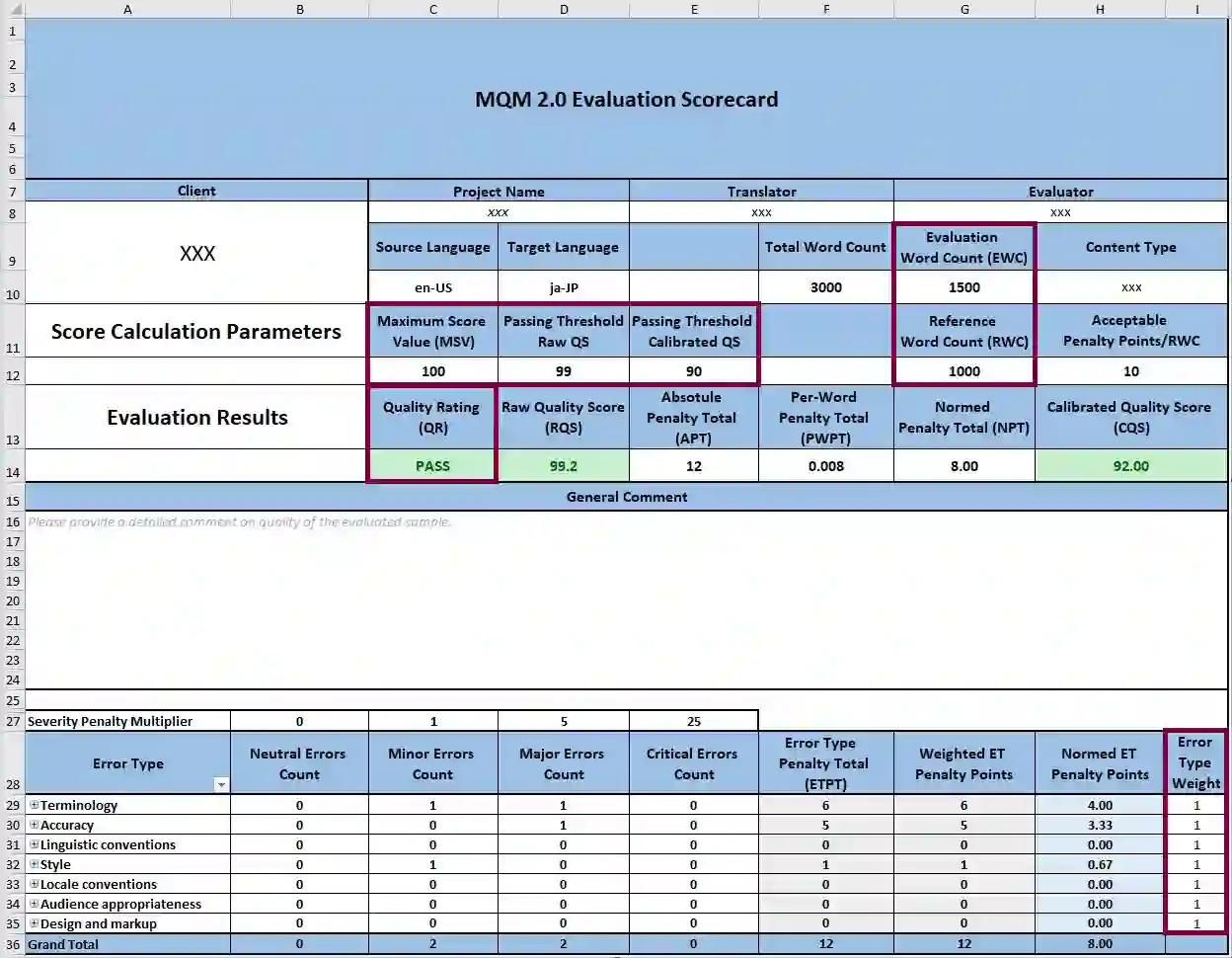
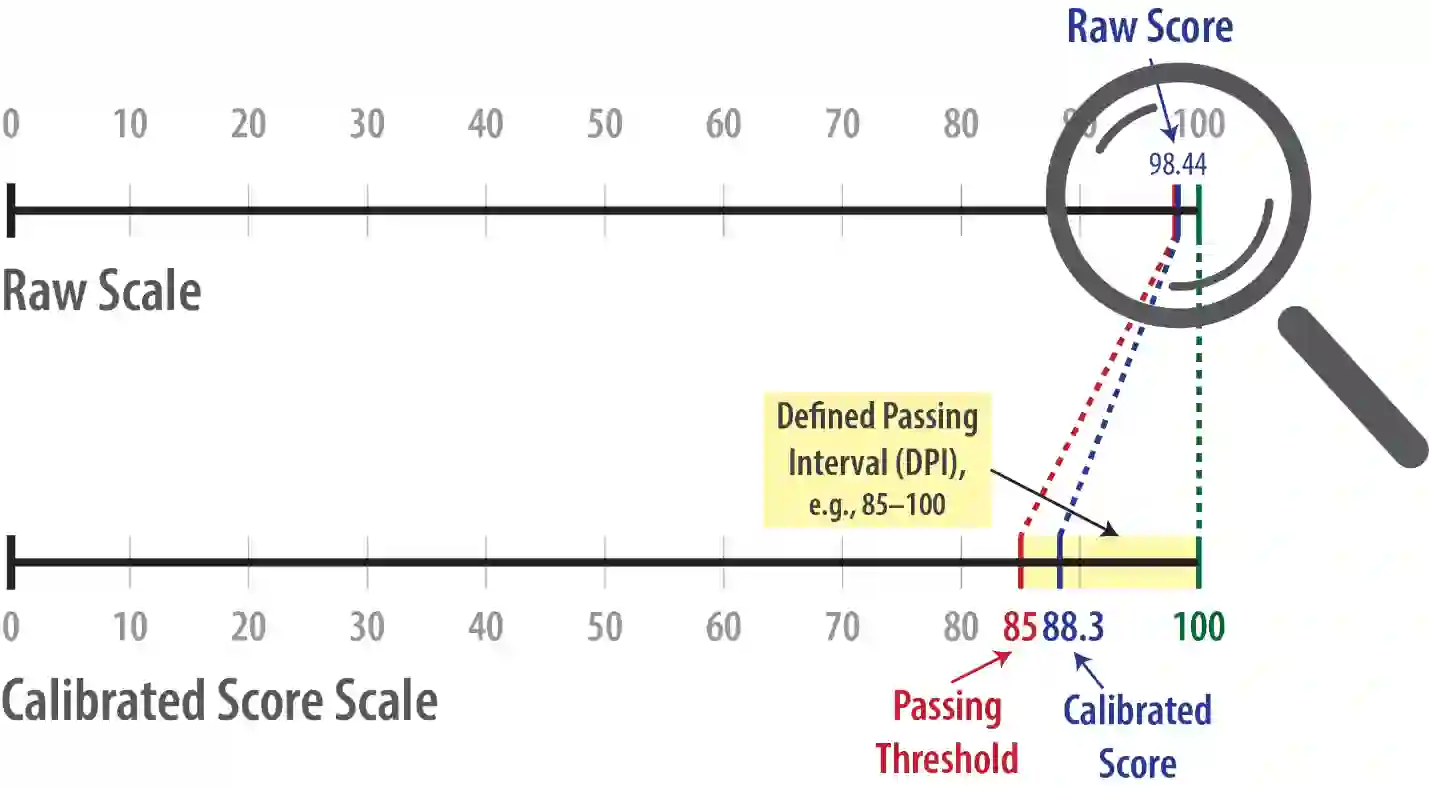
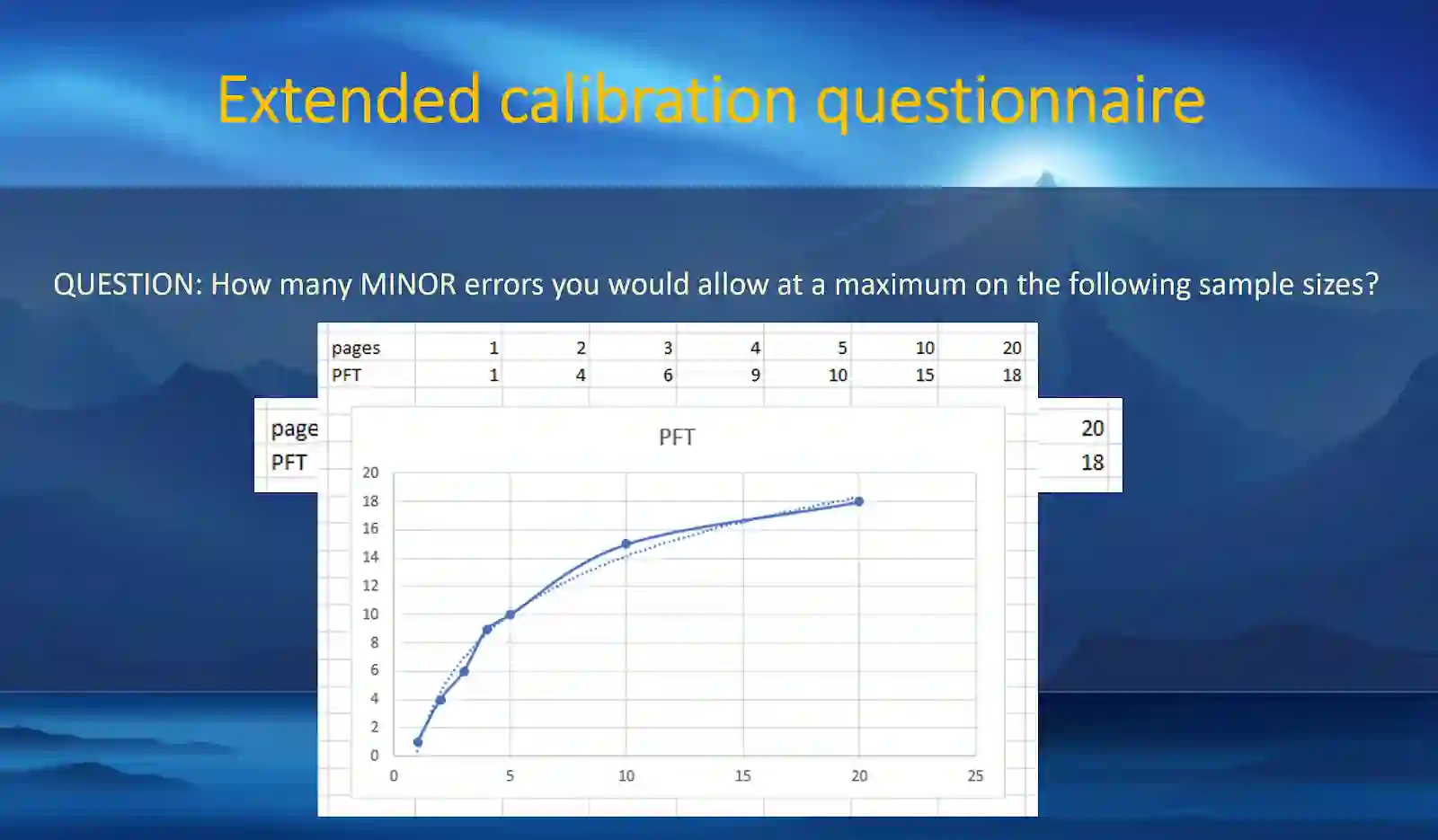
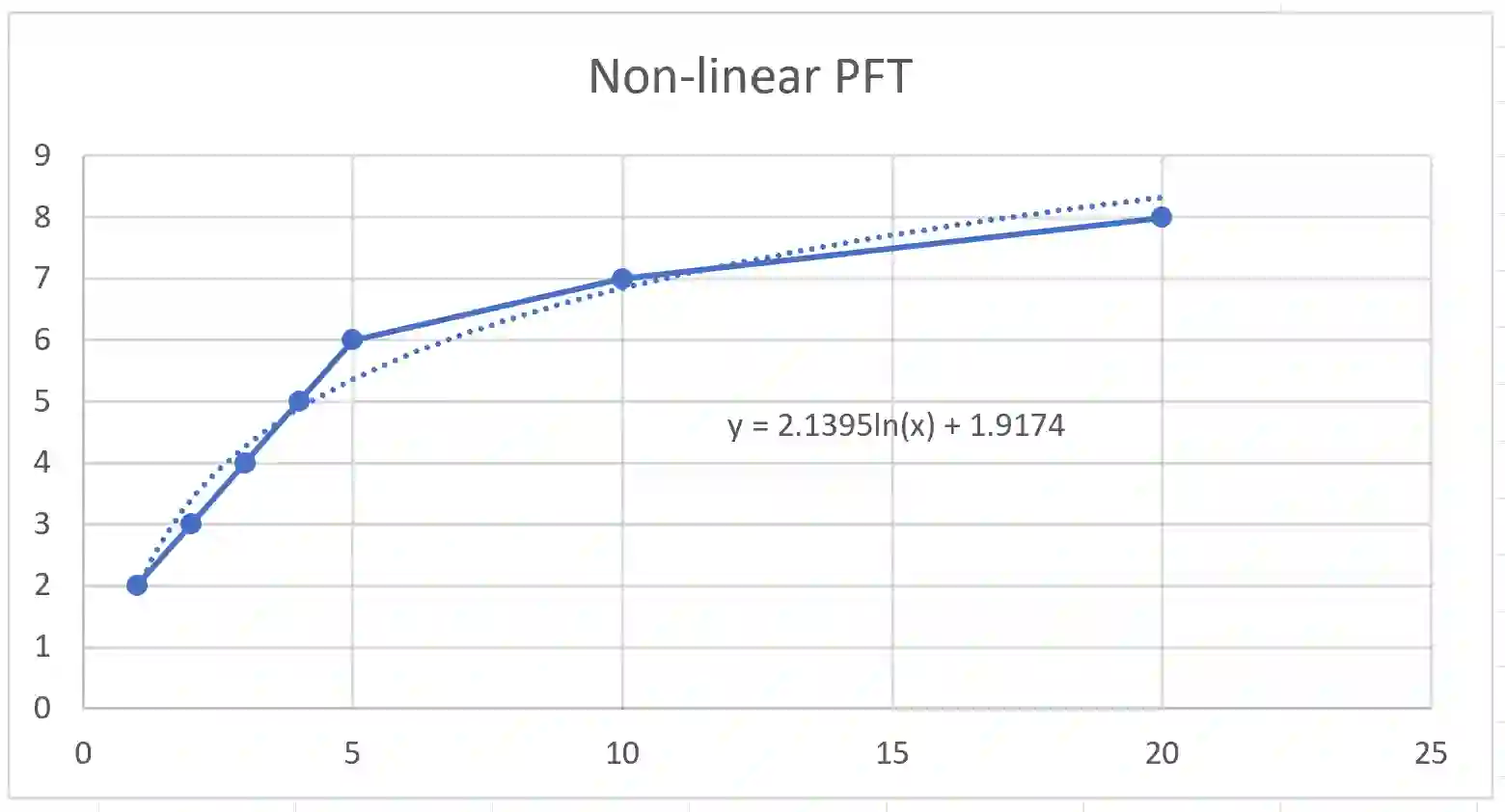
The year 2024 marks the 10th anniversary of the Multidimensional Quality Metrics (MQM) framework for analytic translation quality evaluation. The MQM error typology has been widely used by practitioners in the translation and localization industry and has served as the basis