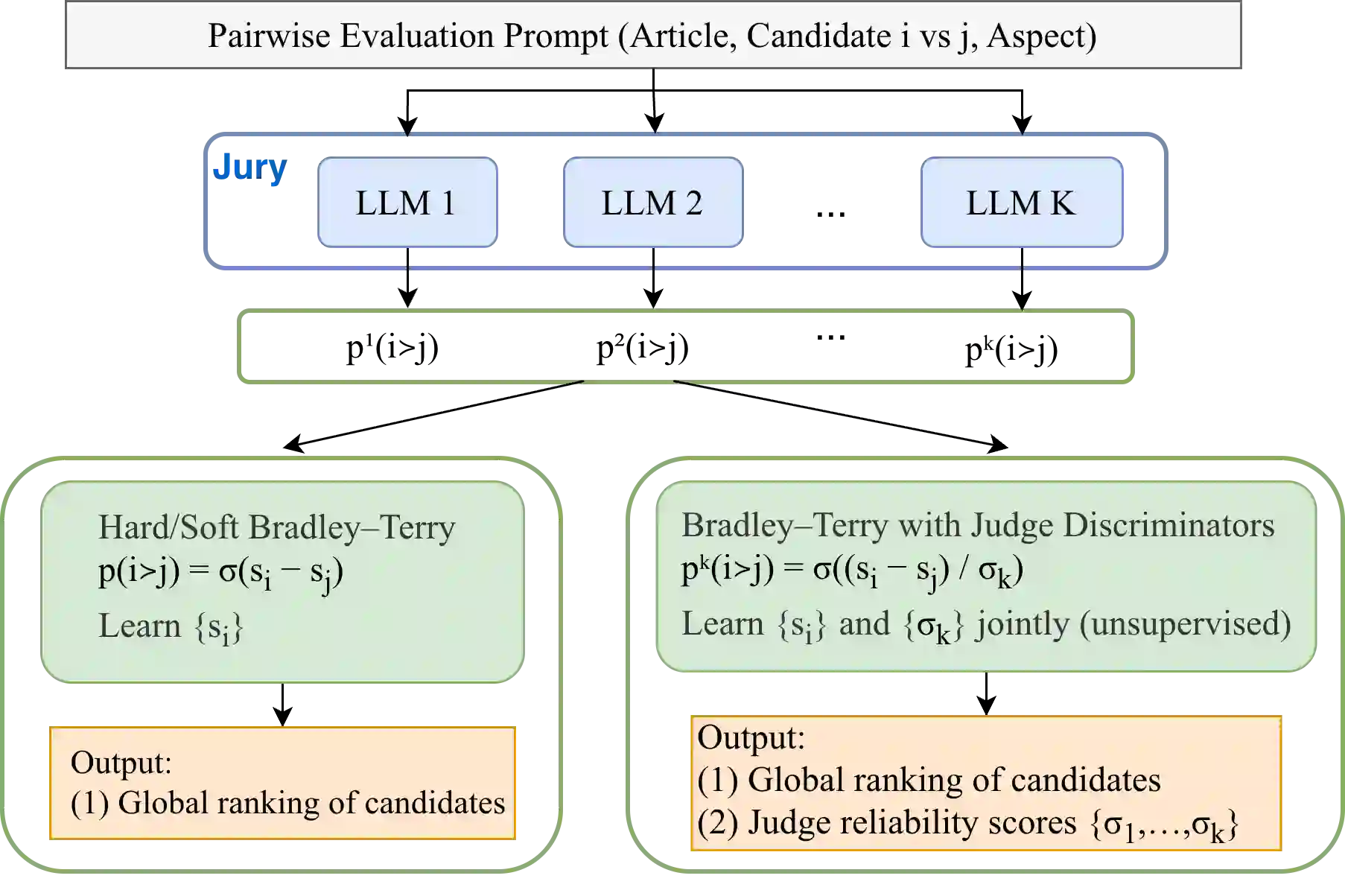
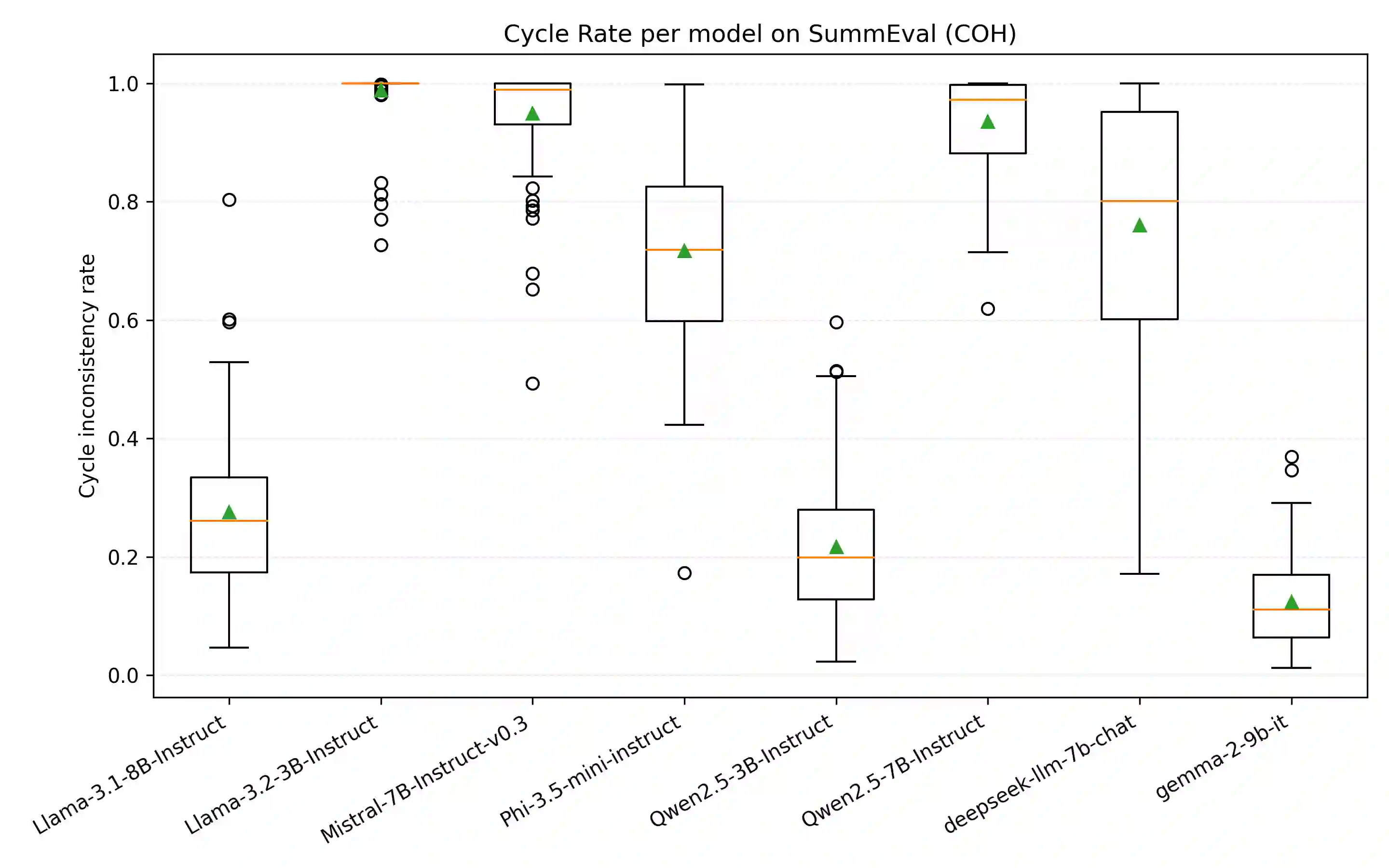
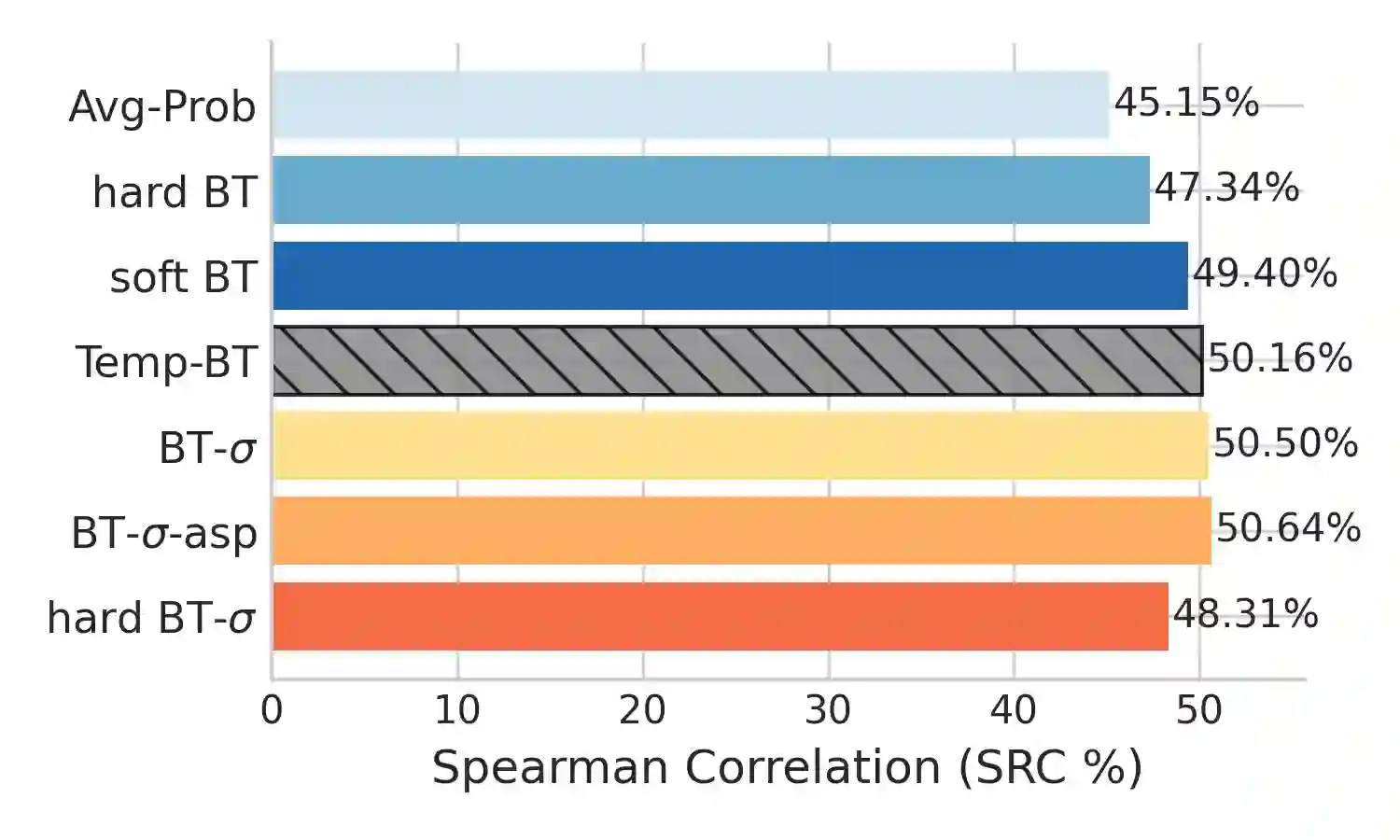
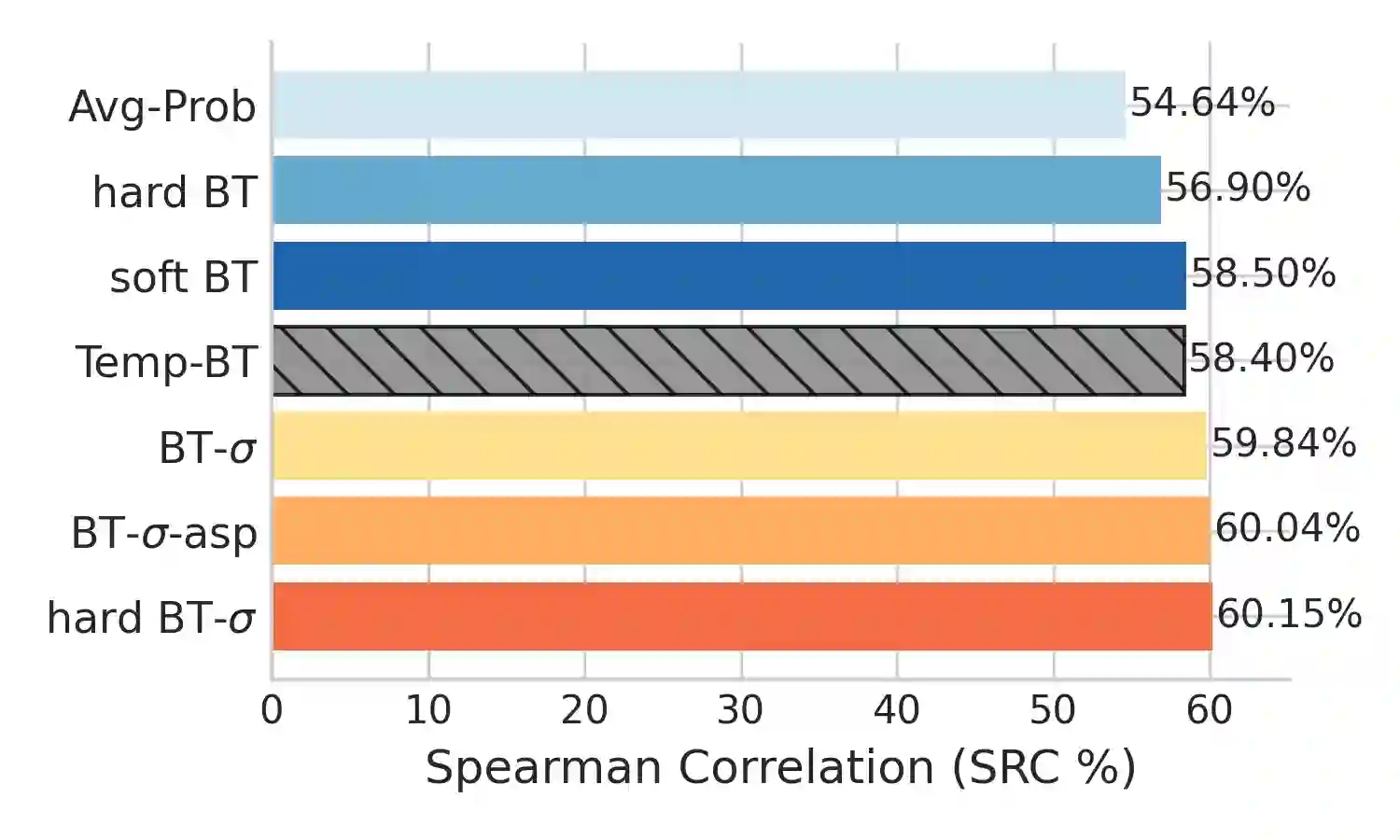
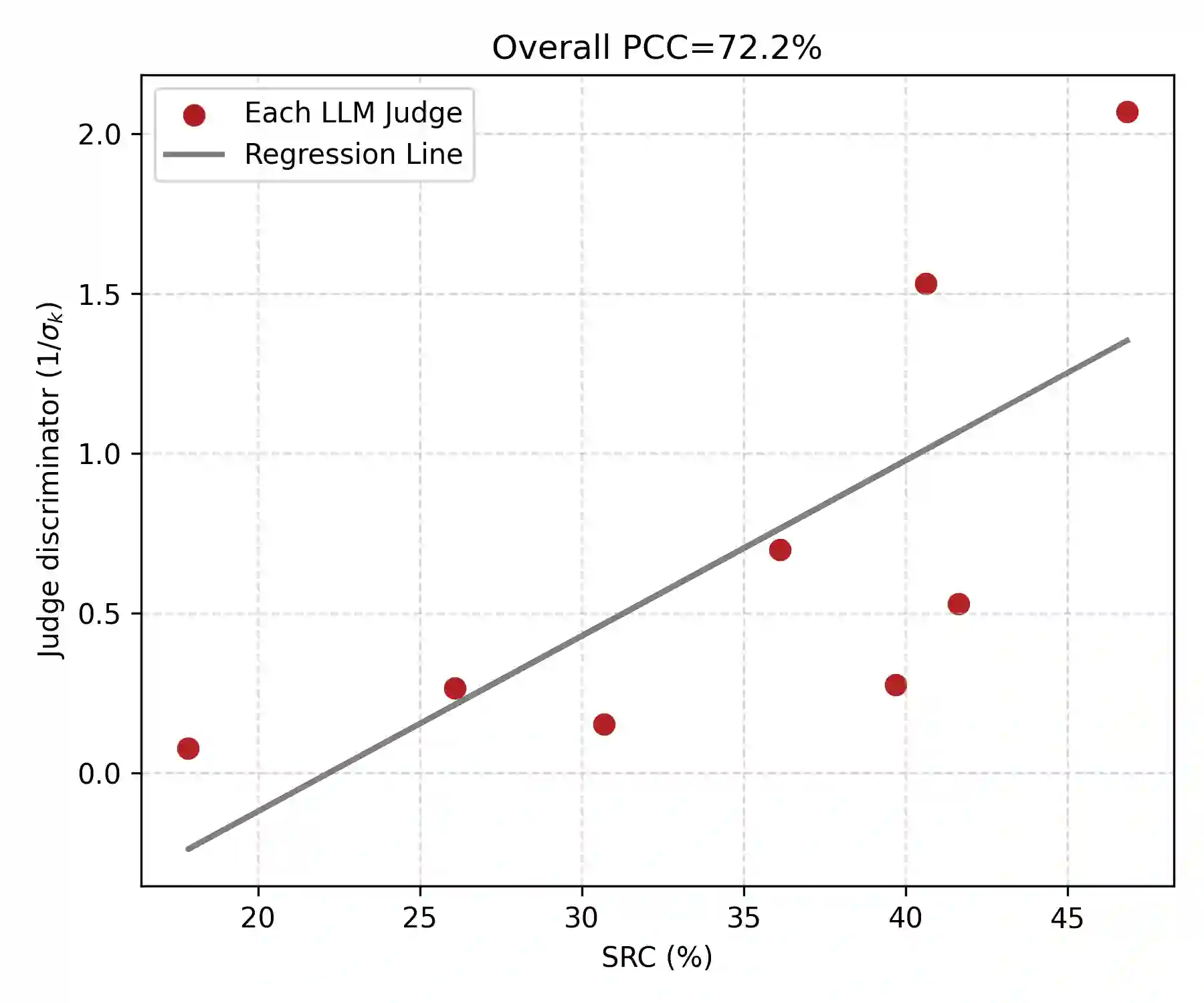
Large language models (LLMs) are increasingly applied as automatic evaluators for natural language generation assessment often using pairwise comparative judgements. Existing approaches typically