
本文源于北约科技组织的技术论文,旨在探讨如何将大型语言模型(LLM)这一新兴技术,与兵棋推演相结合,以解决传统兵棋推演在可扩展性、沉浸感和专家依赖性方面面临的挑战。作者团队在2024年北约TIDE黑客马拉松期间开发了一个原型系统,并将其应用于一个定量的多域作战(MDO)兵棋推演场景中,以此作为研究载体。核心在于通过这个原型,具体化地展示和评估了LLM在兵棋推演中的多种应用潜力与现有局限。
引言
本文开篇阐述了兵棋推演在军事训练、战略规划和战备中的重要性,以及数字兵棋在模拟高节奏、复杂的多域作战场景中的价值。同时,也指出了当前兵棋推演面临的挑战:模拟日益数字化的军事世界的网络化依赖关系和现实场景变得越来越困难。在此背景下,LLM因其强大的自然语言处理和内容生成能力,展现出变革潜力。本文的研究问题聚焦于:LLM如何通过解决可扩展性、沉浸感和领域专家稀缺性等具体挑战,来增强面向多域作战的兵棋推演。研究将通过在黑客马拉松开发的原型进行演示和讨论。
方法论
本部分详细介绍了研究采用的方法。
-
兵棋概念设计:
- 背景:设计参考了《北约兵棋推演手册》和《德国联邦国防军兵棋推演手册》。
- 场景设定:玩家扮演波罗的海地区的防御方,对抗一个试图夺取多个战略要地的进攻方。推演在军事(陆、海、空)、政治、经济、网络和太空等多个领域展开。
- 核心机制:
- 游戏进行10轮,每轮攻防双方各可执行3个行动,每个行动通过打出“游戏卡牌”来实现。
- 卡牌分为军事、网络混合、政治经济三类,影响四个核心指标:升级分数(紧张程度)、士气分数(公众支持)、通信分数(指挥控制能力)、资源分数(行动所需资源)。
- 进攻方在条件成熟时可对7个战略要地之一发起攻击,触发受上述分数影响的模拟战斗。
- 胜利条件:防御方需在第10轮结束时,确保通信和士气分数高于30%,资源分数大于0,并控制至少4个战略要地,且升级分数未达到10级(否则视为双方均失败)。
-
技术实现:
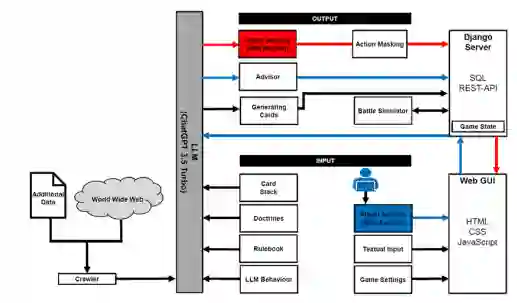
- 系统架构:采用REST架构,后端使用Python和Django框架,前端使用CSS、JavaScript和HTML。
- LLM集成:核心使用了ChatGPT 3.5 Turbo(通过北约软件工厂的Azure OpenAI服务访问),因其性能稳定且对军事相关查询限制较少。同时也测试了本地模型(Mistral 7b等)。
- 数据处理:LLM可通过嵌入自定义数据集、网络爬虫或解析PDF文档来获取特定信息,增强了其作为信息源的能力。
- 此部分旨在通过开发一个最小可行产品(MVP),获得LLM与兵棋结合的直接经验。
结果
本部分以汇总形式,具体介绍了LLM在原型兵棋中的三个核心应用案例(即解决引言中提出的三大挑战):
-
可扩展性:
- 应用:利用LLM自动生成新的游戏卡牌。将现有卡牌作为示例提供给LLM,并提示其生成主题上参考近年真实混合攻击事件(如2015年德国联邦议院网络攻击)的新卡牌。
- 过程:LLM能生成包含场景描述、卡牌类别、资源成本、对各项分数影响等属性的新卡牌。
- 人工角色:生成的卡牌需经人工审查和调整,以确保点数平衡和游戏公平性。此功能用于游戏开始前的设置阶段,而非实时生成。
-
沉浸感:
- 应用:利用LLM进行“行动掩饰”,以增强沉浸感和“去游戏化”体验。
- 实现方式:不直接显示对手打出的卡牌或分数变化,而是让LLM扮演冲突地区的记者,在每轮结束后撰写简短的新闻头条和文章,间接、叙事性地描述对手的行动,并将其置于更广阔的世界事件背景中。
- 输入:LLM会获得双方当前分数和最近回合行动的信息,以便进行情境化解读。还可要求其引用历史事件并进行评估。
-
领域专家稀缺性:
- 背景:兵棋的设计、推演和引导(“白方”角色)高度依赖领域专家,成本高且专家资源有限。
