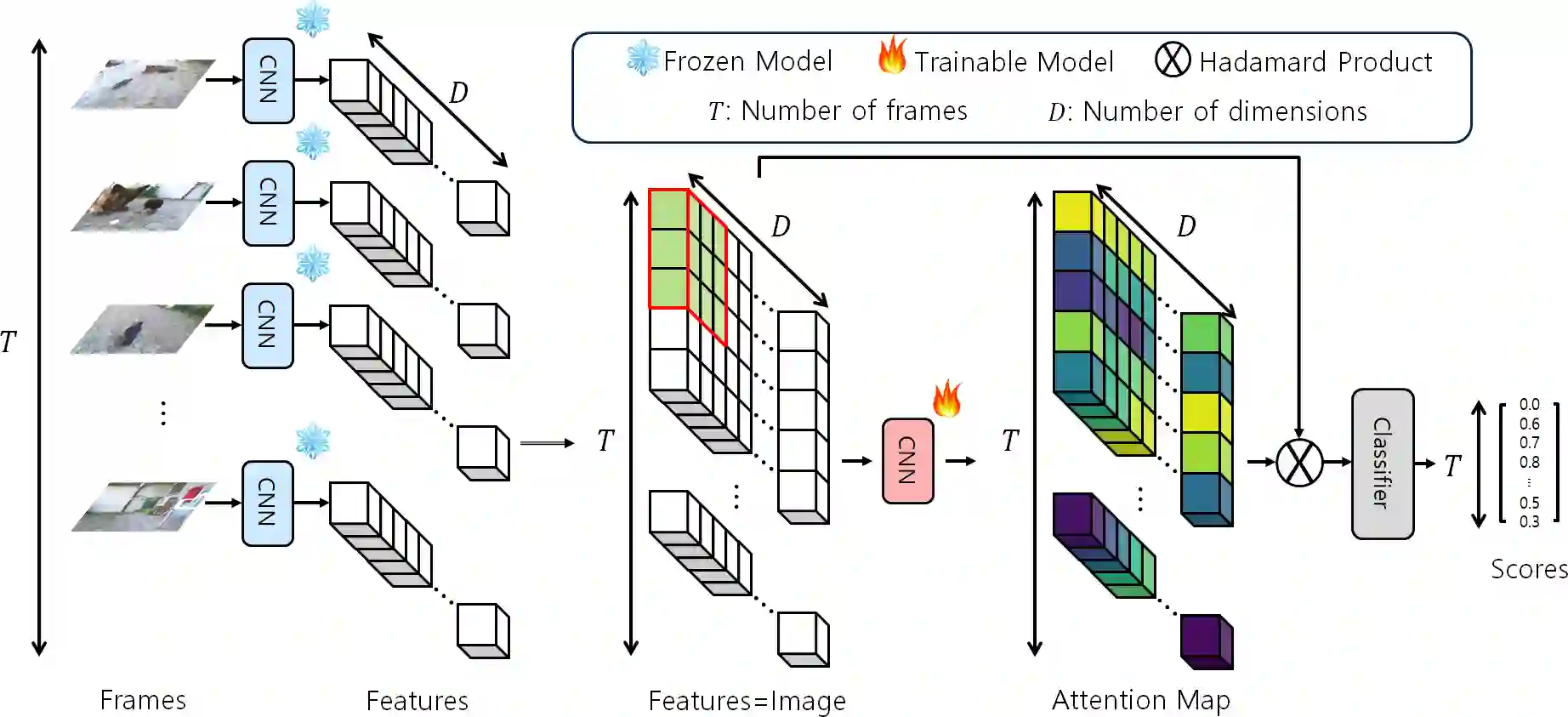
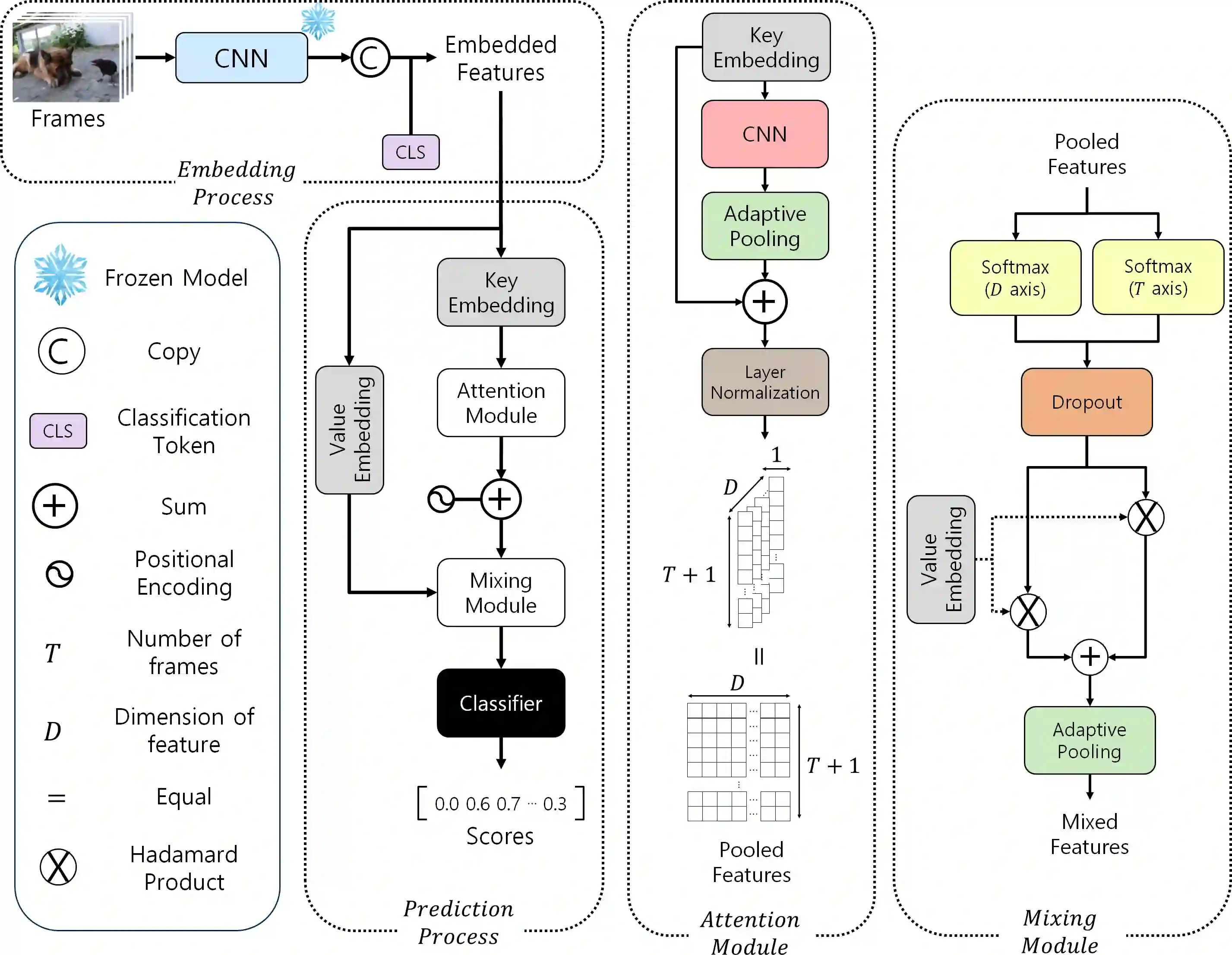
Video summarization aims to generate a concise representation of a video, capturing its essential content and key moments while reducing its overall length. Although several methods employ attention mechanisms to handle long-term dependencies, they often fail to capture the visual significance inherent in frames. To address this limitation, we propose a CNN-based SpatioTemporal Attention (CSTA) method that stacks each feature of frames from a single video to form image-like frame representations and applies 2D CNN to these frame features. Our methodology relies on CNN to comprehend the inter and intra-frame relations and to find crucial attributes in videos by exploiting its ability to learn absolute positions within images. In