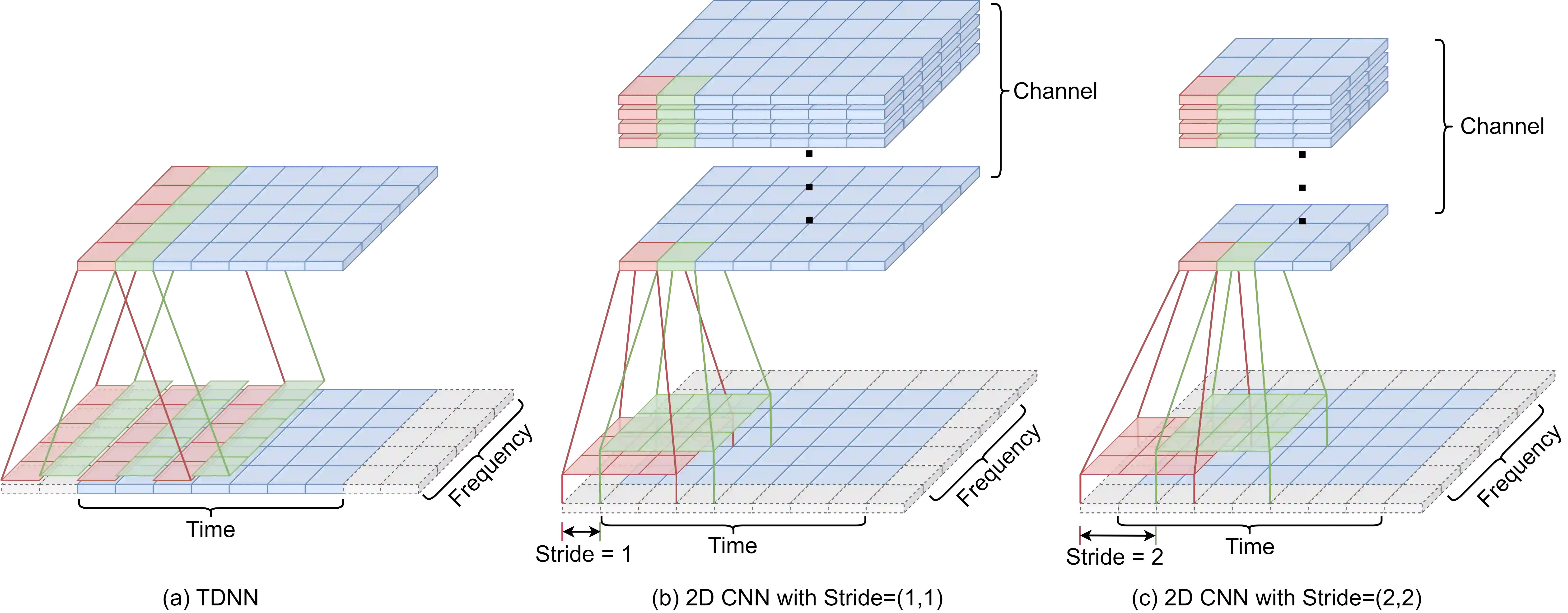
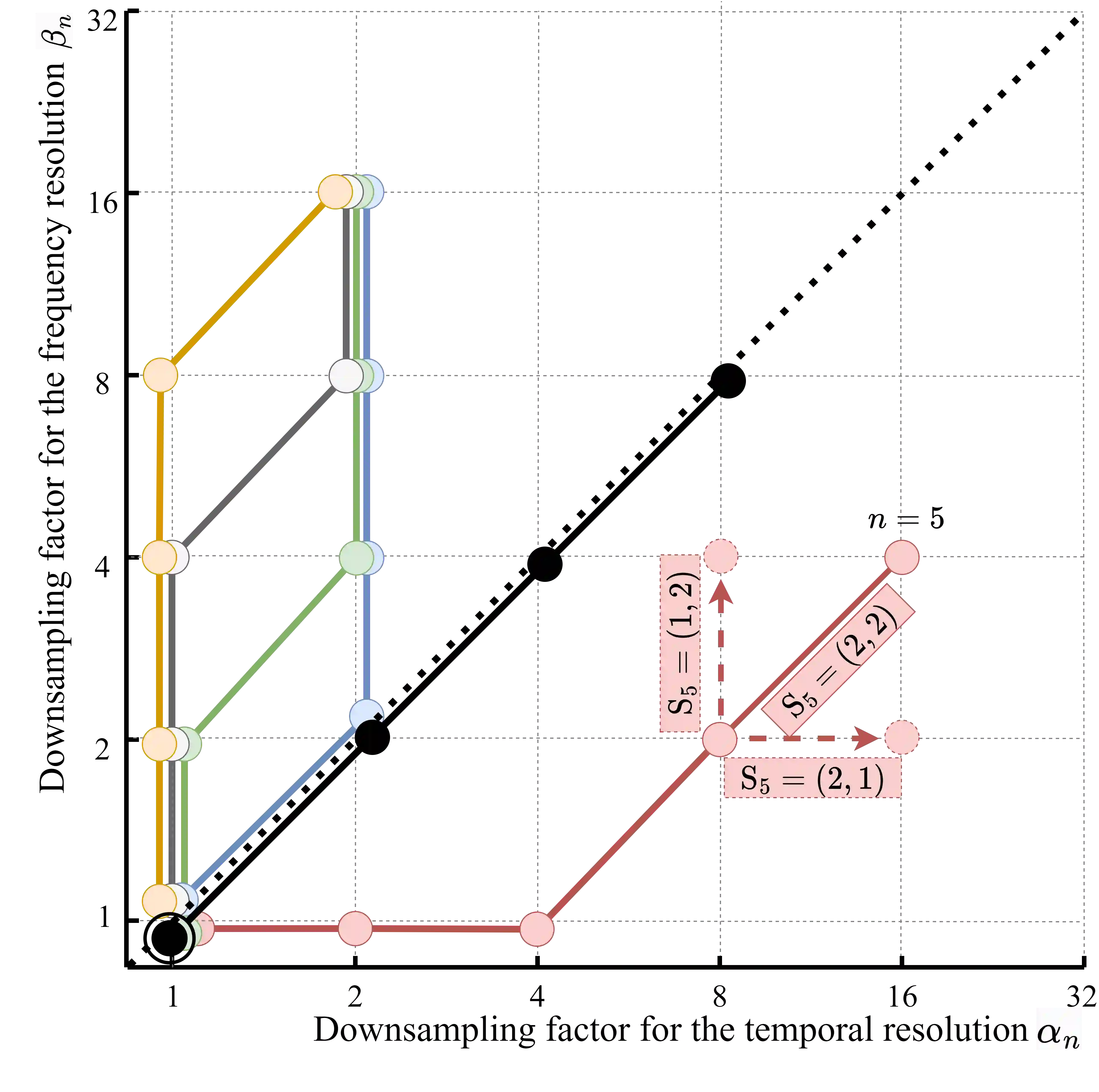
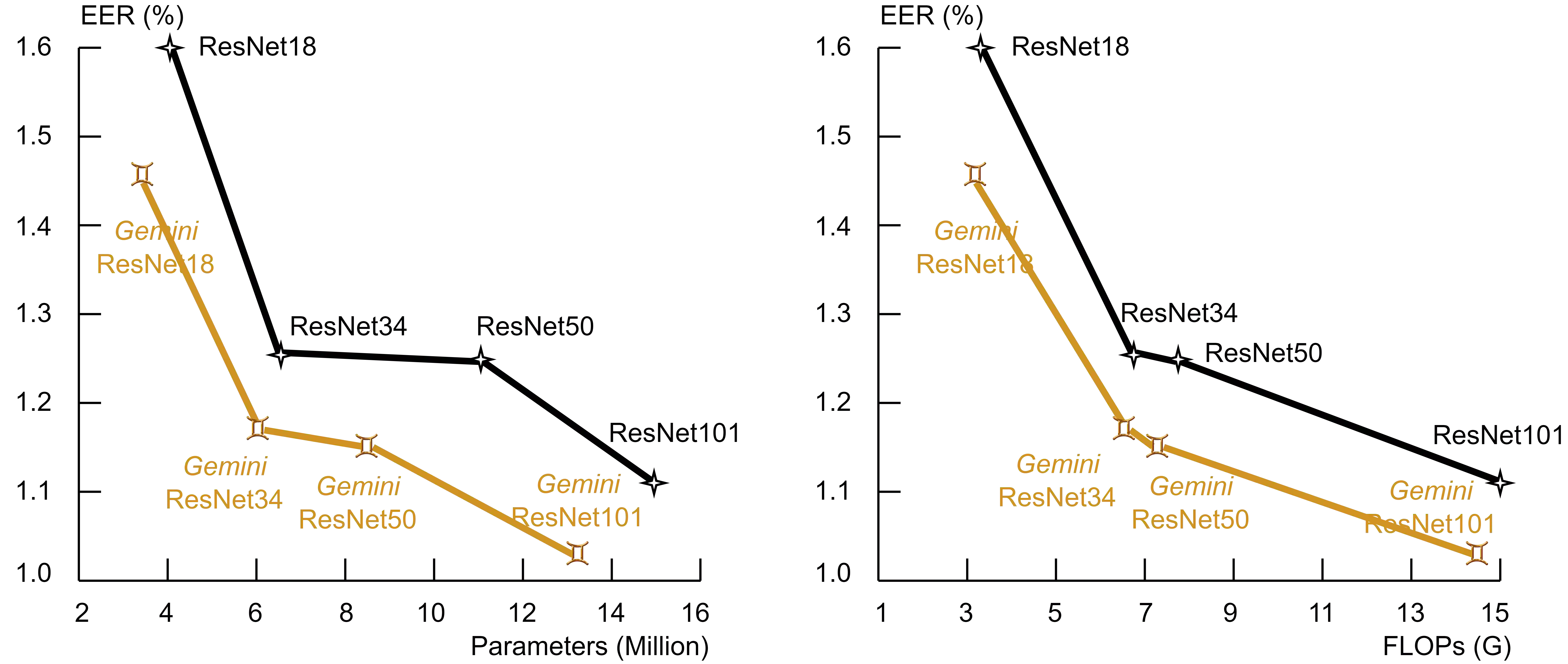
Previous studies demonstrate the impressive performance of residual neural networks (ResNet) in speaker verification. The ResNet models treat the time and frequency dimensions equally. They follow the default stride configuration designed for image recognition, where the horizontal and vertical axes exhibit similarities. This approach ignores the fact that time and frequency are asymmetric in speech representation. In this paper, we address this issue and look for optimal stride configurations specifically tailored for speaker verification. We represent