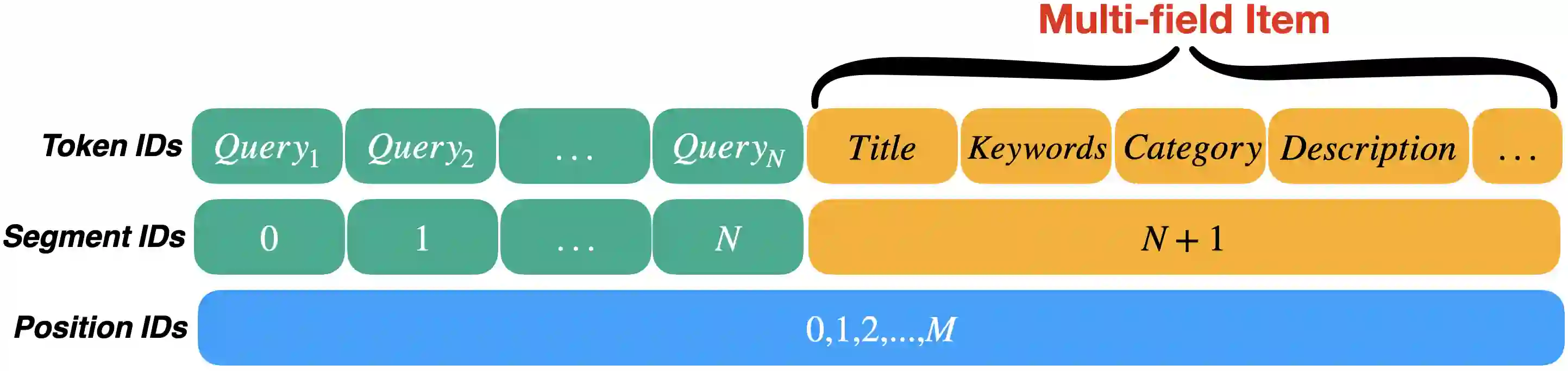
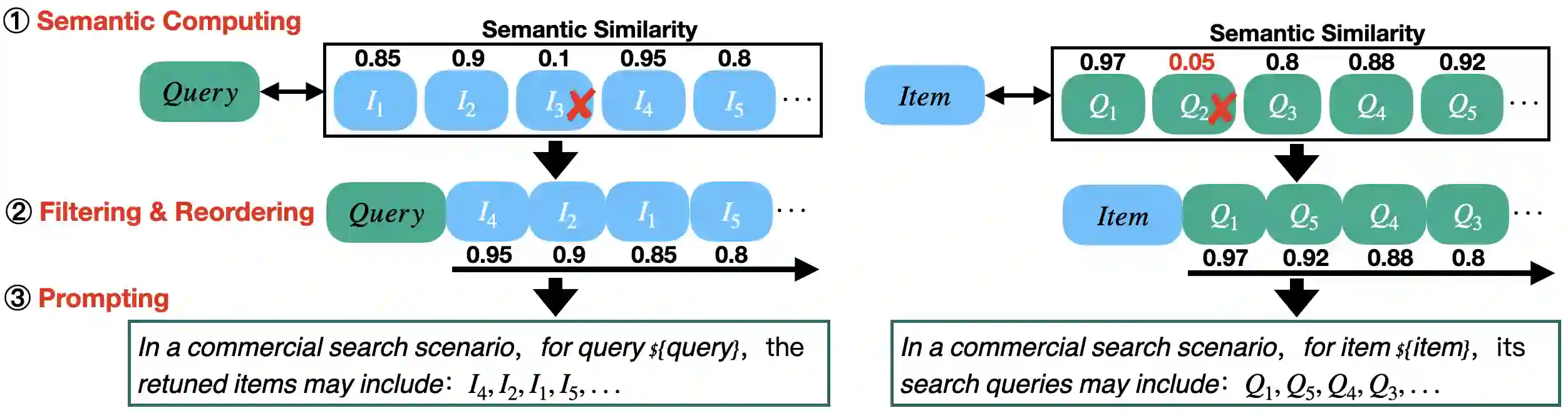
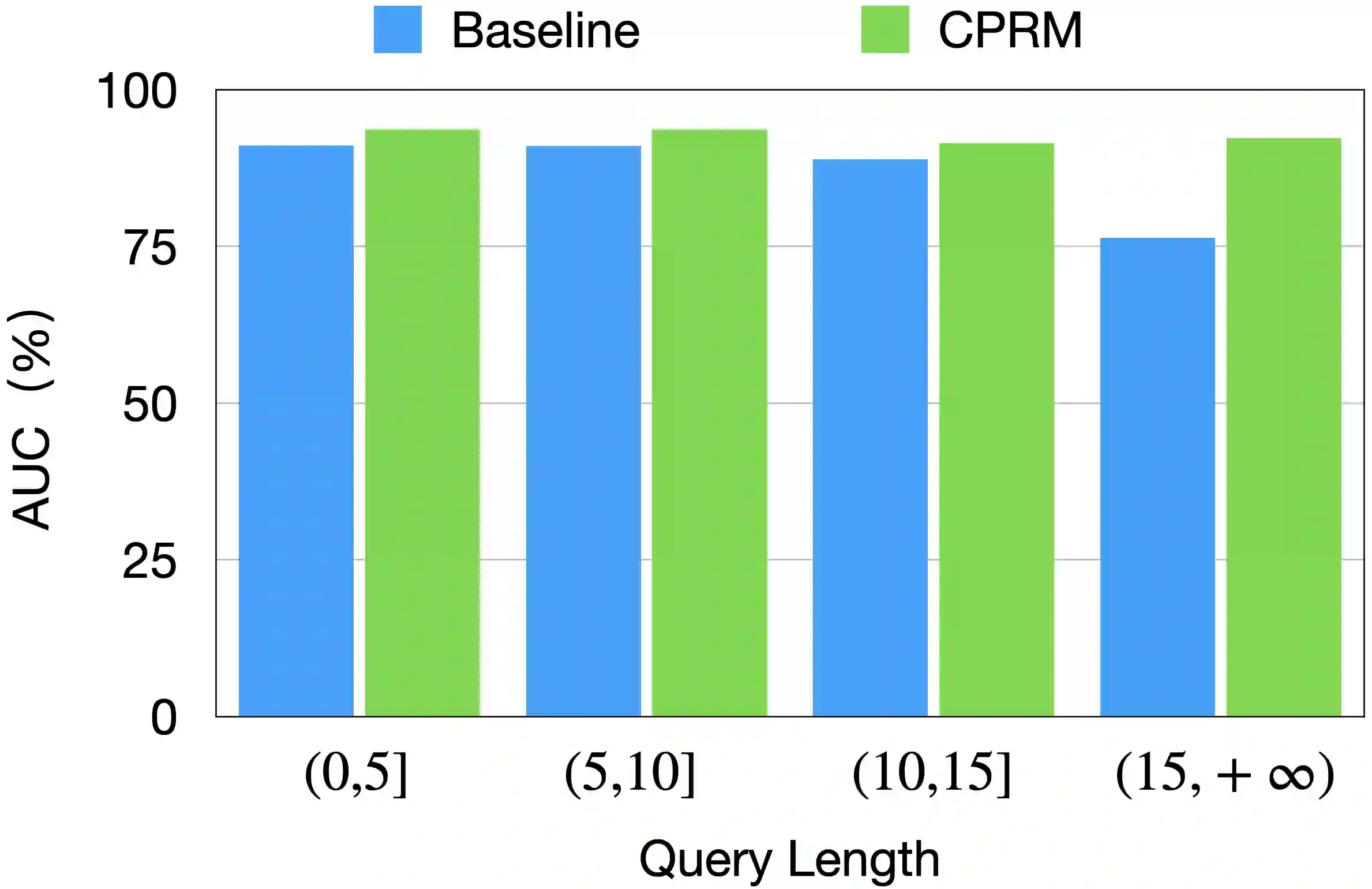
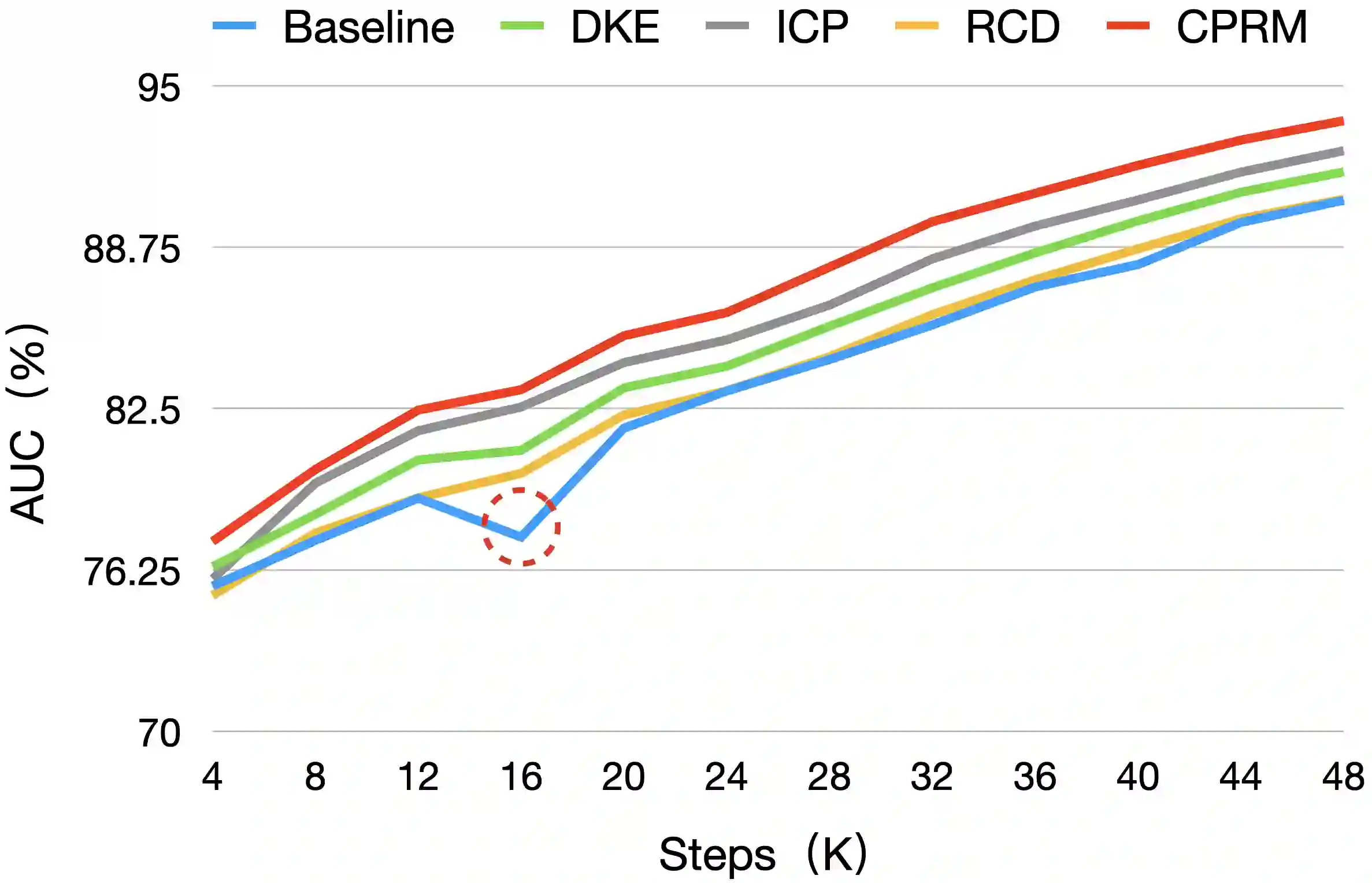
Relevance modeling between queries and items stands as a pivotal component in commercial search engines, directly affecting the user experience. Given the remarkable achievements of large language models (LLMs) in various natural language processing (NLP) tasks, LLM-based relevance modeling is gradually being adopted within industrial search systems. Nevertheless, foundational LLMs lack domain-specific knowledge and do not fully exploit the potential of in-context learning. Furthermore, structured