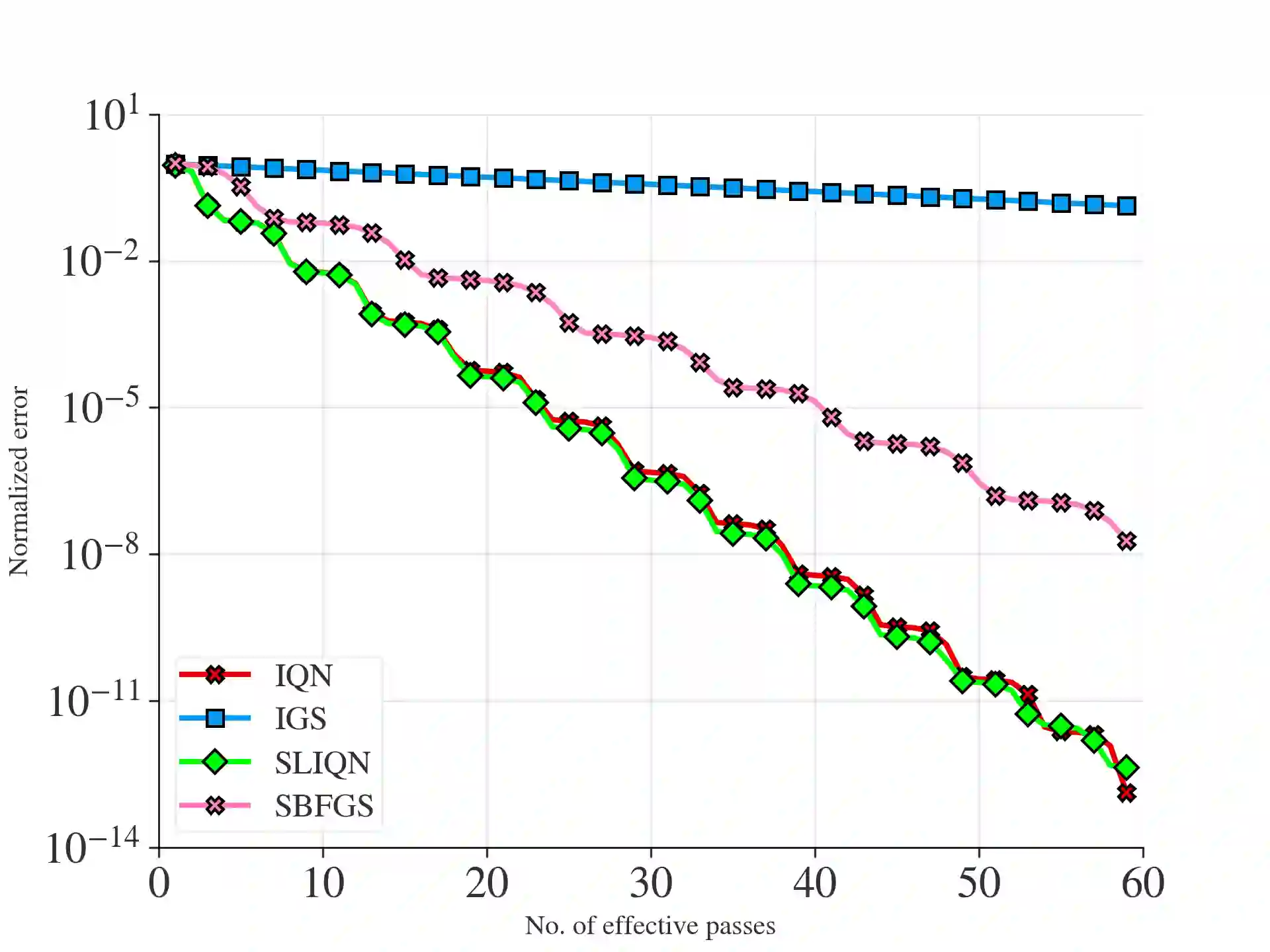
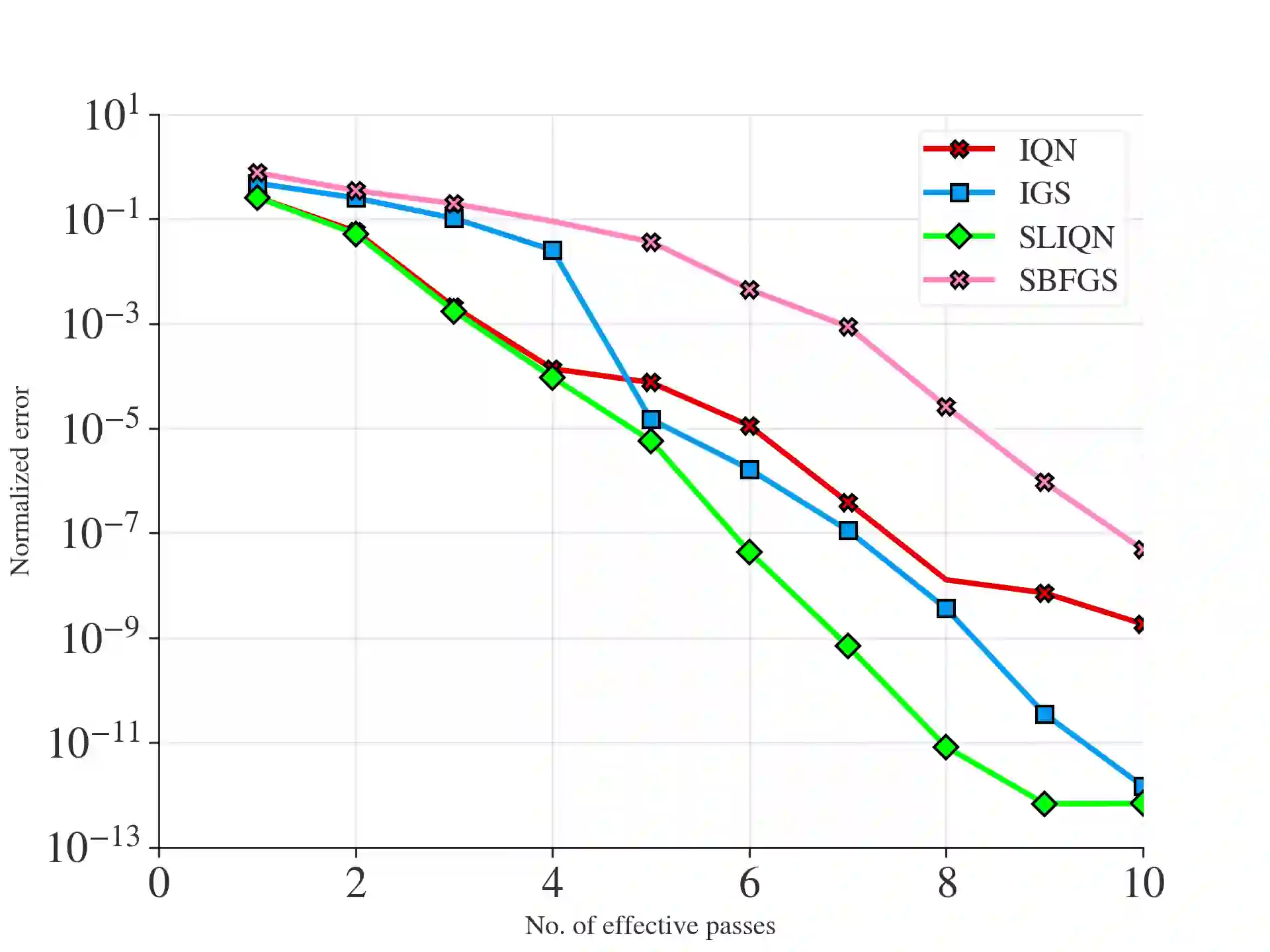
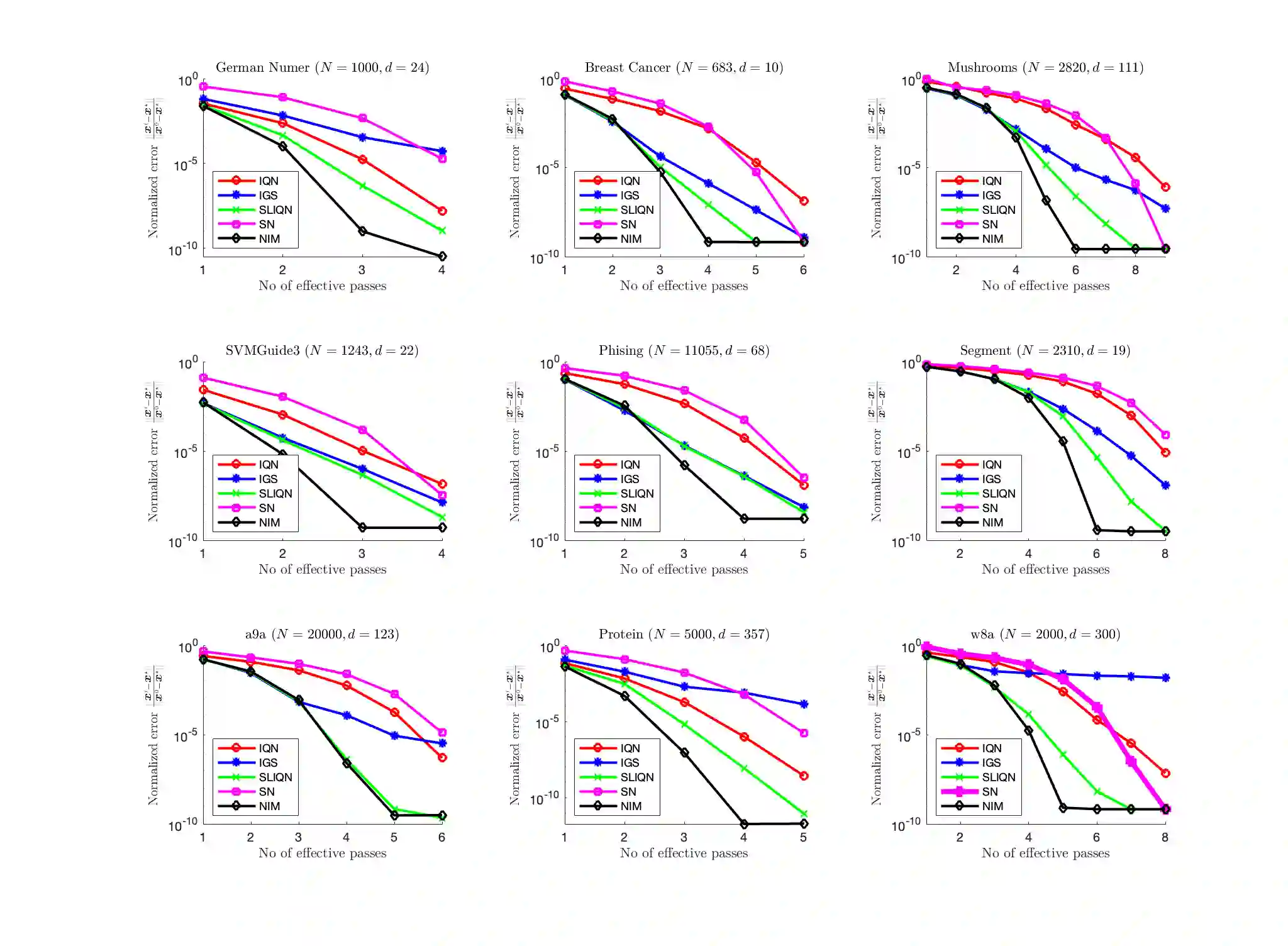
The problem of minimizing the sum of $n$ functions in $d$ dimensions is ubiquitous in machine learning and statistics. In many applications where the number of observations $n$ is large, it is necessary to use incremental or stochastic methods, as their per-iteration cost is independent of $n$. Of these, Quasi-Newton (QN) methods strike a balance between the per-iteration cost and the convergence rate. Specifically, they exhibit a superlinear rate with $O(d^2)$ cost in contrast to the linear rate of first-order methods with $O(d)$ cost and the quadratic rate of second-order methods with $O(d^3)$ cost. However, existing incremental methods have notable