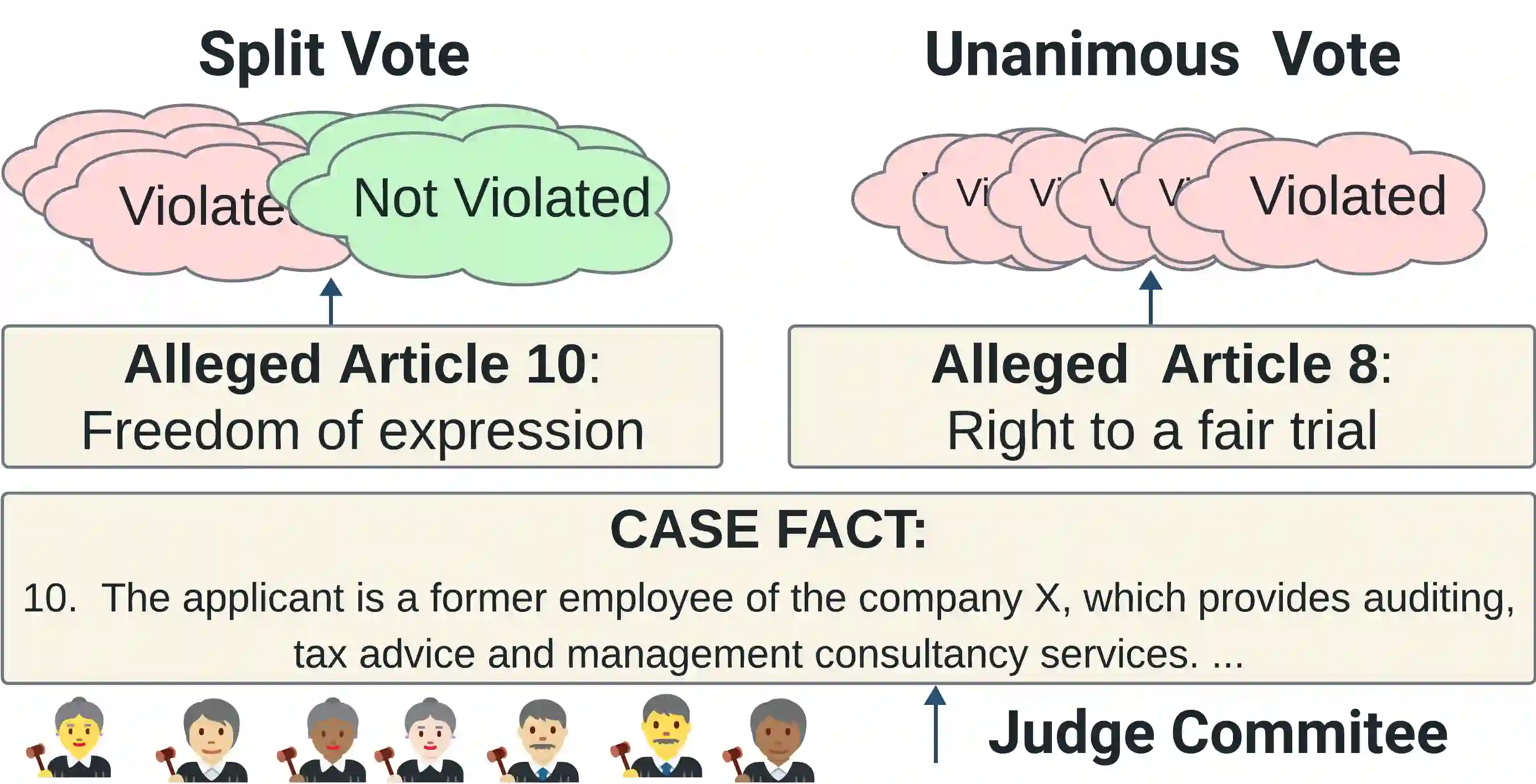
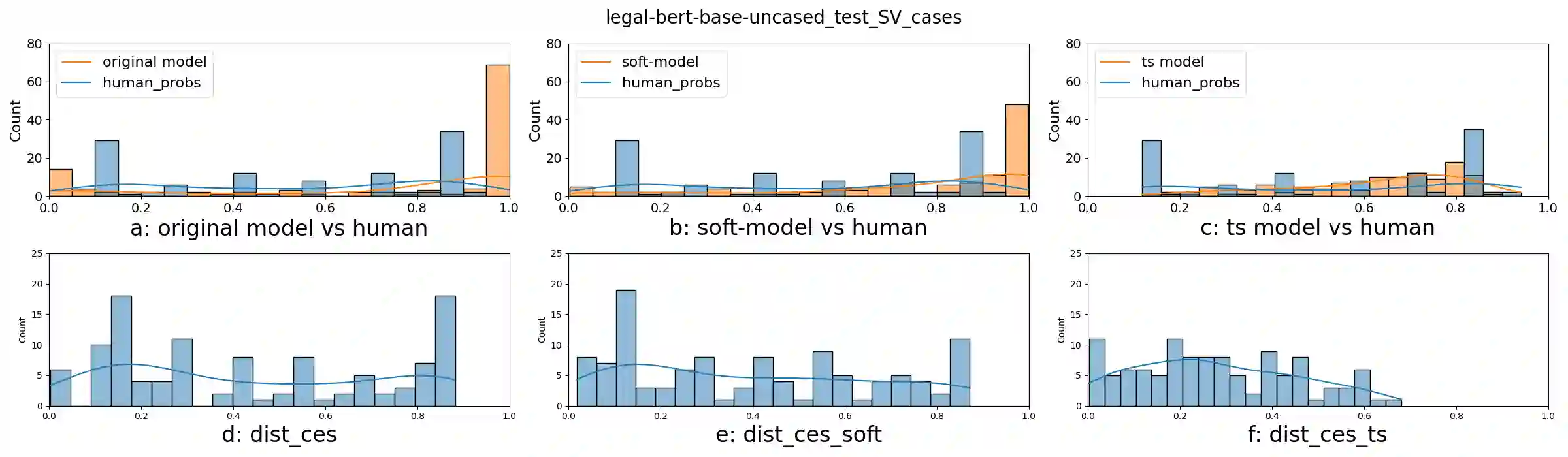
In legal decisions, split votes (SV) occur when judges cannot reach a unanimous decision, posing a difficulty for lawyers who must navigate diverse legal arguments and opinions. In high-stakes domains, understanding the alignment of perceived difficulty between humans and AI systems is crucial to build trust. However, existing NLP calibration methods focus on a classifier's awareness of predictive performance, measured against the human majority class, overlooking inherent human label variation (HLV). This paper explores split votes as naturally observable human disagreement and value pluralism. We collect judges' vote distributions from the European Court of Human Rights (ECHR), and present SV-ECHR, a case outcome classification (COC) dataset with SV information. We build a taxonomy of disagreement with