the stride space on a trellis diagram, and conduct a systematic study on the impact of temporal and frequency resolutions on the performance and further identify two optimal points, namely Golden Gemini, which serves as a guiding principle for designing 2D ResNet-based speaker verification models. By following the principle, a state-of-the-art ResNet baseline model gains a significant performance improvement on VoxCeleb, SITW, and CNCeleb datasets with 7.70%/11.76% average EER/minDCF reductions, respectively, across different network depths (ResNet18, 34, 50, and 101), while reducing the number of parameters by 16.5% and FLOPs by 4.1%. We refer to it as Gemini ResNet. Further investigation reveals the efficacy of the proposed Golden Gemini operating points across various training conditions and architectures. Furthermore, we present a new benchmark, namely the Gemini DF-ResNet, using a cutting-edge model.
翻译:先前研究表明,残差神经网络在说话人验证任务中表现出色。ResNet模型在时间维度和频率维度上采用相同处理方式,遵循为图像识别设计的默认步长配置,其中水平轴与垂直轴具有相似性。这种方法忽略了语音表示中时间与频率的非对称特性。本文针对该问题,探索专为说话人验证优化的最优步长配置。我们基于格子图构建步长空间,系统研究时频分辨率对性能的影响,并识别出两个最优工作点——“金色双子”,这为基于二维ResNet的说话人验证模型设计提供了指导原则。遵循该原则,最先进的ResNet基线模型在VoxCeleb、SITW和CNCeleb数据集上,针对不同网络深度(ResNet18、34、50、101)分别实现了平均7.70%/11.76%的EER/minDCF性能提升,同时参数量减少16.5%、FLOPs降低4.1%。我们将此模型称为Gemini ResNet。进一步研究表明,所提出的金色双子工作点在不同训练条件和架构下均具有有效性。此外,我们基于最前沿模型提出了新的基准——Gemini DF-ResNet。