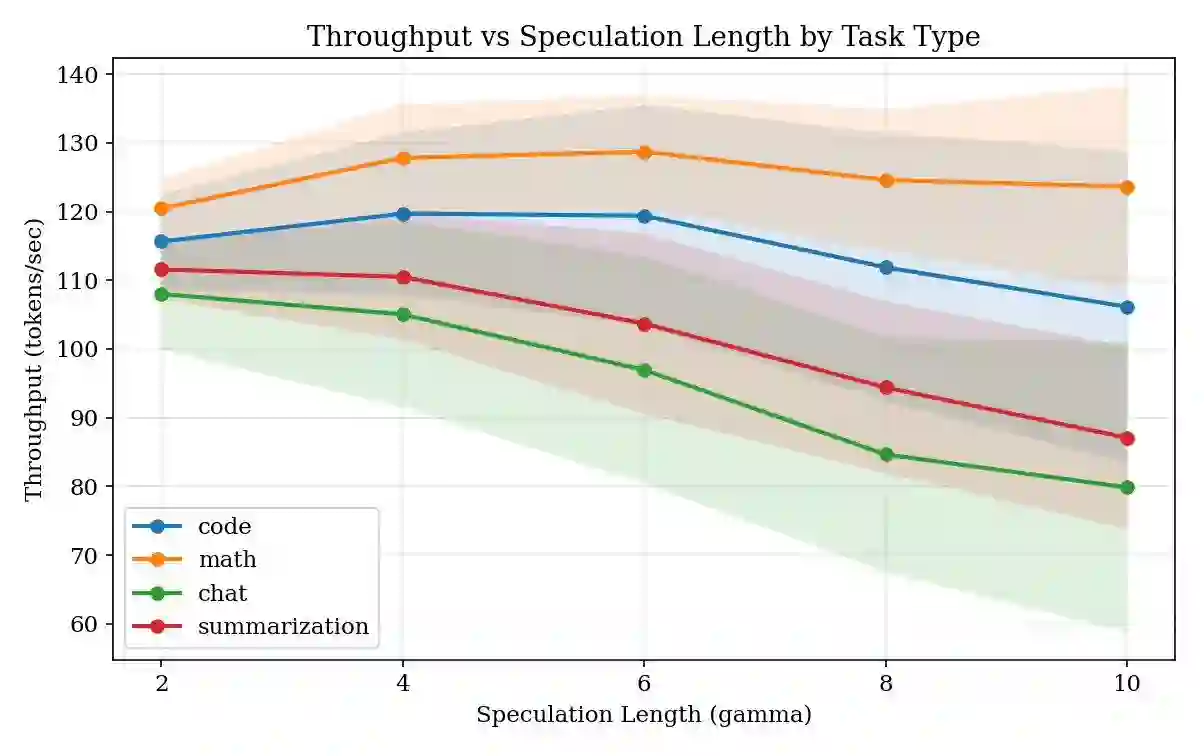
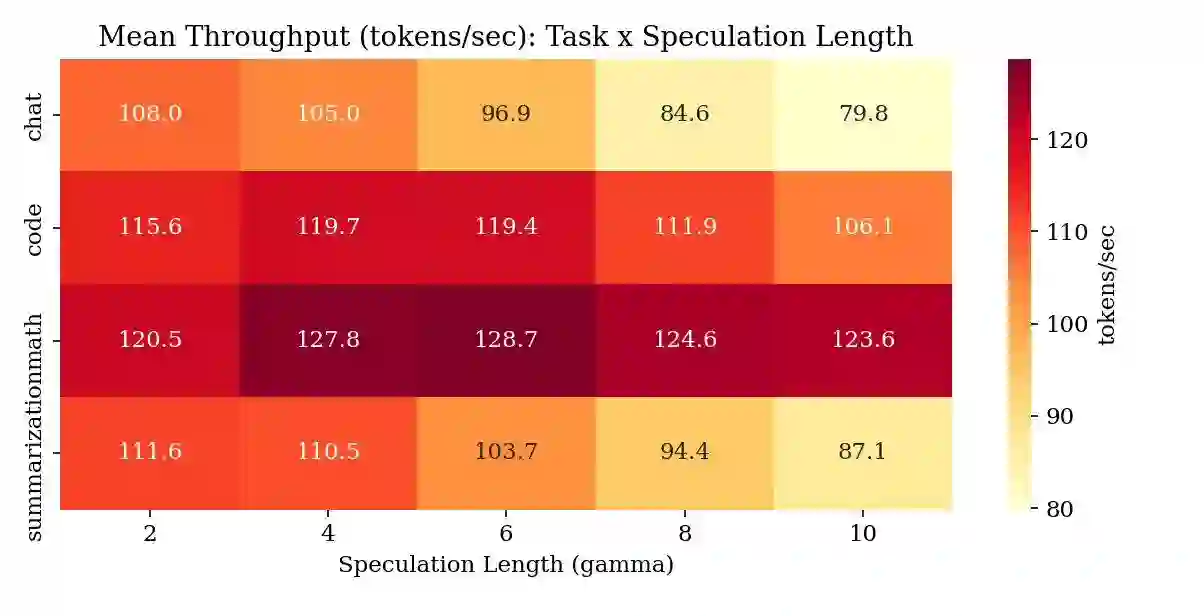
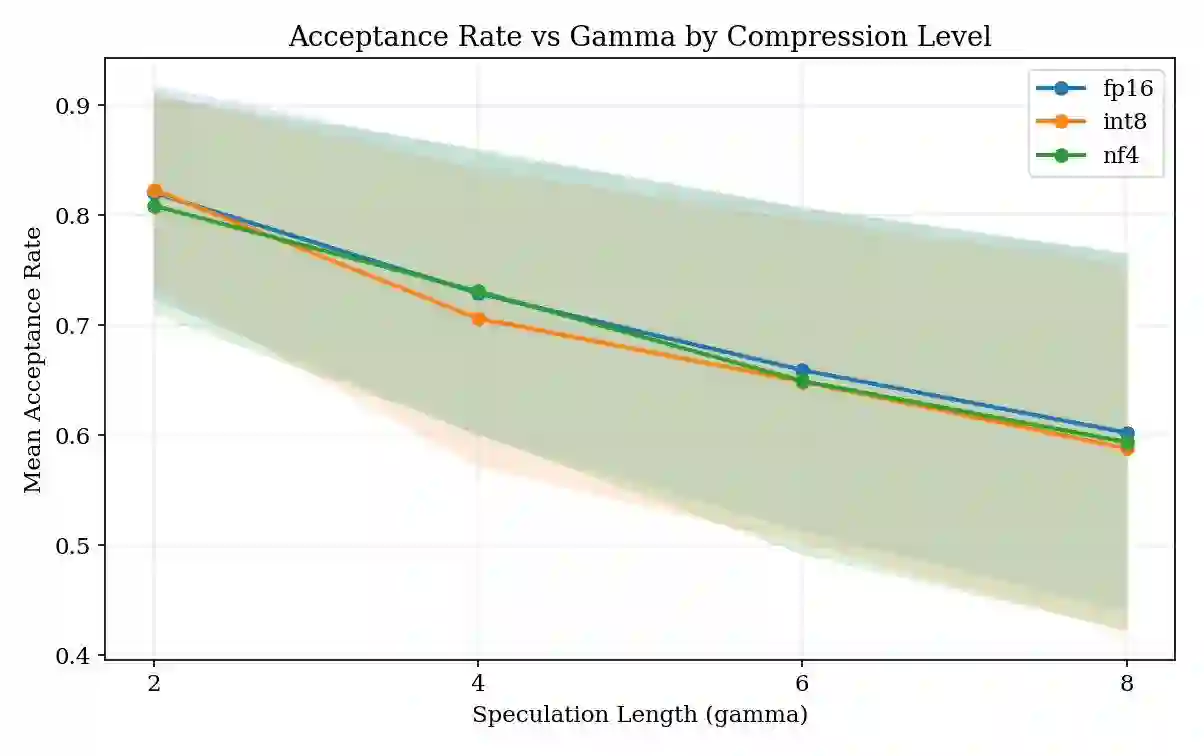
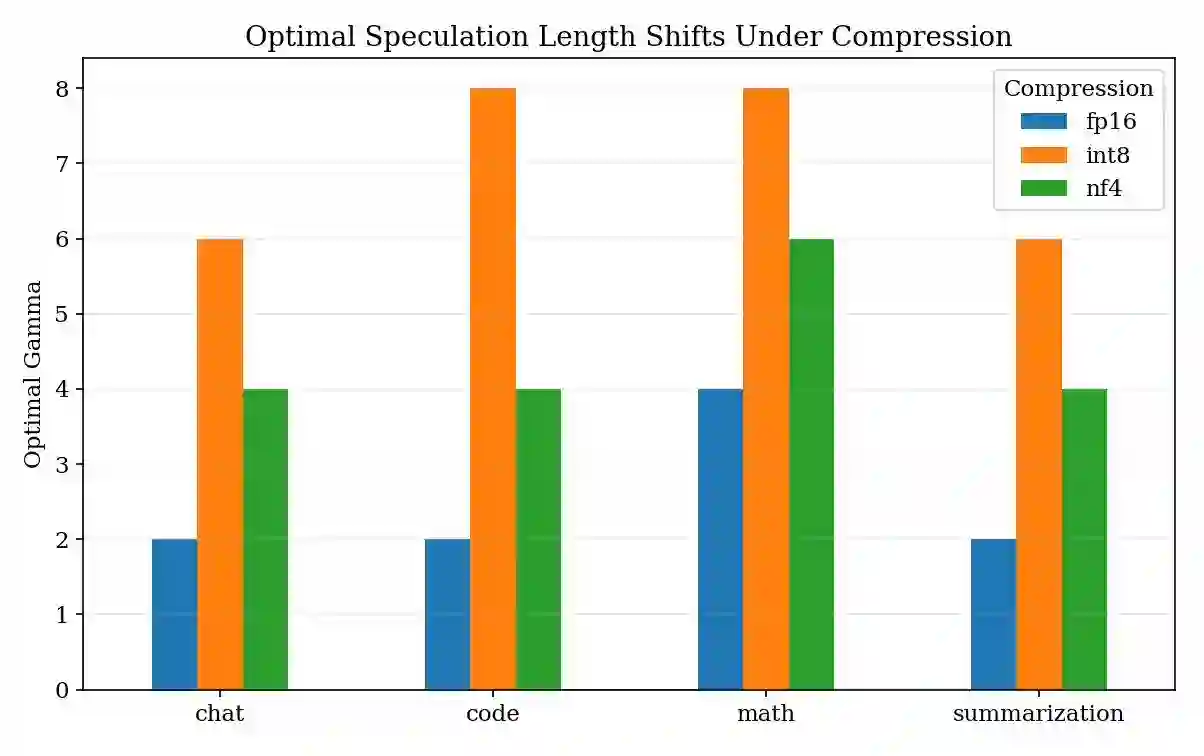
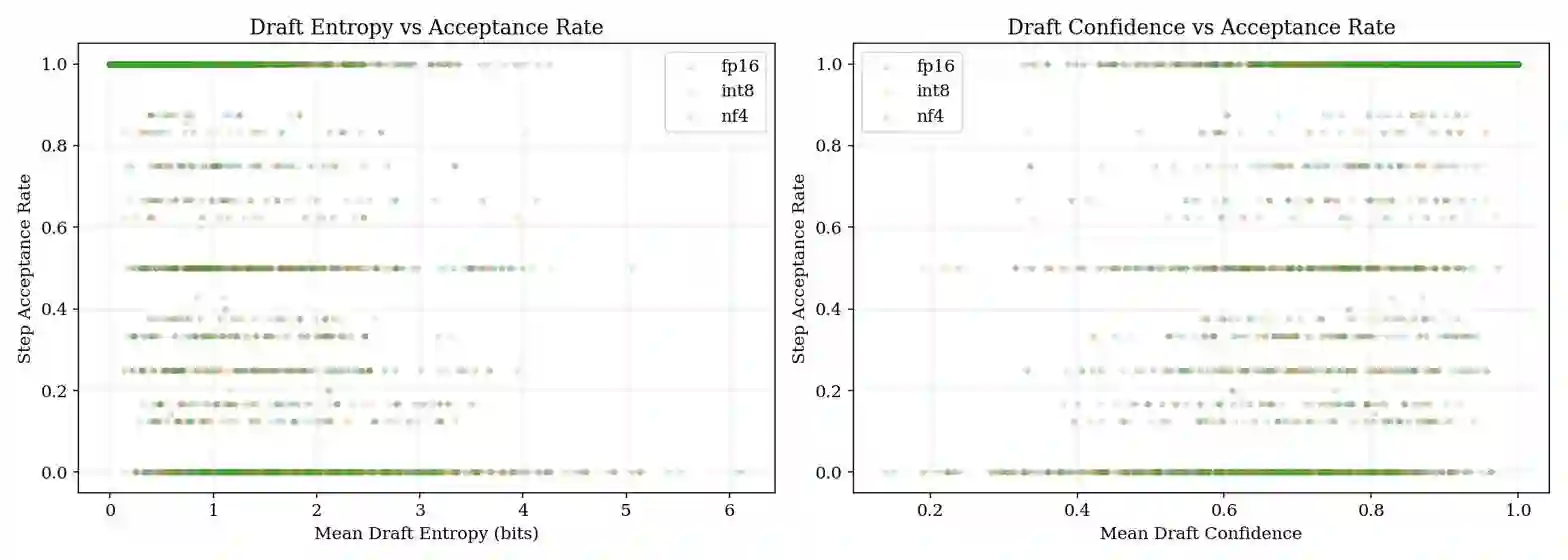
Speculative decoding accelerates large language model (LLM) inference by using a small draft model to propose candidate tokens that a larger target model verifies. A critical hyperparameter in this process is the speculation length~$γ$, which determines how many tokens the draft model proposes per step. Nearly all existing systems use a