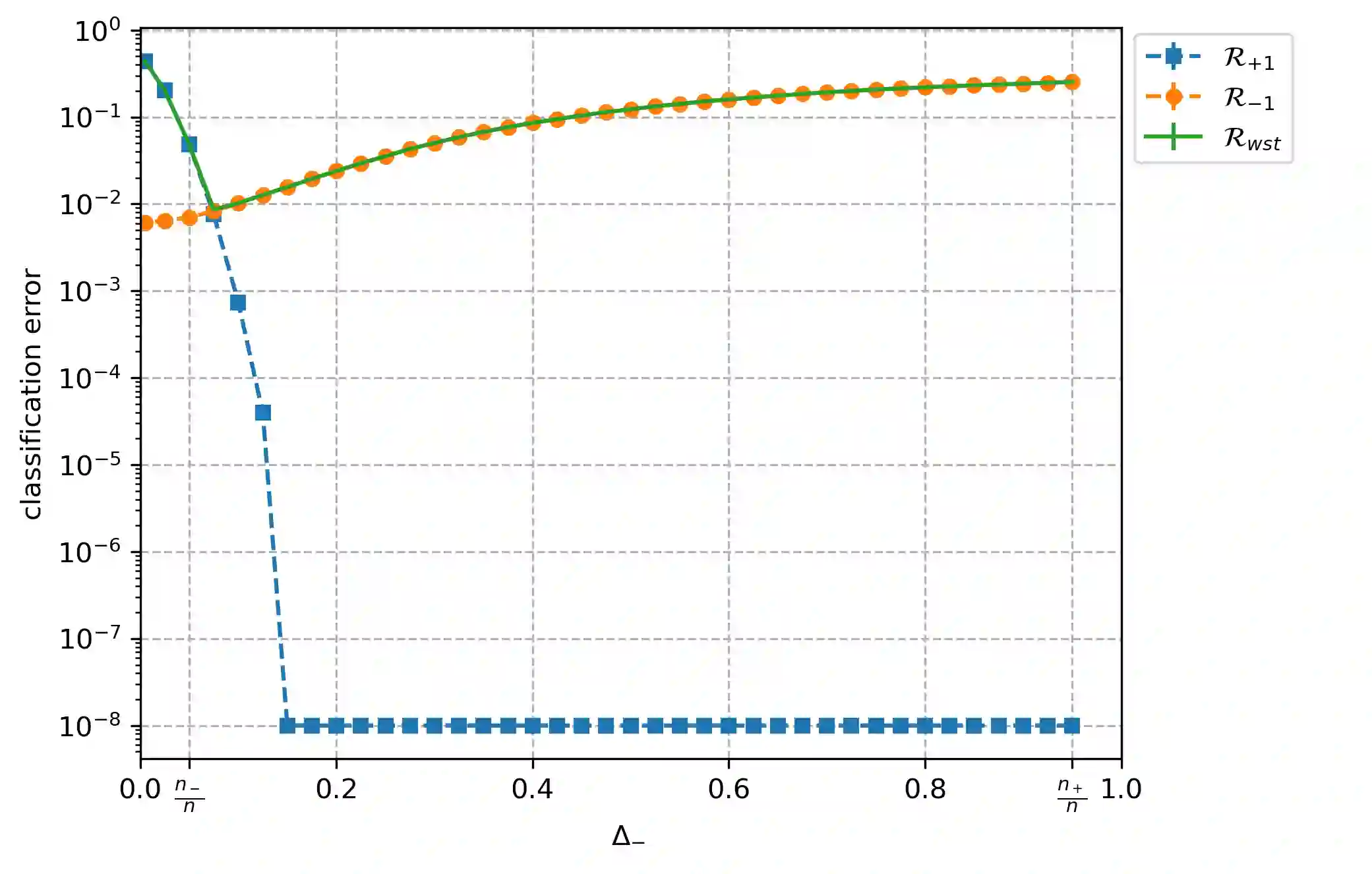
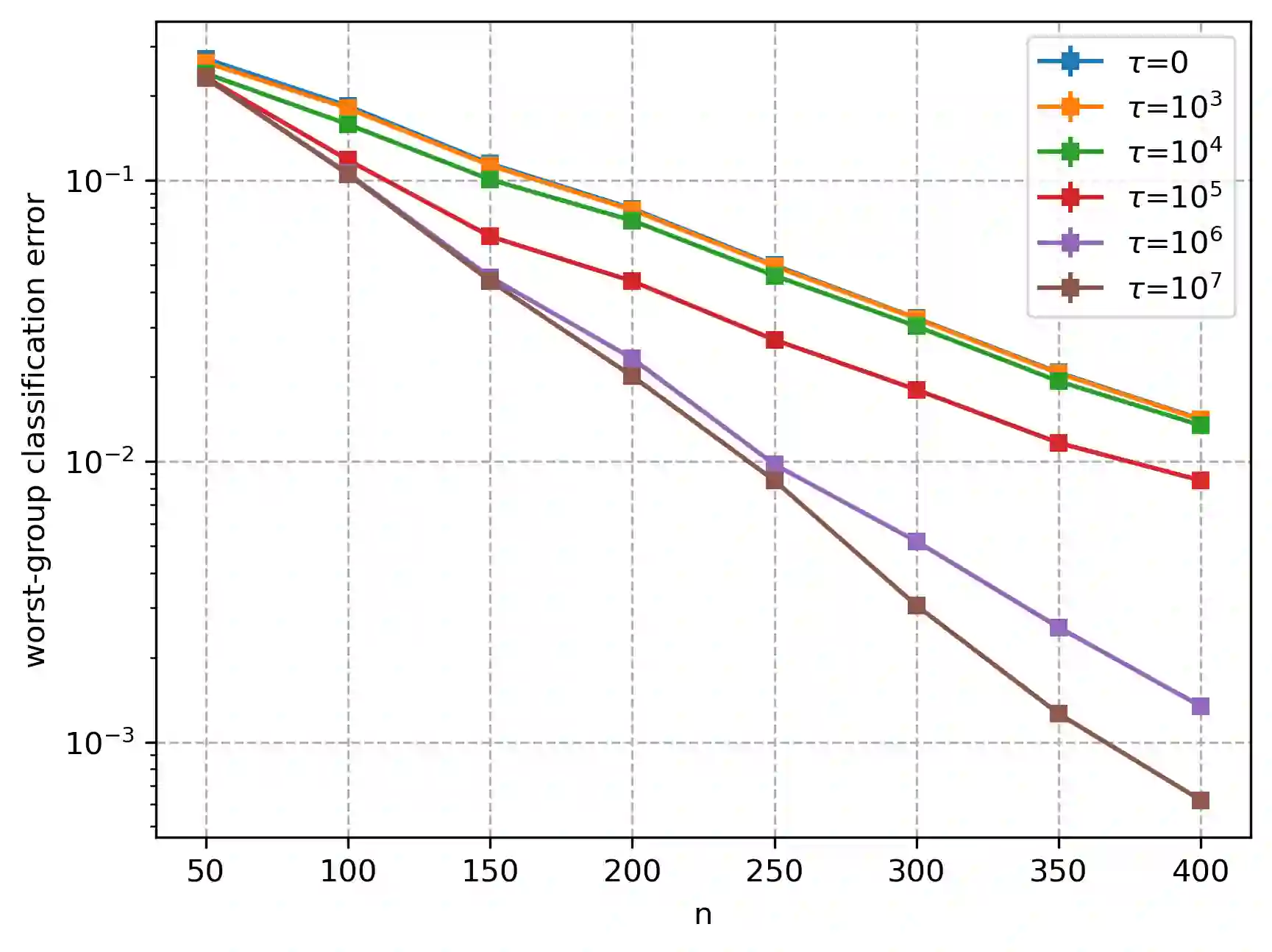
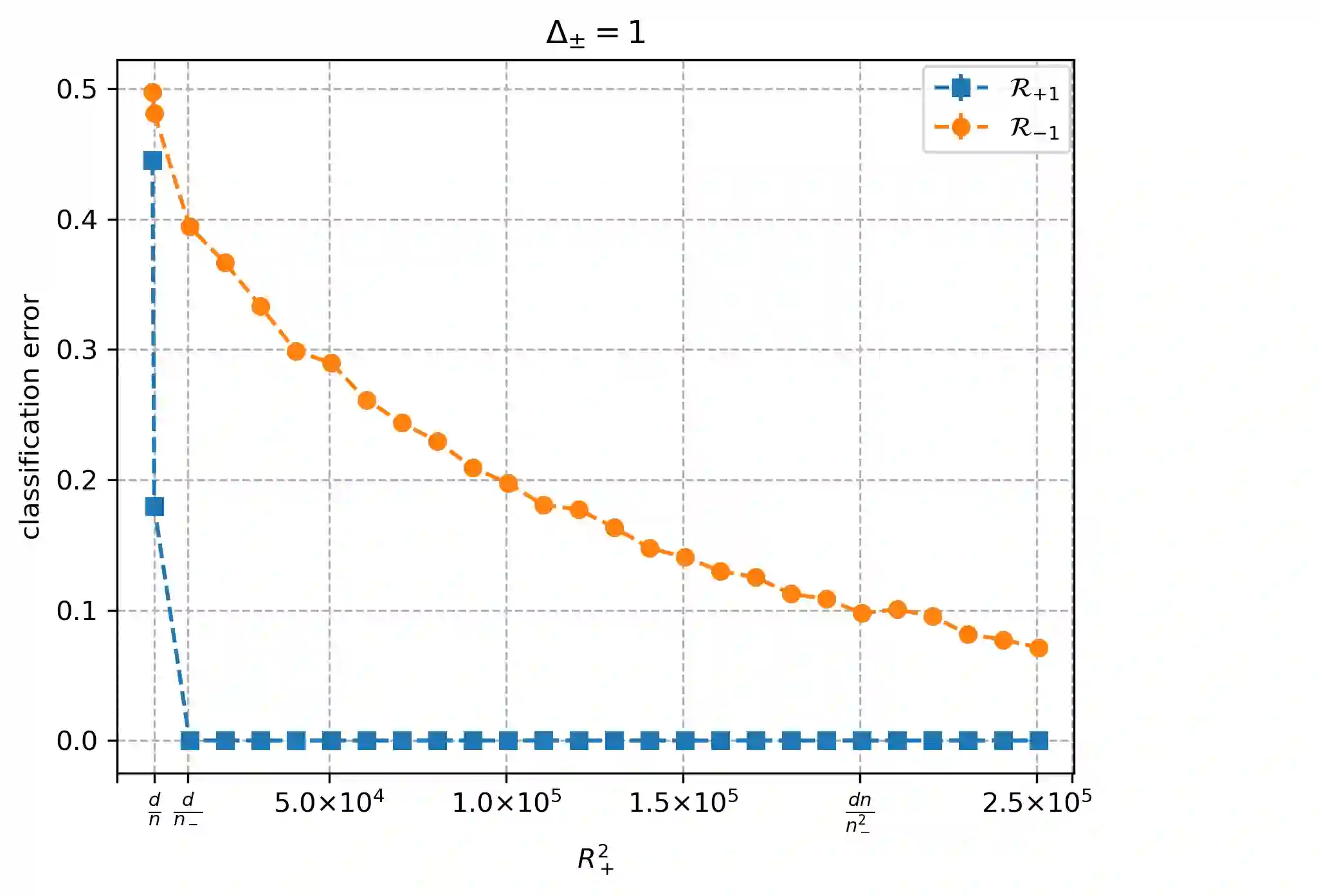
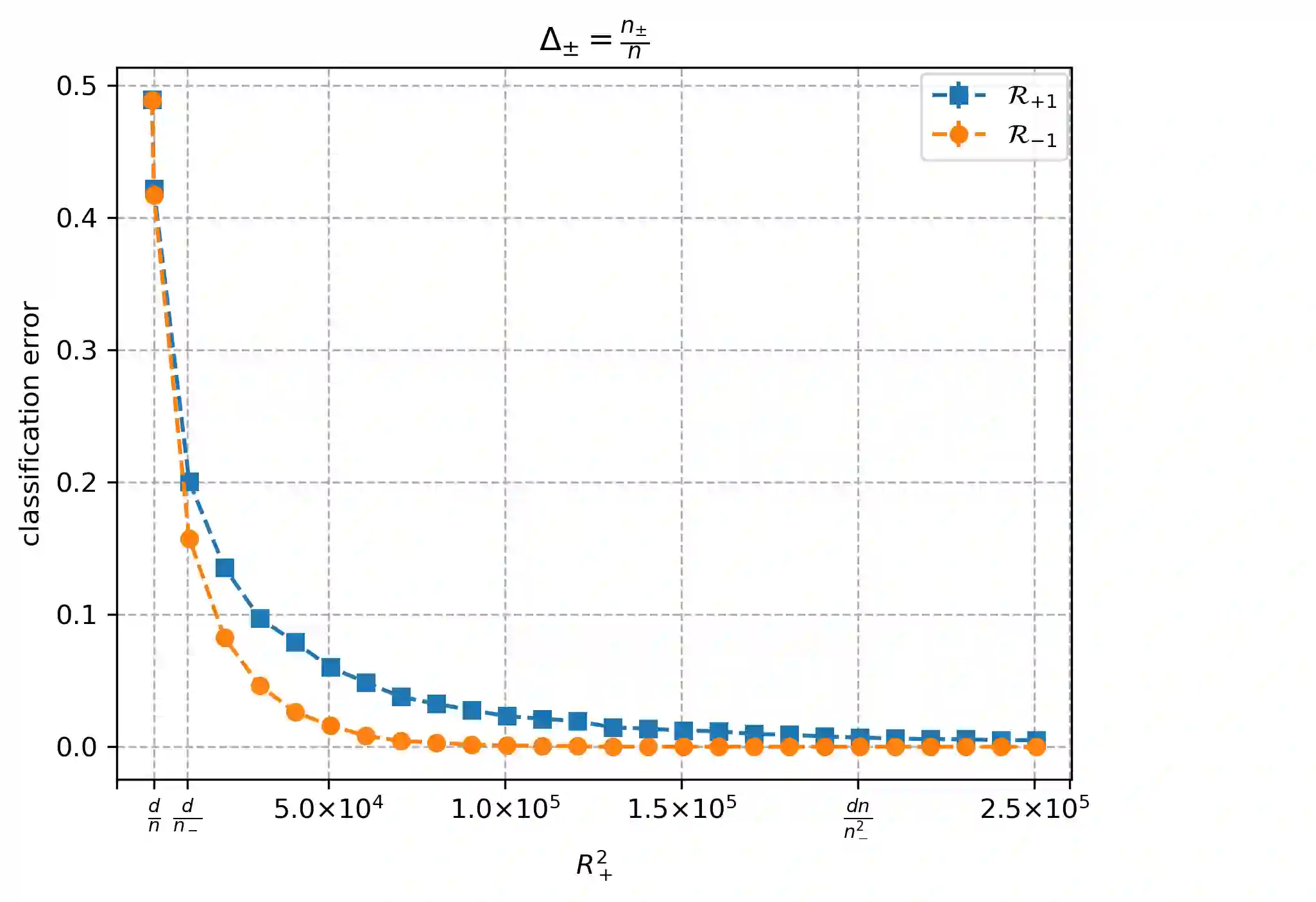
Overparameterized models that achieve zero training error are observed to generalize well on average, but degrade in performance when faced with data that is under-represented in the training sample. In this work, we study an overparameterized Gaussian mixture model imbued with a spurious feature, and sharply analyze the in-distribution and out-of-distribution test error of a cost-sensitive interpolating solution that incorporates "importance weights". Compared to recent work Wang et al. (2021), Behnia et al. (2022), our analysis is sharp with matching upper and lower bounds, and significantly weakens required assumptions on data dimensionality. Our error characterizations also apply to any choice of importance weights and unveil a novel tradeoff between worst-case robustness to distribution shift and average accuracy as a function of the importance weight magnitude.
翻译:过参数化模型在达到零训练误差时,通常表现出良好的平均泛化性能,但在面对训练样本中代表性不足的数据时,其性能会下降。本文研究了一个带有伪特征的过参数化高斯混合模型,并精炼分析了结合“重要性权重”的成本敏感插值解在分布内和分布外测试误差。与Wang等人(2021)、Behnia等人(2022)近期的工作相比,我们的分析具有匹配的上界和下界,并显著弱化了所需的数据维度假设。我们的误差刻画同样适用于任意重要性权重选择,并揭示了一个新的权衡关系:在分布偏移下的最坏情况鲁棒性与平均准确率之间,作为重要性权重幅度的函数。