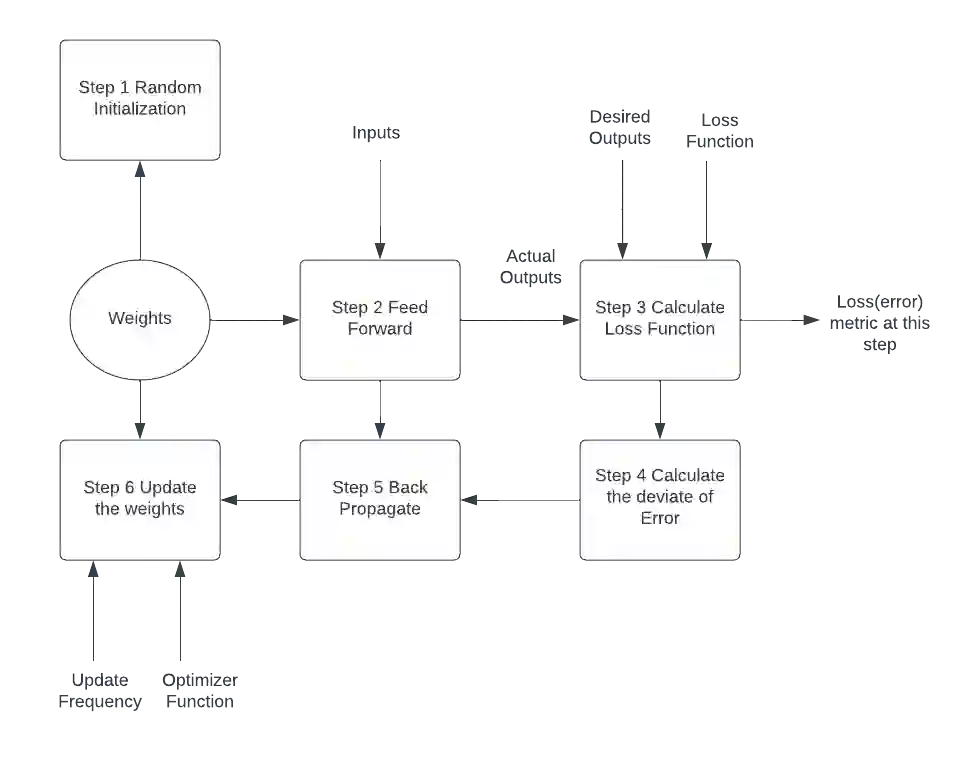
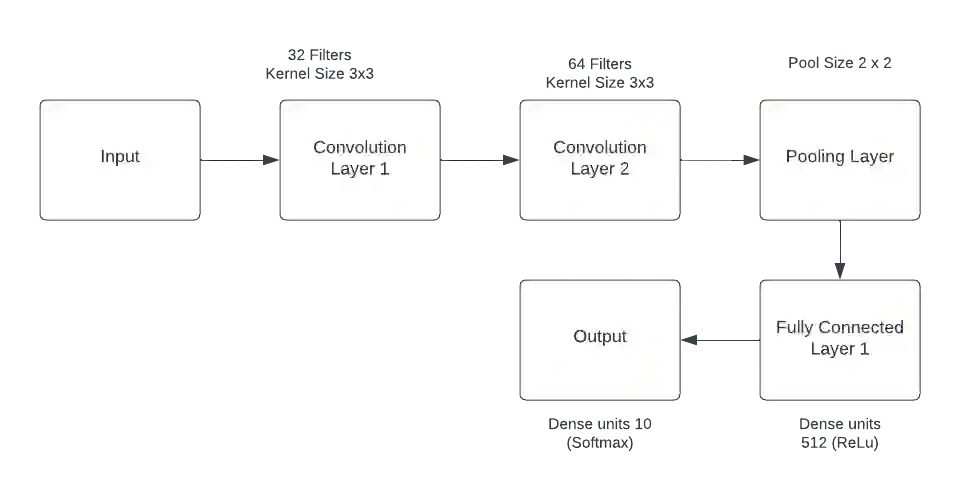
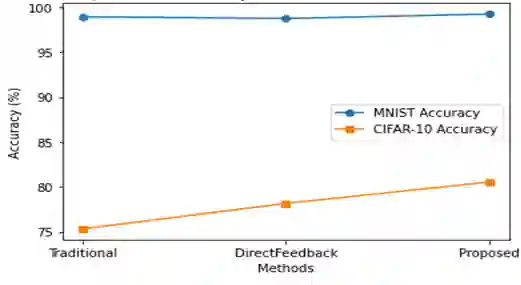
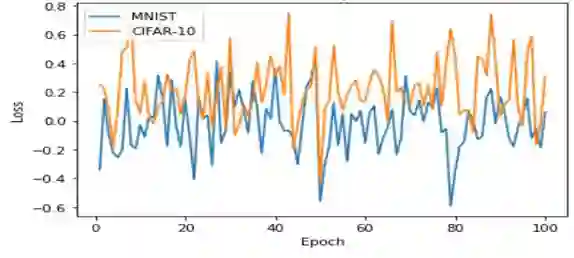
Deep learning has revolutionized industries like computer vision, natural language processing, and speech recognition. However, back propagation, the main method for training deep neural networks, faces challenges like computational overhead and vanishing gradients. In this paper, we propose a novel instant parameter update methodology that eliminates the need for computing gradients at each layer. Our approach accelerates learning, avoids the vanishing gradient problem, and outperforms state-of-the-art methods on benchmark data sets. This research presents a promising direction for efficient and effective deep neural network training.
翻译:深度学习彻底变革了计算机视觉、自然语言处理和语音识别等领域。然而,作为训练深度神经网络的主要方法,反向传播面临着计算开销和梯度消失等挑战。本文提出了一种新颖的即时参数更新方法,无需计算每层的梯度。我们的方法加速了学习过程,避免了梯度消失问题,并在基准数据集上超越了现有最优方法。本研究为高效且有效的深度神经网络训练开辟了有前景的新方向。