SV-specific subcategories. We further assess the alignment of perceived difficulty between models and humans, as well as confidence- and human-calibration of COC models. We observe limited alignment with the judge vote distribution. To our knowledge, this is the first systematic exploration of calibration to human judgements in legal NLP. Our study underscores the necessity for further research on measuring and enhancing model calibration considering HLV in legal decision tasks.
翻译:在法律决策中,当法官无法达成一致裁决时会出现分歧投票,这给必须应对多元法律论证与意见的律师带来了困难。在高风险领域,理解人类与人工智能系统之间感知难度的对齐程度对建立信任至关重要。然而,现有的自然语言处理校准方法仅关注分类器对预测性能的感知能力——以人类多数类为基准进行衡量——这忽视了固有的人类标签变异。本文将分歧投票视为自然可观测的人类分歧与价值多元性的体现。我们从欧洲人权法院收集法官投票分布,并构建了包含分歧投票信息的数据集SV-ECHR,用于案件结果分类任务。我们建立了具有分歧投票特定子类别的不确定性分类体系,进一步评估了模型与人类之间感知难度的对齐程度,以及案件结果分类模型的置信度校准与人类校准。我们观察到模型与法官投票分布的对齐程度有限。据我们所知,这是法律自然语言处理领域首个系统探索对人类判断进行校准的研究。本研究强调了在涉及法律决策任务时,需进一步开展考虑人类标签变异的模型校准测量与改进研究。