fixed~$γ$ (typically~4), yet empirical evidence suggests that the optimal value varies across task types and, crucially, depends on the compression level applied to the target model. In this paper, we present \textbf{SpecKV}, a lightweight adaptive controller that selects~$γ$ per speculation step using signals extracted from the draft model itself. We profile speculative decoding across 4~task categories, 4~speculation lengths, and 3~compression levels (FP16, INT8, NF4), collecting 5,112 step-level records with per-step acceptance rates, draft entropy, and draft confidence. We demonstrate that the optimal~$γ$ shifts across compression regimes and that draft model confidence and entropy are strong predictors of acceptance rate (correlation~$\approx 0.56$). SpecKV uses a small MLP trained on these signals to maximize expected tokens per speculation step, achieving a 56.0\% improvement over the fixed-$γ$=4 baseline with only 0.34\,ms overhead per decision ($<$0.5\% of step time). The improvement is statistically significant ($p < 0.001$, paired bootstrap test). We release all profiling data, trained models, and notebooks as open-source artifacts.
翻译:推测解码通过使用小型草稿模型生成候选令牌,再由大型目标模型进行验证,从而加速大语言模型推理。在此过程中,推测长度γ是关键超参数,它决定草稿模型每步生成的令牌数量。现有系统几乎都采用固定γ值(通常为4),但实验证据表明,最优值会因任务类型而异,且关键取决于目标模型所采用的压缩级别。本文提出**SpecKV**——一种轻量级自适应控制器,利用草稿模型自身提取的信号,在每步推测过程中动态选择γ值。我们在4类任务、4种推测长度及3种压缩级别(FP16、INT8、NF4)下剖析推测解码性能,收集了5,112条步级记录,涵盖每步接受率、草稿熵及草稿置信度。研究证明,最优γ值会随压缩体制变化,且草稿模型的置信度与熵是接受率的强预测因子(相关性≈0.56)。SpecKV基于这些信号训练小型MLP,以最大化每步推测的预期令牌数,较固定γ=4基线提升56.0%,每次决策仅增加0.34毫秒开销(不到步时长的0.5%)。该改进具有统计显著性(配对bootstrap检验,p<0.001)。我们将所有剖析数据、训练模型及开发笔记本作为开源资源发布。