for many derivative projects. The annual Conference on Machine Translation (WMT) shared tasks on both human and automatic translation quality evaluations used the MQM error typology. The metric stands on two pillars: error typology and the scoring model. The scoring model calculates the quality score from annotation data, detailing how to convert error type and severity counts into numeric scores to determine if the content meets specifications. Previously, only the raw scoring model had been published. This April, the MQM Council published the Linear Calibrated Scoring Model, officially presented herein, along with the Non-Linear Scoring Model, which had not been published before. This paper details the latest MQM developments and presents a universal approach to translation quality measurement across three sample size ranges. It also explains why Statistical Quality Control should be used for very small sample sizes, starting from a single sentence.
翻译:2024年是多维质量指标(MQM)分析性翻译质量评估框架诞生十周年。MQM错误分类体系已被翻译与本地化行业的从业者广泛采用,并成为许多衍生项目的基础。机器翻译年度会议(WMT)关于人工与自动翻译质量评估的共享任务均采用了MQM错误分类体系。该指标体系建立在两大支柱之上:错误分类体系与评分模型。评分模型通过标注数据计算质量分数,详细说明了如何将错误类型与严重程度计数转换为数值分数,以判定内容是否符合规范。此前仅原始评分模型已公开发布。今年四月,MQM委员会正式发布了线性校准评分模型(本文首次正式呈现),以及此前未公开的非线性评分模型。本文详述了MQM的最新进展,并提出了一种适用于三种样本量范围的通用翻译质量测量方法。同时阐述了为何应从单句起始,对极小样本量采用统计质量控制方法。