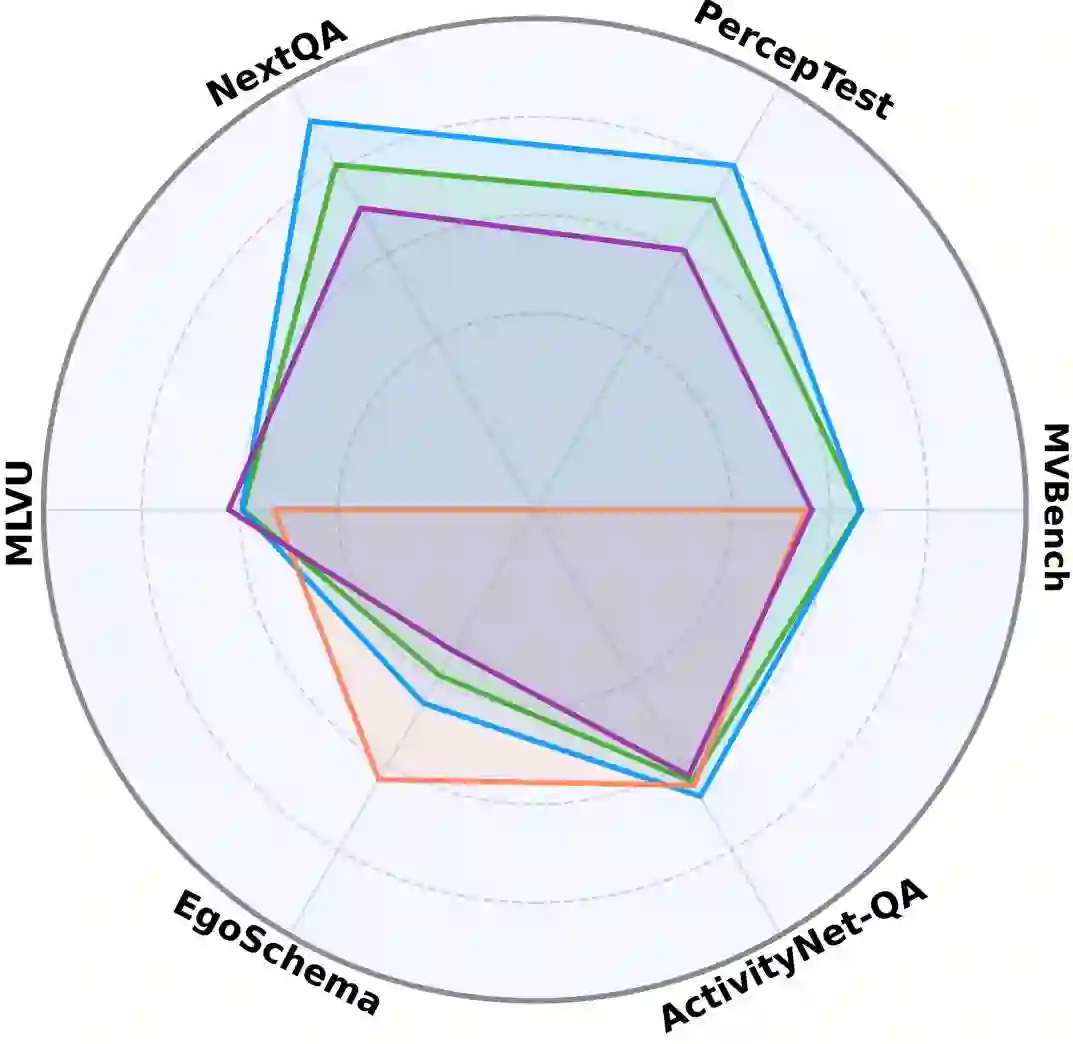
Video understanding models often struggle with high computational requirements, extensive parameter counts, and slow inference speed, making them inefficient for practical use. To tackle these challenges, we propose Mobile-VideoGPT, an efficient multimodal framework designed to operate with fewer than a billion parameters. Unlike traditional video large multimodal models (LMMs), Mobile-VideoGPT consists of lightweight dual visual encoders, efficient projectors, and a small language model (SLM), enabling real-time throughput. To further improve efficiency, we present an Attention-Based Frame Scoring mechanism to select the key-frames, along with an efficient token projector that prunes redundant visual tokens and preserves essential contextual cues. We evaluate our model across well-established six video understanding benchmarks (e.g., MVBench, EgoSchema, NextQA, and PercepTest). Our results show that Mobile-VideoGPT-0.5B can generate up to 46 tokens per second while outperforming existing state-of-the-art 0.5B-parameter models by 6 points on average with 40% fewer parameters and more than 2x higher throughput. Our code and models are publicly available at: https://github.com/Amshaker/Mobile-VideoGPT.
翻译:视频理解模型通常面临计算需求高、参数量大、推理速度慢的挑战,导致其在实际应用中效率低下。为应对这些挑战,我们提出了Mobile-VideoGPT,一种高效的多模态框架,其设计参数量少于十亿。与传统视频大型多模态模型(LMMs)不同,Mobile-VideoGPT由轻量级双视觉编码器、高效投影器和小型语言模型(SLM)组成,能够实现实时吞吐。为进一步提升效率,我们提出了一种基于注意力的帧评分机制来选择关键帧,并采用一种高效的令牌投影器来修剪冗余的视觉令牌,同时保留必要的上下文线索。我们在六个成熟的视频理解基准测试(如MVBench、EgoSchema、NextQA和PercepTest)上评估了我们的模型。结果表明,Mobile-VideoGPT-0.5B每秒可生成多达46个令牌,同时在平均性能上超越现有最先进的0.5B参数模型6个百分点,且参数量减少40%,吞吐量提升超过2倍。我们的代码和模型已在以下网址公开:https://github.com/Amshaker/Mobile-VideoGPT。