- 应用1 - 虚拟引导员:使用LLM作为虚拟引导员,回答玩家关于游戏规则的疑问,加速学习过程,从而减少对真人引导员的依赖。
- 应用2 - 决策顾问:玩家可通过聊天窗口与一个由LLM扮演的“顾问”对话。该顾问能基于特定知识(如访问《北约行动评估手册》)提供内容相关的指导和建议,帮助玩家在大量文档中快速获取决策相关信息。
**讨论 **
本部分对上述应用案例的结果进行了深入分析和反思,是论文的精华所在,揭示了机遇与挑战。
-
关于可扩展性:
- 价值:肯定使用LLM生成游戏内容(如卡牌)是可行的,并能带来实际增值。它能灵活创建新内容,有助于让决策者为复杂多变的冲突环境做准备。
- 局限:内容生成的适用性取决于所需内容的范围和复杂程度(例如,生成地图比生成卡牌更困难)。当前方法较为基础,更广泛或自动化的应用仍需探索。生成的内容需要专家审查和验证。
-
关于沉浸感:
- 创新性:提出的“行动掩饰”方法是一种增强兵棋沉浸感的新方法。它模拟了现实中信息不透明、只能间接感知敌方行动(如通过媒体报道停电影响,而非明确得知攻击来源)的特点。
- 灵活性:此功能可以选择性地替代或补充特定分数的直接显示,甚至可以完全取代分数显示,让玩家通过叙事来追踪局势发展。
-
关于信息提供:
- 能力:LLM可作为交互式参考,链接到相关信息或方法论。
- 局限:目前无法取代基于丰富经验的真人专家来处理复杂情况。同时指出,现有LLM的训练数据多基于日常语言,缺乏军事术语数据,存在语言限制。文中提及德国联邦国防军正在研究如何用AI/LLM加速和改进陆军指挥流程。
-
关于引导员:
- 优势:认为用LLM作为引导员是合理且可行的。其交互性优于传统数字教程,能针对玩家的具体疑惑和当前游戏状态进行详细解释。这能显著减少对真人引导员的数量和时间的需求,提升游戏的可玩性。
- 心理优势:数字顾问能减轻玩家因担心显得理解力不足而不愿重复提问的心理负担,避免因误解规则而采取错误行动。
-
关于模拟敌方:
- 主要局限:这是讨论中篇幅最长、反思最深刻的部分。作者发现,在定量兵棋的严格约束下,LLM模拟的对手行为过于简单化,例如过分偏好军事和攻击性行动,缺乏细致策略。
- 原因分析:
- 任务设计:要让AI表现出令人信服的行为,需要极其精确的任务和行为描述(提示工程),以及深思熟虑的游戏设计。
- 结构性约束:离散行动和状态空间的定量兵棋本身对可能的行为施加了强大的结构性限制,这可能不适用于LLM的优势(开放式、定性推理)。作者认为,强化学习等其他AI方法可能更适合在此类设定下模拟敌方。
- 偏见问题:LLM可能因其训练数据而存在偏见,这引发了一个深刻问题:某些LLM是否由于其数据和训练过程,根本无法代表具有不同价值观和世界观的具体对手? 这个问题尚未解决。
- 潜在价值:尽管存在局限,但AI驱动的对手为超越传统思维定式提供了可能性,可能带来替代性和非常规的思维方式。
结论
- 核心建议:应首先启动小规模、定义明确的LLM应用用例(如内容生成、行动掩饰),而非追求大规模复杂应用。LLM目前应承担辅助性角色,而非决定游戏胜负的复杂功能。
- 本文贡献:在于识别了先前被忽视的用例,并将现有用例应用于定量多域作战兵棋这一新场景。提出了一些优先考虑实用性而非复杂性的简单可靠方法。
- 总体评价:作者对LLM的应用持相对保守和谨慎的态度,部分原因是定量多域作战的约束限制了LLM固有优势的充分发挥。他们认为,那些关于LLM在解决军事政治战略问题上将超越人类能力的常见比较缺乏依据。
- 未来方向:指出教育性兵棋中LLM的应用尚未充分探索,在引导员功能和改善学习过程方面仍有潜力。未来可研究LLM生成更复杂、平衡的游戏内容的能力,以及LLM在兵棋分析和评估中的应用。
成为VIP会员查看完整内容
相关内容

Arxiv
66+阅读 · 2023年5月31日


最新内容
相关VIP内容
相关资讯