shortcomings: Incremental Quasi-Newton (IQN) only exhibits asymptotic superlinear convergence. In contrast, Incremental Greedy BFGS (IGS) offers explicit superlinear convergence but suffers from poor empirical performance and has a per-iteration cost of $O(d^3)$. To address these issues, we introduce the Sharpened Lazy Incremental Quasi-Newton Method (SLIQN) that achieves the best of both worlds: an explicit superlinear convergence rate, and superior empirical performance at a per-iteration $O(d^2)$ cost. SLIQN features two key changes: first, it incorporates a hybrid strategy of using both classic and greedy BFGS updates, allowing it to empirically outperform both IQN and IGS. Second, it employs a clever constant multiplicative factor along with a lazy propagation strategy, which enables it to have a cost of $O(d^2)$. Additionally, our experiments demonstrate the superiority of SLIQN over other incremental and stochastic Quasi-Newton variants and establish its competitiveness with second-order incremental methods.
翻译:最小化$d$维空间中$n$个函数之和的问题在机器学习和统计学中普遍存在。在许多观测数$n$较大的应用中,必须采用增量或随机方法,因为其每次迭代的计算成本与$n$无关。在这些方法中,拟牛顿(QN)方法在每次迭代成本与收敛速度之间取得了平衡。具体而言,与一阶方法的线性收敛速度(成本为$O(d)$)和二阶方法的二次收敛速度(成本为$O(d^3)$)相比,拟牛顿方法以$O(d^2)$的成本实现了超线性收敛速度。然而,现有增量方法存在显著缺陷:增量拟牛顿(IQN)仅具有渐近超线性收敛性;而增量贪心BFGS(IGS)虽具有显式超线性收敛性,但经验性能较差且每次迭代成本为$O(d^3)$。为解决这些问题,我们提出了锐化懒惰增量拟牛顿法(SLIQN),该方法实现了两全其美:具有显式超线性收敛速度,同时以每次迭代$O(d^2)$的成本展现出卓越的经验性能。SLIQN包含两项关键改进:首先,它采用了结合经典BFGS更新与贪心BFGS更新的混合策略,使其在经验上优于IQN和IGS。其次,它利用巧妙的常数乘数因子与惰性传播策略,从而将成本降低至$O(d^2)$。此外,我们的实验证明了SLIQN相对于其他增量和随机拟牛顿变体的优越性,并确立了其与二阶增量方法的竞争力。