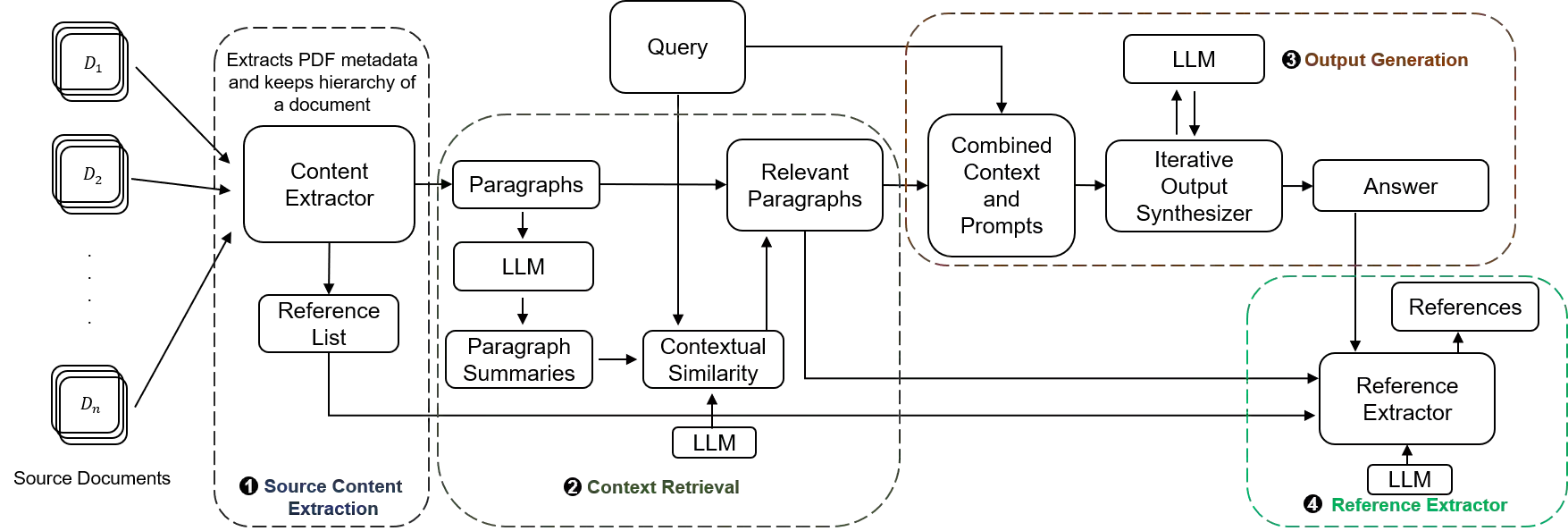
Large Language Models (LLMs) excel in data synthesis but can be inaccurate in domain-specific tasks, which retrieval-augmented generation (RAG) systems address by leveraging user-provided data. However, RAGs require optimization in both retrieval and generation stages, which can affect output quality. In this paper, we present LLM-Ref, a writing assistant tool that aids researchers in writing articles from multiple source documents with enhanced reference synthesis and handling capabilities. Unlike traditional RAG systems that use chunking and indexing, our tool retrieves and generates content directly from text paragraphs. This method facilitates direct reference extraction from the generated outputs, a feature unique to our tool. Additionally, our tool employs iterative response generation, effectively managing lengthy contexts within the language model's constraints. Compared to baseline RAG-based systems, our approach achieves a $3.25\times$ to $6.26\times$ increase in Ragas score, a comprehensive metric that provides a holistic view of a RAG system's ability to produce accurate, relevant, and contextually appropriate responses. This improvement shows our method enhances the accuracy and contextual relevance of writing assistance tools.
翻译:大语言模型(LLMs)在数据综合方面表现出色,但在特定领域任务中可能存在不准确性,检索增强生成(RAG)系统通过利用用户提供的数据来解决这一问题。然而,RAG系统需要在检索和生成两个阶段进行优化,这可能影响输出质量。本文提出LLM-Ref,一种写作辅助工具,可帮助研究人员基于多份源文档撰写文章,并具备增强的参考文献综合与处理能力。与传统RAG系统采用分块和索引的方法不同,我们的工具直接从文本段落中检索并生成内容。这种方法便于从生成输出中直接提取参考文献,这是本工具独有的特性。此外,我们的工具采用迭代式响应生成,能在语言模型的约束范围内有效管理长上下文。与基于RAG的基线系统相比,我们的方法在Ragas分数上实现了$3.25\times$至$6.26\times$的提升——Ragas分数是一种综合性指标,能全面评估RAG系统生成准确、相关且上下文恰当响应的能力。这一改进表明我们的方法显著提升了写作辅助工具的准确性和上下文相关性。