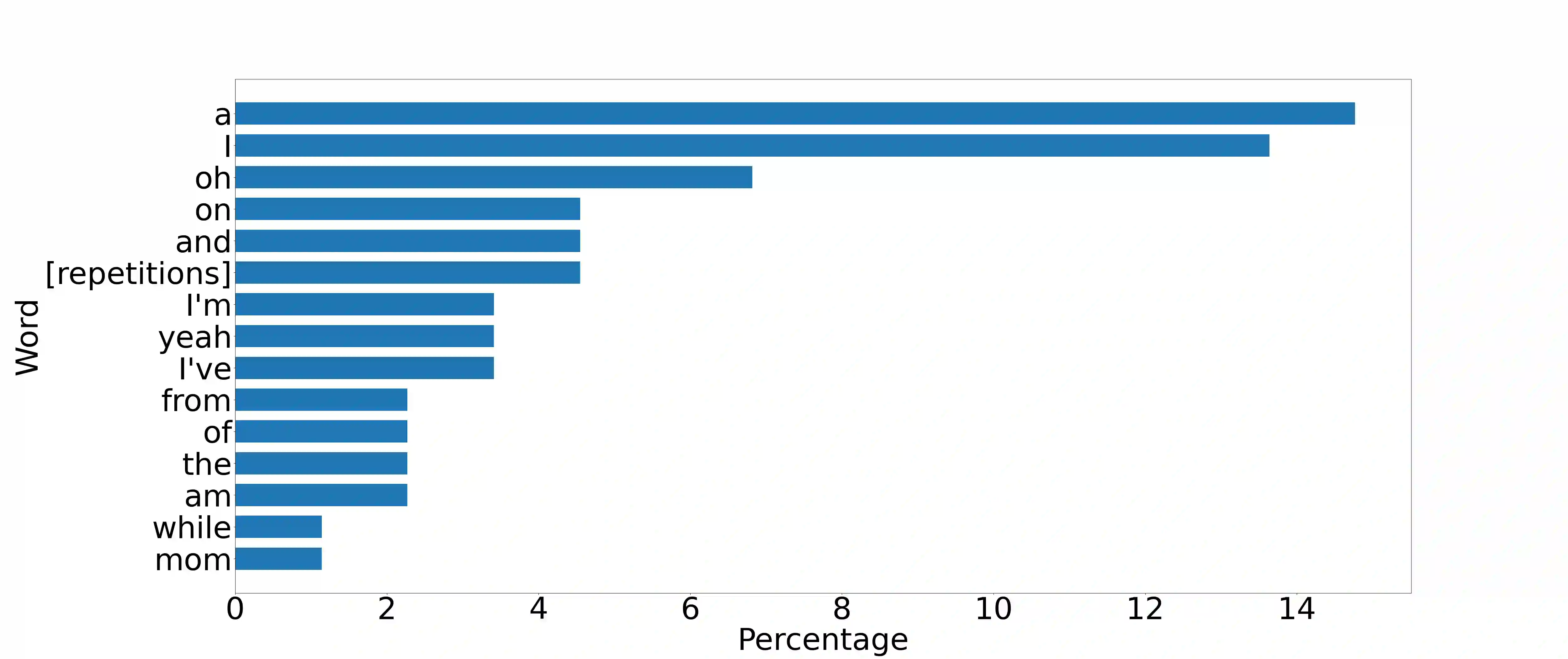
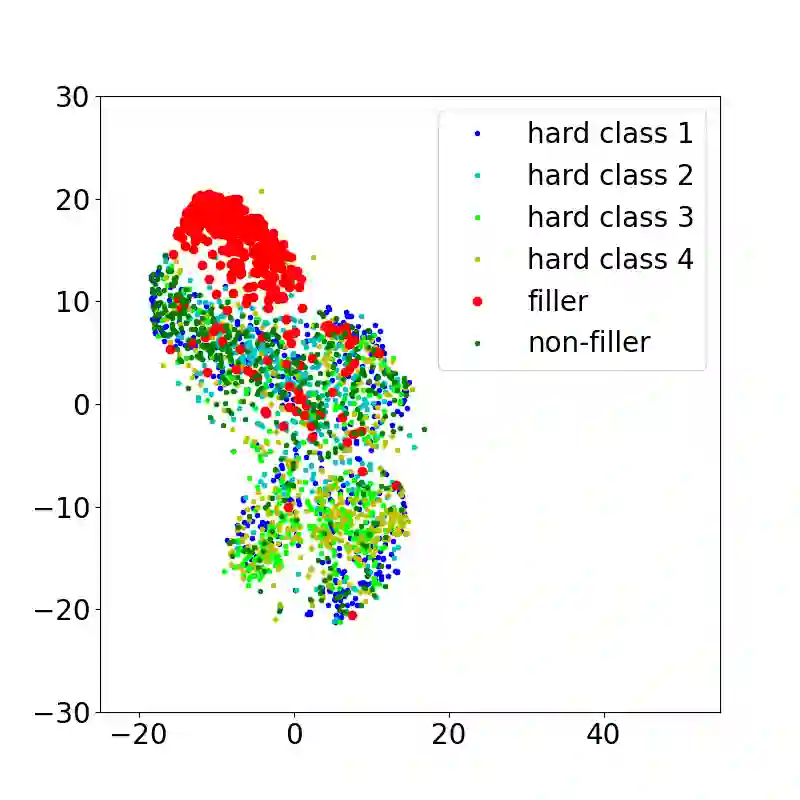
Filler words like ``um" or ``uh" are common in spontaneous speech. It is desirable to automatically detect and remove them in recordings, as they affect the fluency, confidence, and professionalism of speech. Previous studies and our preliminary experiments reveal that the biggest challenge in filler word detection is that fillers can be easily confused with other hard categories like ``a" or ``I". In this paper, we propose a novel filler word detection method that effectively addresses this challenge by adding auxiliary categories dynamically and applying an additional inter-category focal loss. The auxiliary categories force the model to explicitly model the confusing words by mining hard categories. In addition, inter-category focal loss adaptively adjusts the penalty weight between ``filler" and ``non-filler" categories to deal with other confusing words left in the ``non-filler" category. Our system achieves the best results, with a huge improvement compared to other methods on the PodcastFillers dataset.
翻译:诸如“嗯”或“呃”之类的填充词在自发性语音中很常见。自动检测并移除录音中的这些词非常必要,因为它们会影响语音的流畅性、自信度和专业性。先前的研究及我们的初步实验表明,填充词检测最大的挑战在于填充词容易与其他困难类别(如“a”或“I”)混淆。本文提出了一种新颖的填充词检测方法,通过动态添加辅助类别并应用额外的类别间焦点损失,有效解决了这一挑战。辅助类别通过挖掘困难类别强制模型显式建模混淆词。此外,类别间焦点损失自适应调整“填充词”与“非填充词”类别之间的惩罚权重,以处理残留在“非填充词”类别中的其他混淆词。我们的系统在PodcastFillers数据集上取得了最佳结果,相较于其他方法实现了巨大提升。