item text remains underutilized, and there is a shortage in the supply of corresponding queries and background knowledge. We thereby propose CPRM (Continual Pre-training for Relevance Modeling), a framework designed for the continual pre-training of LLMs to address these issues. Our CPRM framework includes three modules: 1) employing both queries and multi-field item to jointly pre-train for enhancing domain knowledge, 2) applying in-context pre-training, a novel approach where LLMs are pre-trained on a sequence of related queries or items, and 3) conducting reading comprehension on items to produce associated domain knowledge and background information (e.g., generating summaries and corresponding queries) to further strengthen LLMs. Results on offline experiments and online A/B testing demonstrate that our model achieves convincing performance compared to strong baselines.
翻译:查询与商品之间的相关性建模是商业搜索引擎的关键组成部分,直接影响用户体验。鉴于大语言模型(LLMs)在各种自然语言处理(NLP)任务中取得的显著成就,基于LLM的相关性建模正逐渐被工业搜索系统所采用。然而,基础LLM缺乏特定领域的知识,未能充分利用上下文学习的潜力。此外,结构化的商品文本仍未得到充分利用,并且相应的查询和背景知识供给不足。为此,我们提出了CPRM(面向相关性建模的持续预训练),一个专为LLM持续预训练而设计的框架,以解决这些问题。我们的CPRM框架包含三个模块:1)联合使用查询和多字段商品进行预训练,以增强领域知识;2)应用上下文预训练,这是一种新颖的方法,让LLM在相关查询或商品序列上进行预训练;3)对商品进行阅读理解,以生成相关的领域知识和背景信息(例如,生成摘要和相应的查询),从而进一步增强LLM。离线实验和在线A/B测试的结果表明,与强大的基线模型相比,我们的模型取得了令人信服的表现。