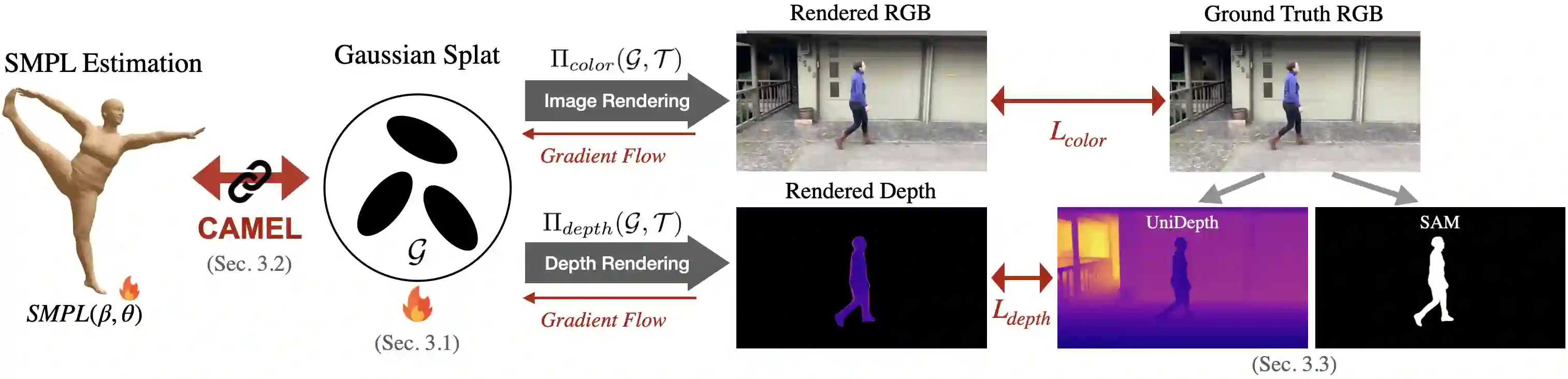
Accurately recovering human pose and appearance from video is an essential component of scene reconstruction, with applications to motion capture, motion prediction, virtual reality, and digital twinning. Despite significant interest in building realistic human avatars from video, this paper demonstrates that existing methods do not accurately recover the 3D geometry of humans. ViT-based approaches are not consistently reliable and can overfit to 2D views, while NeRF- and Gaussian Splatting-based avatars treat pose and appearance separately, limiting rendering generalization to new poses. To resolve these shortcomings, this paper proposes HumanSplatHMR, a joint optimization framework that refines 3D human poses while simultaneously learning a high-fidelity avatar for novel-view and novel-pose synthesis. Our key insight is to close the loop between geometric pose estimation and differentiable rendering. Unlike prior human avatar methods that rely on accurate human pose obtained through motion capture systems or offline refinement, which are impractical in in-the-wild scenarios, our approach uses only human mesh estimates from a state-of-the-art human pose estimator to better reflect real-world conditions. Therefore, instead of using the human pose only as a deformation prior, HumanSplatHMR backpropagates photometric, segmentation, and depth losses through a differentiable renderer to the pose parameters and global position. This coupling refines the global 3D pose over time, improving accuracy and alignment while producing better renderings from novel views. Experiments show consistent improvements over pose recovery baselines that omit image-level refinement and avatar baselines that decouple pose estimation from avatar reconstruction.
翻译:从视频中精确恢复人体姿态与外观是场景重建的关键组成部分,广泛应用于动作捕捉、运动预测、虚拟现实和数字孪生等领域。尽管构建逼真视频虚拟人的研究受到广泛关注,但本文证明现有方法无法准确恢复人体的三维几何结构。基于ViT的方法可靠性不一致且易过度拟合二维视角,而基于NeRF和高斯泼溅的虚拟人方法将姿态与外观分离处理,限制了渲染对新姿态的泛化能力。为解决这些缺陷,本文提出HumanSplatHMR——一种联合优化框架,在同步学习高保真虚拟人以实现新视角和新姿态合成的同时,精细化三维人体姿态。我们的核心见解在于建立几何姿态估计与可微分渲染之间的闭环。不同于依赖动作捕捉系统或离线优化获取精确人体姿态(这在野外场景中不可行)的现有虚拟人方法,本方法仅利用最先进人体姿态估计器的人体网格输出以贴近真实应用条件。因此,HumanSplatHMR并非仅将人体姿态作为形变先验,而是通过可微分渲染器将光度、分割和深度损失反向传播至姿态参数及全局位置。这种耦合机制使全局三维姿态随时间逐步优化,在提升精度与对齐度的同时,生成更优质的新视角渲染结果。实验表明,相较于省略图像级优化的姿态恢复基线方法以及将姿态估计与虚拟人重建解耦的基线方法,本方法均取得一致性改进。