rely on single judges or aggregate multiple judges assuming equal reliability. In practice, LLM judges vary substantially in performance across tasks and aspects, and their judgment probabilities may be biased and inconsistent. Furthermore, human-labelled supervision for judge calibration may be unavailable. We first empirically demonstrate that inconsistencies in LLM comparison probabilities exist and show that it limits the effectiveness of direct probability-based ranking. To address this, we study the LLM-as-a-jury setting and propose BT-sigma, a judge-aware extension of the Bradley-Terry model that introduces a discriminator parameter for each judge to jointly infer item rankings and judge reliability from pairwise comparisons alone. Experiments on benchmark NLG evaluation datasets show that BT-sigma consistently outperforms averaging-based aggregation methods, and that the learned discriminator strongly correlates with independent measures of the cycle consistency of LLM judgments. Further analysis reveals that BT-sigma can be interpreted as an unsupervised calibration mechanism that improves aggregation by modelling judge reliability.
翻译:大型语言模型(LLM)越来越多地被用作自然语言生成评估的自动评测器,通常采用成对比较判断。现有方法通常依赖单一评委或假设多个评委具有同等可靠性而进行简单聚合。实际上,LLM评委在不同任务和评估维度上的表现存在显著差异,其判断概率可能存在偏差且不一致。此外,用于评委校准的人工标注监督数据可能难以获取。我们首先通过实证证明了LLM比较概率存在不一致性,并表明这会限制基于直接概率排序的有效性。为解决此问题,我们研究了LLM作为陪审团的场景,提出了BT-sigma——这是Bradley-Terry模型的评委感知扩展方法,通过为每位评委引入区分度参数,仅依据成对比较即可联合推断项目排序与评委可靠性。在自然语言生成评估基准数据集上的实验表明,BT-sigma始终优于基于平均的聚合方法,且学习到的区分度参数与LLM判断的循环一致性独立度量指标呈现强相关性。进一步分析揭示,BT-sigma可被解释为一种无监督校准机制,通过建模评委可靠性来改进聚合效果。