contrast to previous work compromising efficiency by designing additional modules to focus on spatial importance, CSTA requires minimal computational overhead as it uses CNN as a sliding window. Extensive experiments on two benchmark datasets (SumMe and TVSum) demonstrate that our proposed approach achieves state-of-the-art performance with fewer MACs compared to previous methods. Codes are available at https://github.com/thswodnjs3/CSTA.
翻译:摘要:视频摘要旨在生成视频的简洁表示,在保留其关键内容和重要时刻的同时缩减整体时长。尽管已有多种方法采用注意力机制处理长期依赖关系,但它们往往难以捕捉帧内蕴含的视觉显著性。为解决这一局限,我们提出一种基于CNN的时空注意力方法(CSTA),该方法将单视频中各帧的特征堆叠为类似图像的帧表示,并利用2D卷积神经网络(CNN)处理这些帧特征。我们的方法依赖CNN理解帧间与帧内关系,并借助其学习图像中绝对位置的能力发掘视频中的关键属性。与通过设计额外模块聚焦空间重要性而牺牲效率的先前工作不同,CSTA将CNN用作滑动窗口,仅需极低计算开销。在两个基准数据集(SumMe和TVSum)上的大量实验表明,与以往方法相比,所提方法在减少乘累加运算次数(MACs)的同时达到了最先进性能。代码见https://github.com/thswodnjs3/CSTA。