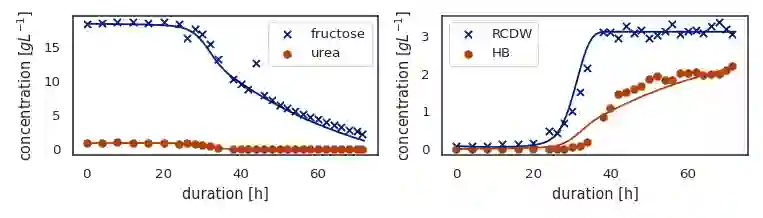
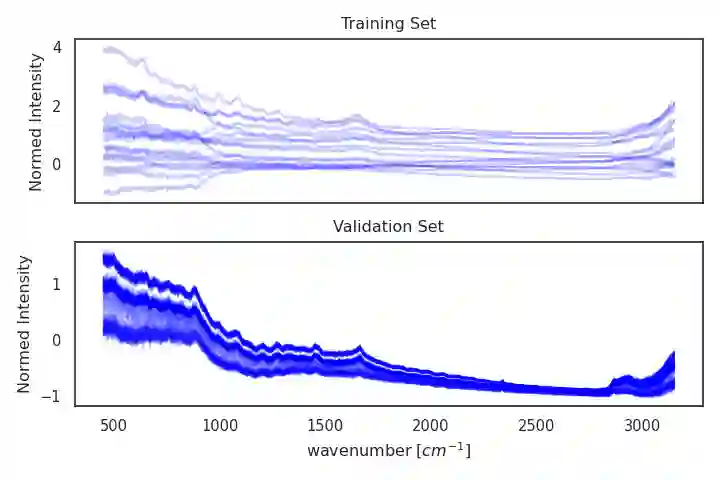
In biotechnology Raman Spectroscopy is rapidly gaining popularity as a process analytical technology (PAT) that measures cell densities, substrate- and product concentrations. As it records vibrational modes of molecules it provides that information non-invasively in a single spectrum. Typically, partial least squares (PLS) is the model of choice to infer information about variables of interest from the spectra. However, biological processes are known for their complexity where convolutional neural networks (CNN) present a powerful alternative. They can handle non-Gaussian noise and account for beam misalignment, pixel malfunctions or the presence of additional substances. However, they require a lot of data during model training, and they pick up non-linear dependencies in the process variables. In this work, we exploit the additive nature of spectra in order to generate additional data points from a given dataset that have statistically independent labels so that a network trained on such data exhibits low correlations between the model predictions. We show that training a CNN on these generated data points improves the performance on datasets where the annotations do not bear the same correlation as the dataset that was used for model training. This data augmentation technique enables us to reuse spectra as training data for new contexts that exhibit different correlations. The additional data allows for building a better and more robust model. This is of interest in scenarios where large amounts of historical data are available but are currently not used for model training. We demonstrate the capabilities of the proposed method using synthetic spectra of Ralstonia eutropha batch cultivations to monitor substrate, biomass and polyhydroxyalkanoate (PHA) biopolymer concentrations during of the experiments.
翻译:在生物技术领域,拉曼光谱作为过程分析技术(PAT)正迅速普及,用于测量细胞密度、底物浓度及产物浓度。该技术通过记录分子振动模式,可在单个光谱中非侵入性地获取这些信息。通常,偏最小二乘法(PLS)是从光谱中推断目标变量信息的首选模型。然而,生物过程以复杂性著称,此时卷积神经网络(CNN)成为一种强有力的替代方案。CNN能够处理非高斯噪声,并应对光束偏移、像素故障或额外物质存在等情况。但CNN在模型训练时需要大量数据,且会捕捉过程变量中的非线性依赖关系。本研究利用光谱的加和性,从给定数据集中生成具有统计独立标签的额外数据点,使基于此类数据训练的网络的模型预测之间呈现低相关性。我们证明,在这些生成数据点上训练CNN能提升模型性能,尤其适用于标注相关性不同于原始训练数据集的场景。该数据增强技术使我们能够将光谱作为训练数据复用于呈现不同相关性的新场景。额外数据有助于构建更优、更鲁棒的模型。这对于存在大量历史数据但尚未用于模型训练的场景具有重要意义。我们通过Ralstonia eutropha分批培养的合成光谱,展示了该方法在实验过程中监测底物、生物质及聚羟基脂肪酸酯(PHA)生物聚合物浓度的能力。