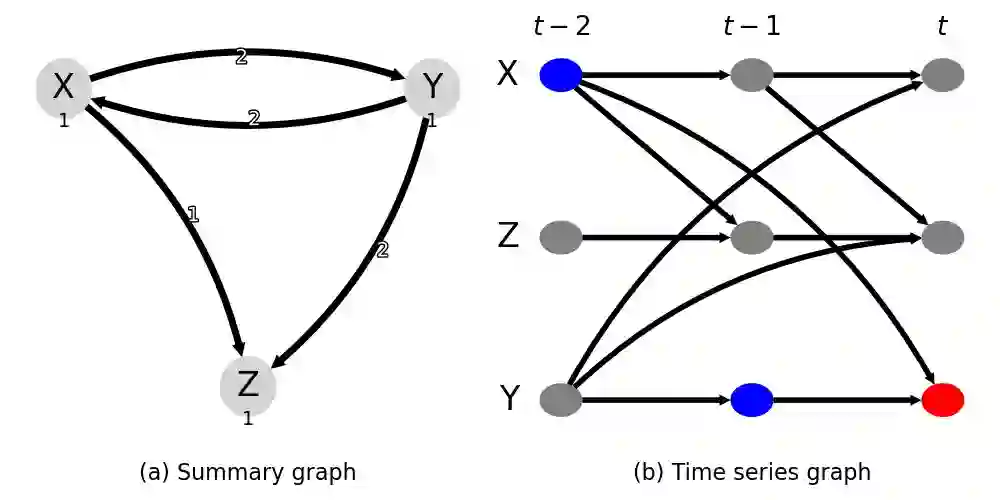
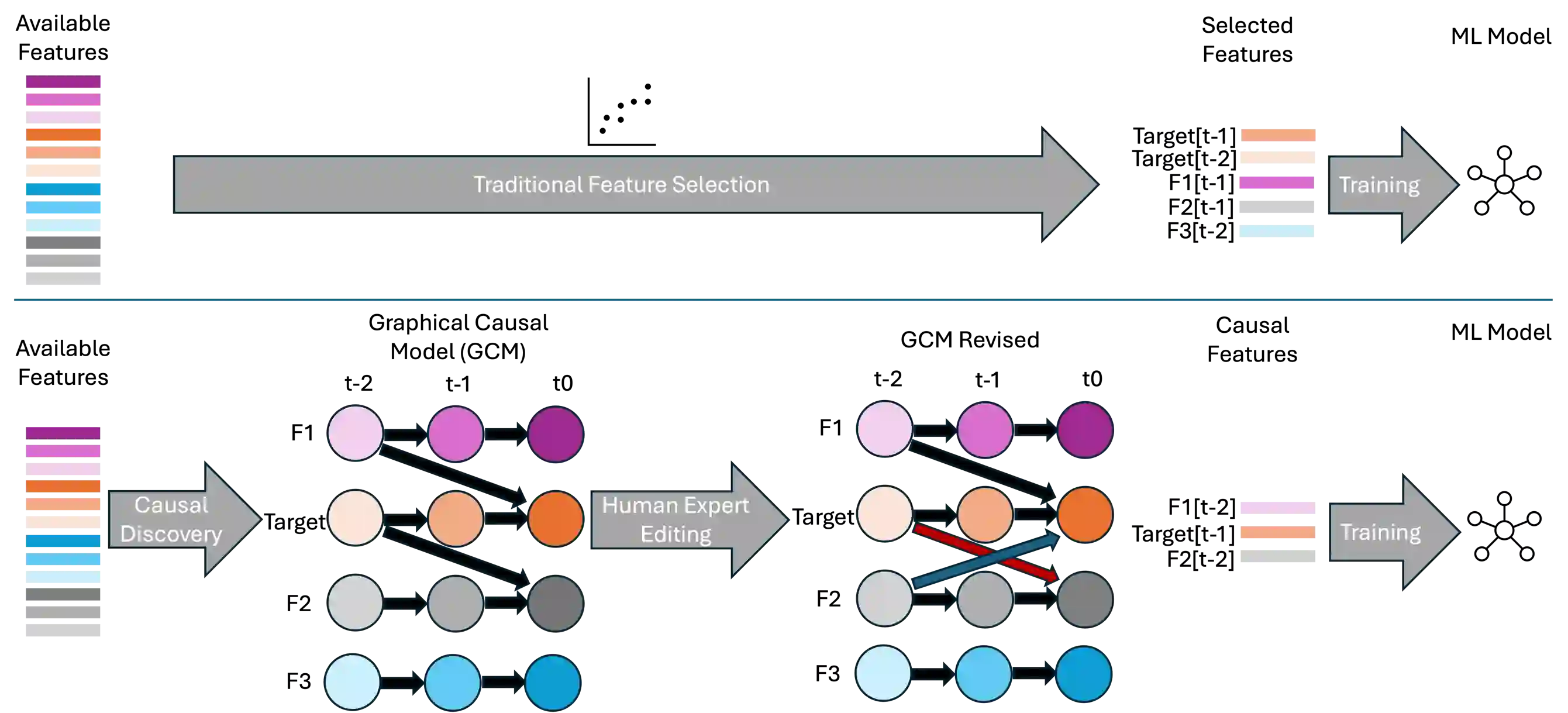
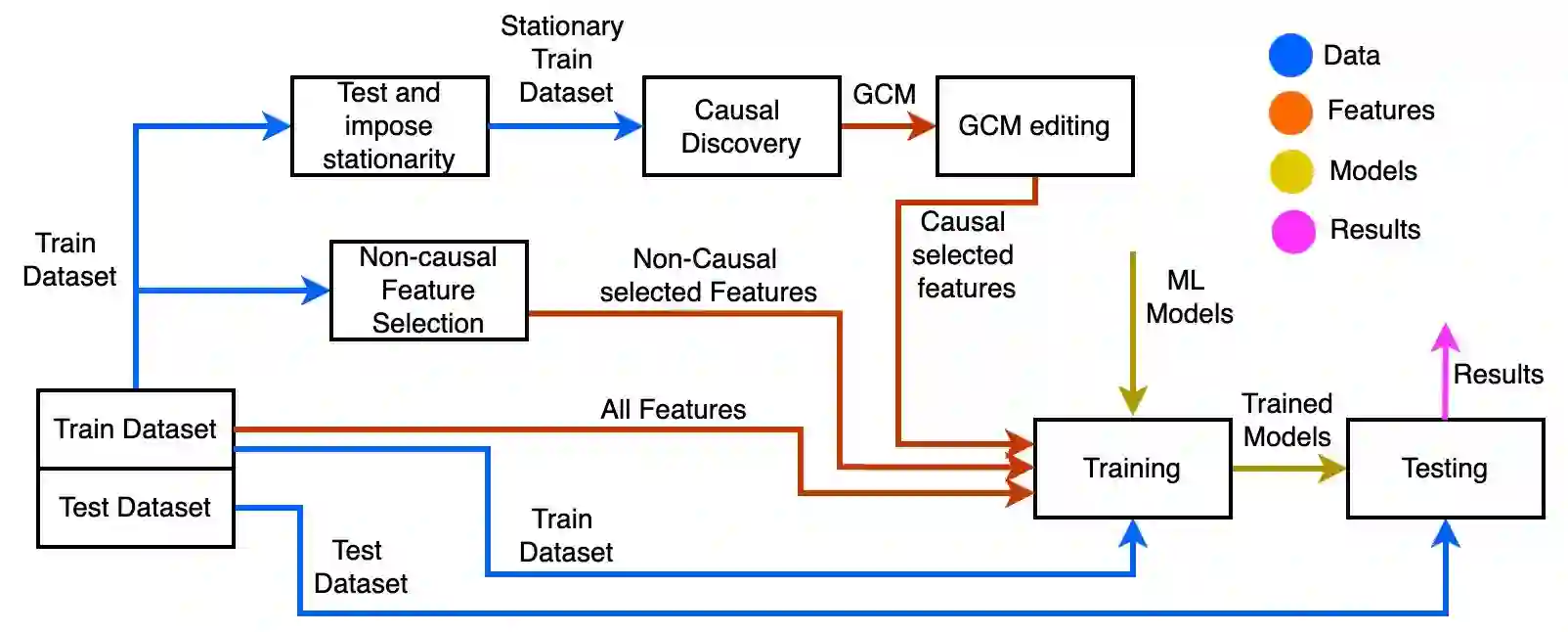
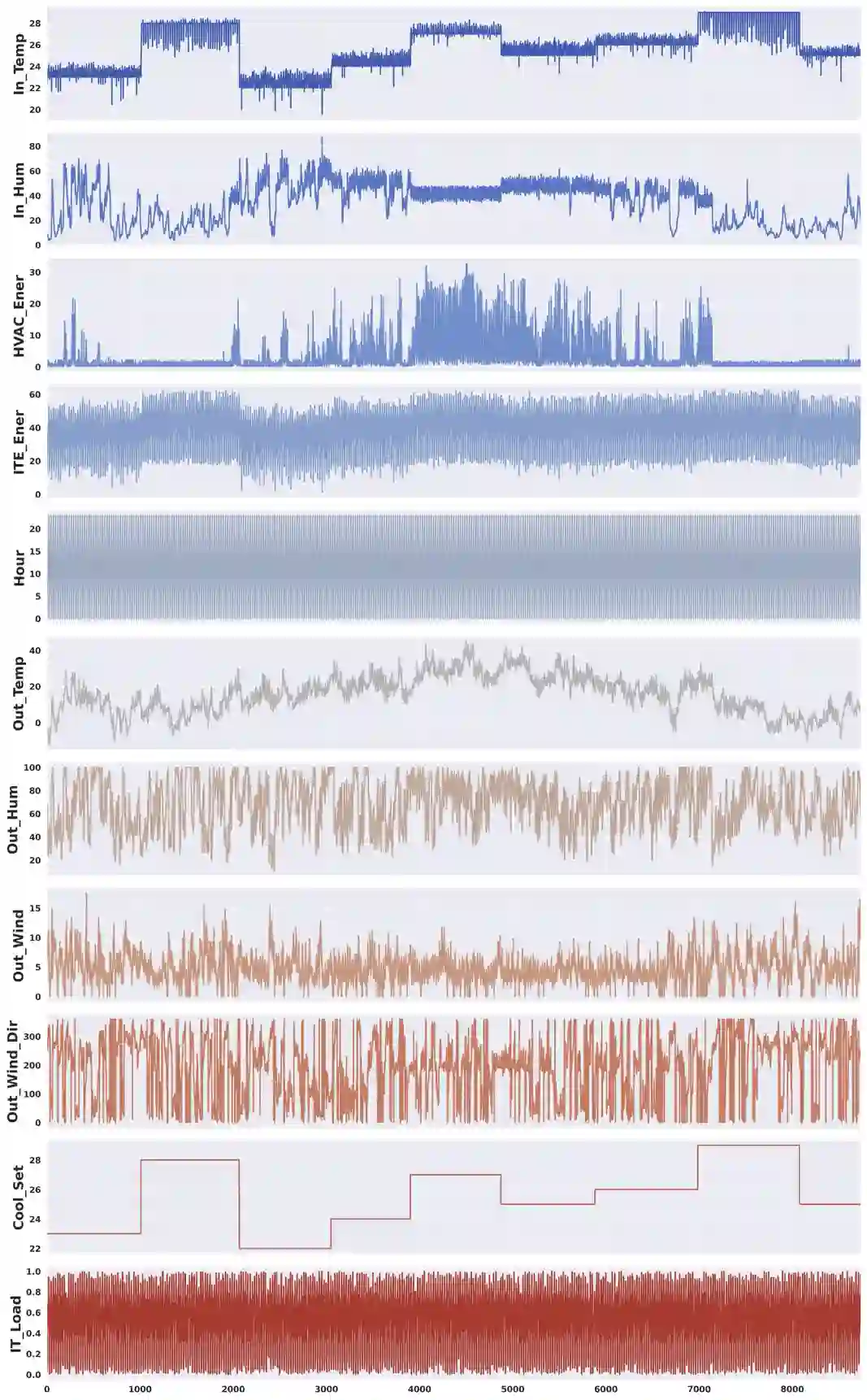
Classical machine learning techniques often struggle with overfitting and unreliable predictions when exposed to novel conditions. Introducing causality into the modelling process offers a promising way to mitigate these challenges by enhancing interpretability and predictive reliability. However, constructing an initial causal graph manually using domain knowledge is a time-consuming, particularly in complex time series with numerous variables. To address this, causal discovery algorithms can provide a preliminary causal structure that domain experts can refine. This study investigates causal feature selection with domain knowledge using a data centre system as an example. We use simulated time-series data to compare different causal feature selection with traditional machine-learning feature selection methods. Our results show that predictions based on causal features are more robust and interpretable compared to those derived from traditional methods. These findings underscore the potential of combining causal discovery algorithms with human expertise to improve machine learning applications.
翻译:传统机器学习技术在面对新条件时,常因过拟合和预测不可靠而受限。将因果性引入建模过程,通过提升可解释性与预测可靠性,为解决这些挑战提供了可行途径。然而,基于领域知识手动构建初始因果图耗时费力,在变量众多的复杂时间序列中尤为明显。为此,因果发现算法可提供初步因果结构供领域专家优化。本研究以数据中心系统为例,探讨结合领域知识的因果特征选择方法。我们使用模拟时间序列数据,比较不同因果特征选择与传统机器学习特征选择方法。结果表明,基于因果特征的预测相较于传统方法更具鲁棒性和可解释性。这些发现凸显了将因果发现算法与人类专业知识相结合以改进机器学习应用的潜力。