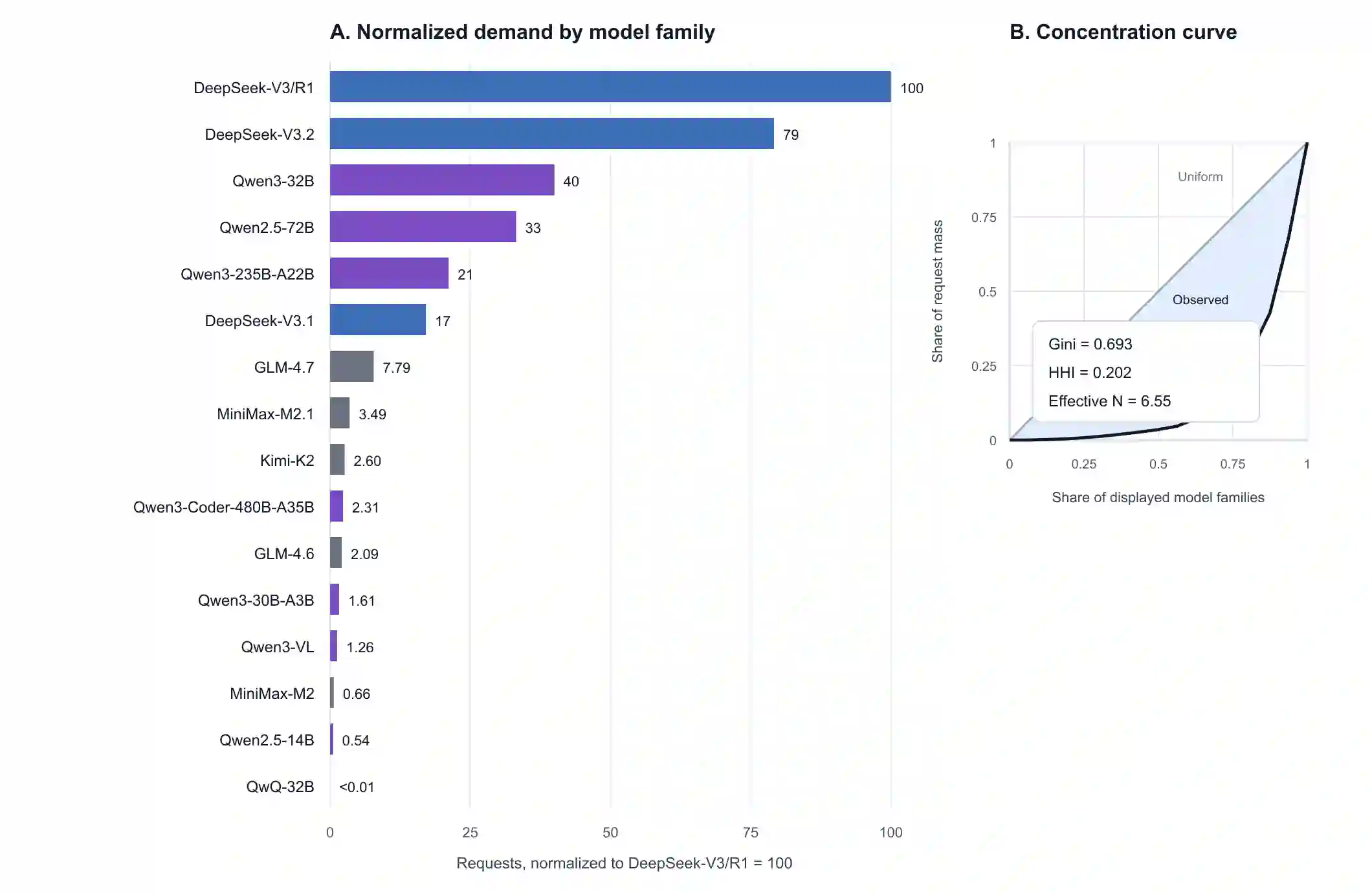
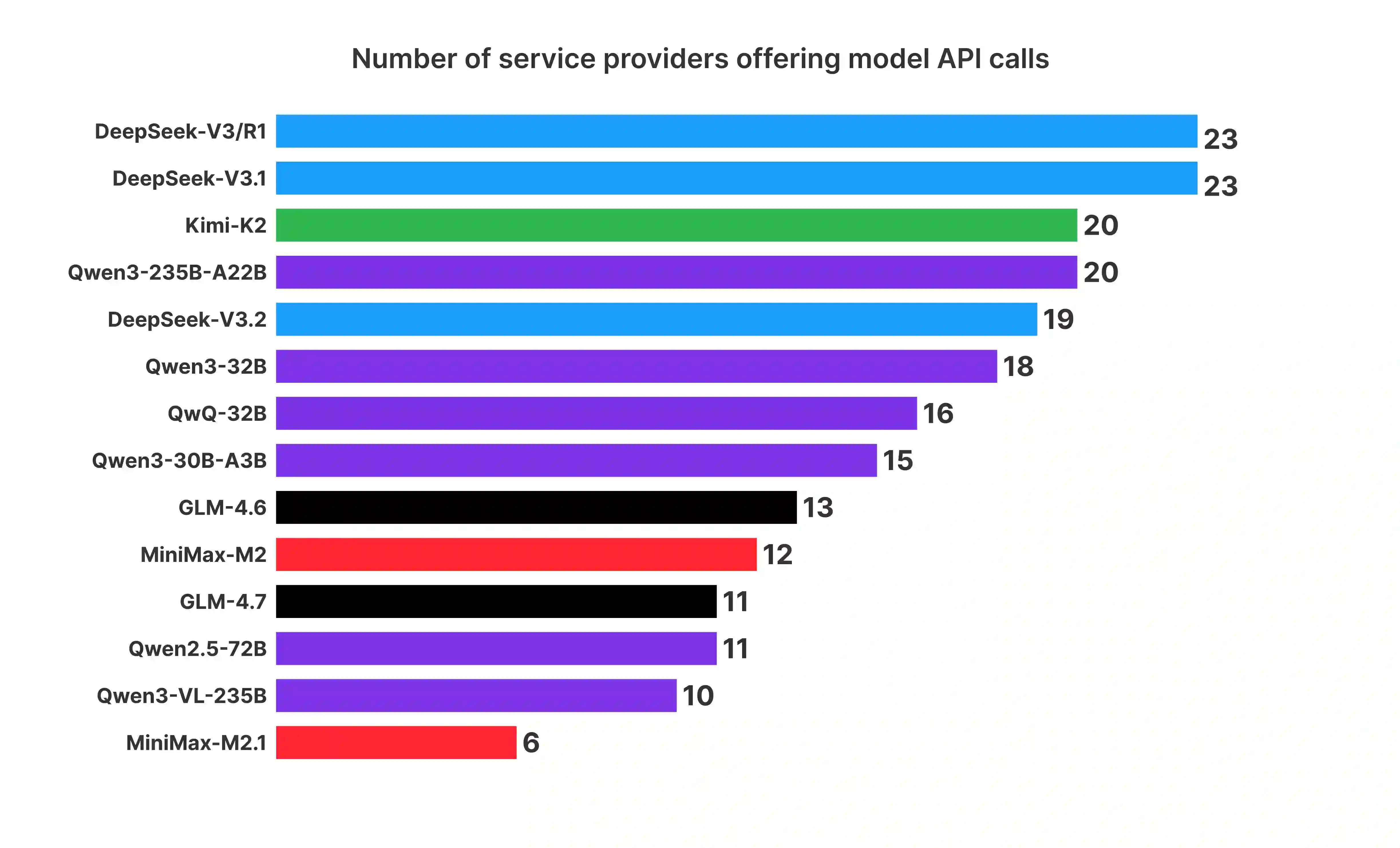
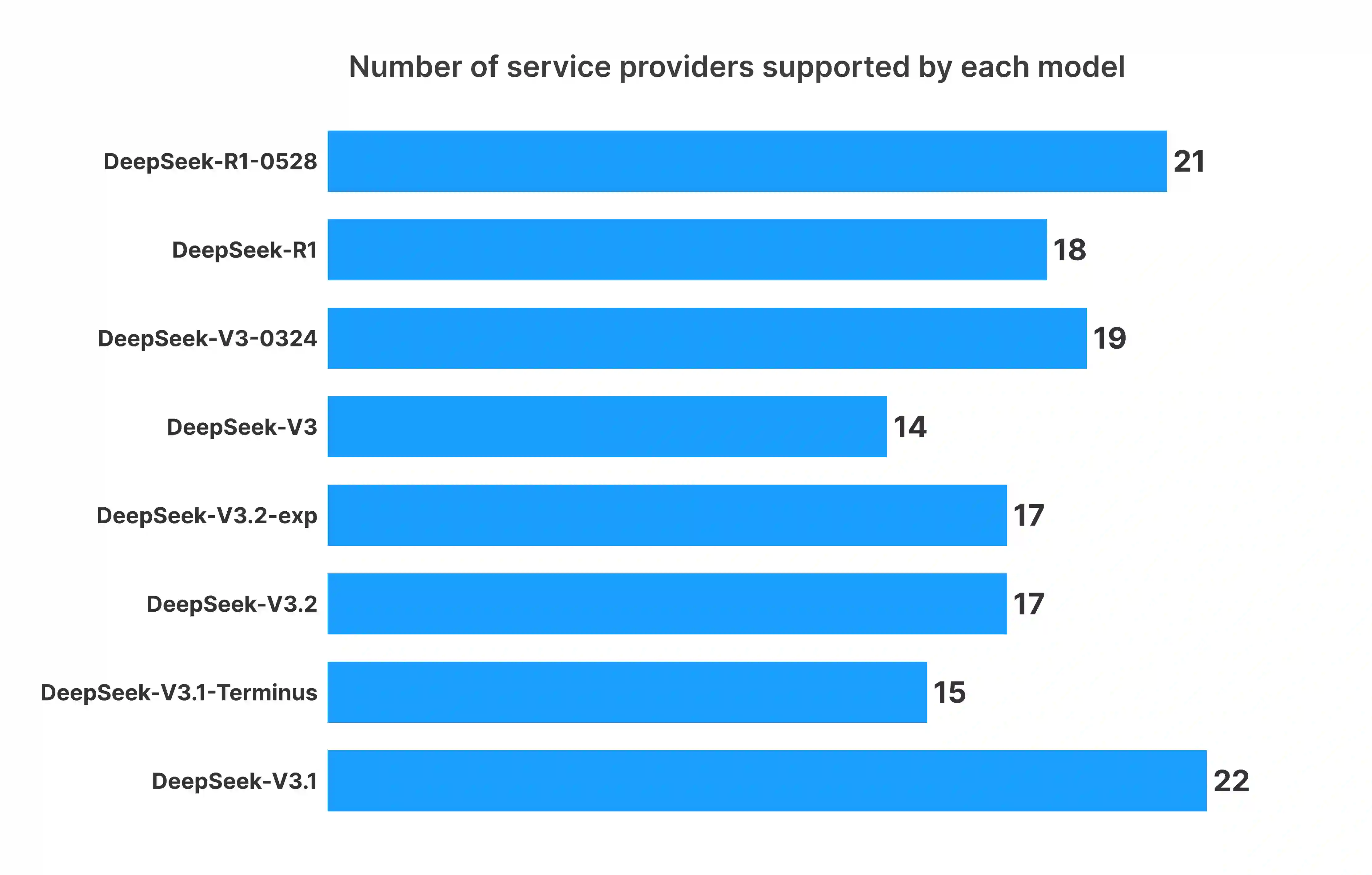
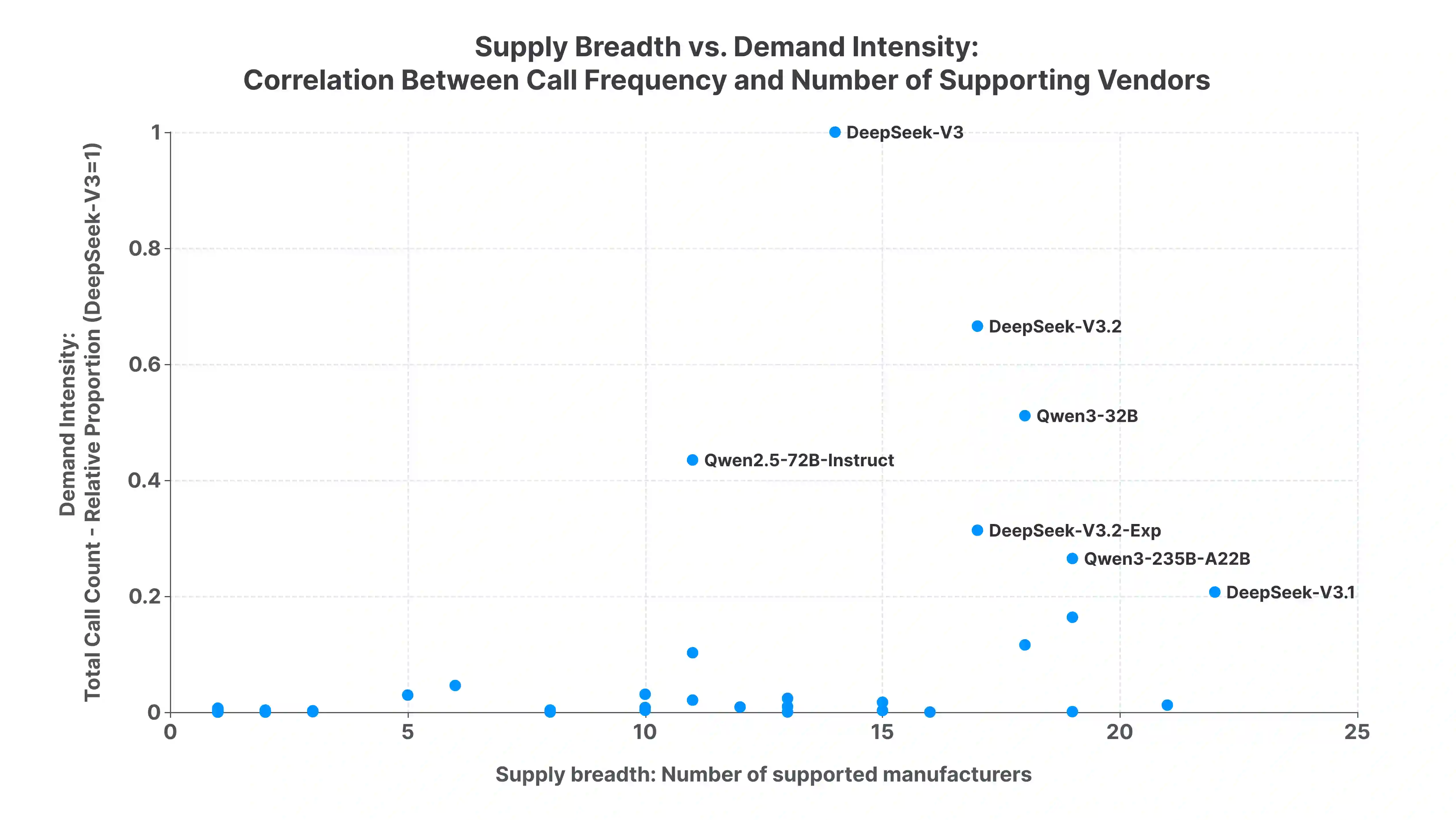
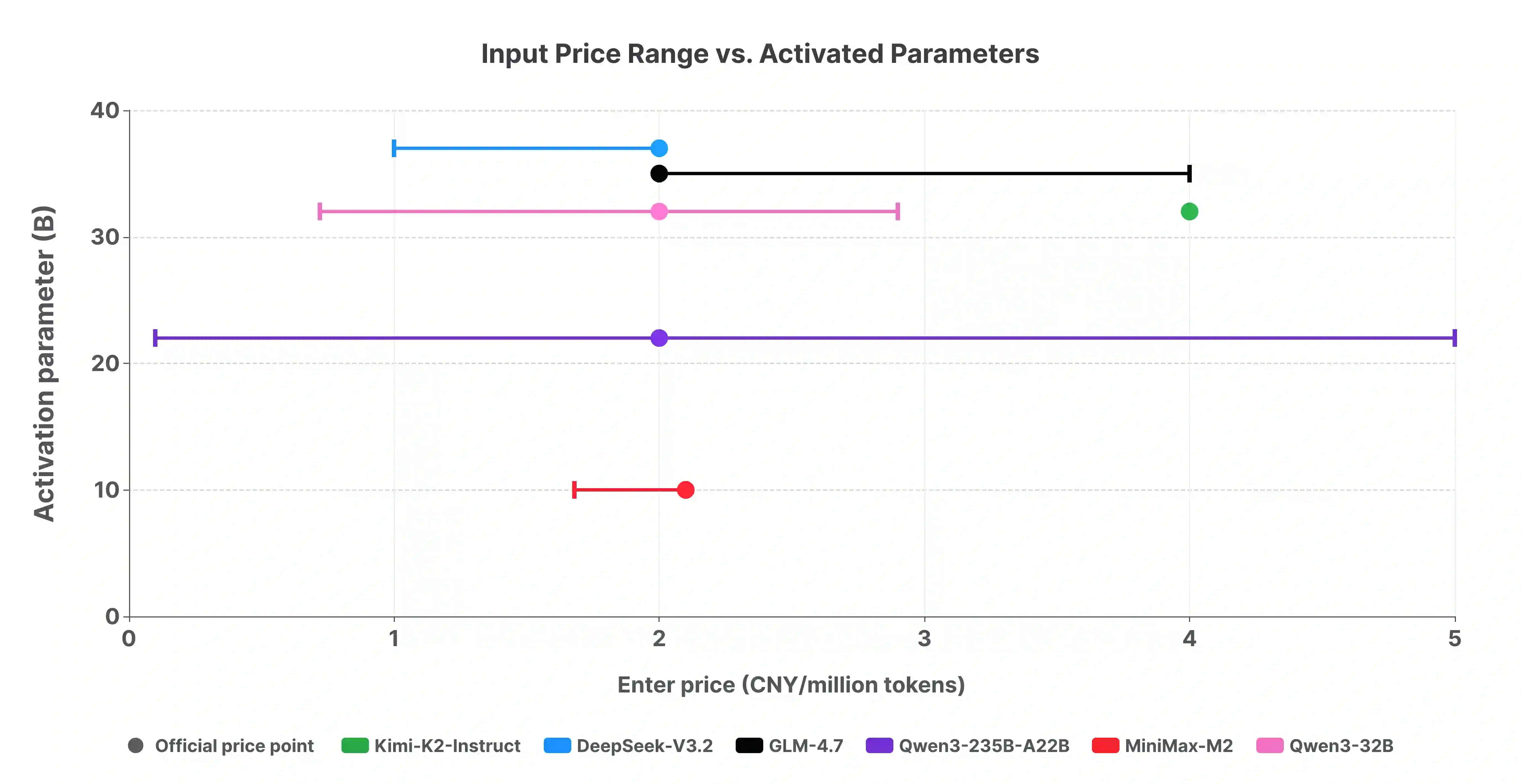
Open-weight large language models (LLMs) are often described as downloadable model artifacts, but in production they are increasingly consumed as hosted APIs. This paper studies the intermediary service layer that turns a model release into an operational endpoint. Using sampled request logs, provider metadata, compatibility probes, pricing snapshots, and continuous latency measurements collected by AI Ping during Q4 2025, we analyze demand concentration, provider heterogeneity, and task-conditioned routing for popular open-weight model families. The first empirical pattern is concentration with inertia: among the model families displayed in the public aggregate, the largest family carries 32.0% of relative demand and the top five carry 87.4%, with a Gini coefficient of 0.693, yet older versions remain active after newer releases. The second pattern is a separation between supply and use: broad provider listing of a model does not imply realized adoption, and listed prices are more anchored than latency, throughput, context length, protocol support, and error semantics. The third pattern is conditionality: applications induce different token-length regimes, so the relevant service object is not a model name but a provider-model-task-time tuple under protocol and context constraints. In two representative counterfactuals, routing lowers Qwen3-32B cost by 37.8% and raises DeepSeek-V3.2 average throughput by about 90% relative to direct official access. These results suggest that open-weight LLM deployment should be studied as a constrained statistical decision problem over a heterogeneous service layer, rather than as a static catalog of model capabilities.
翻译:暂无翻译