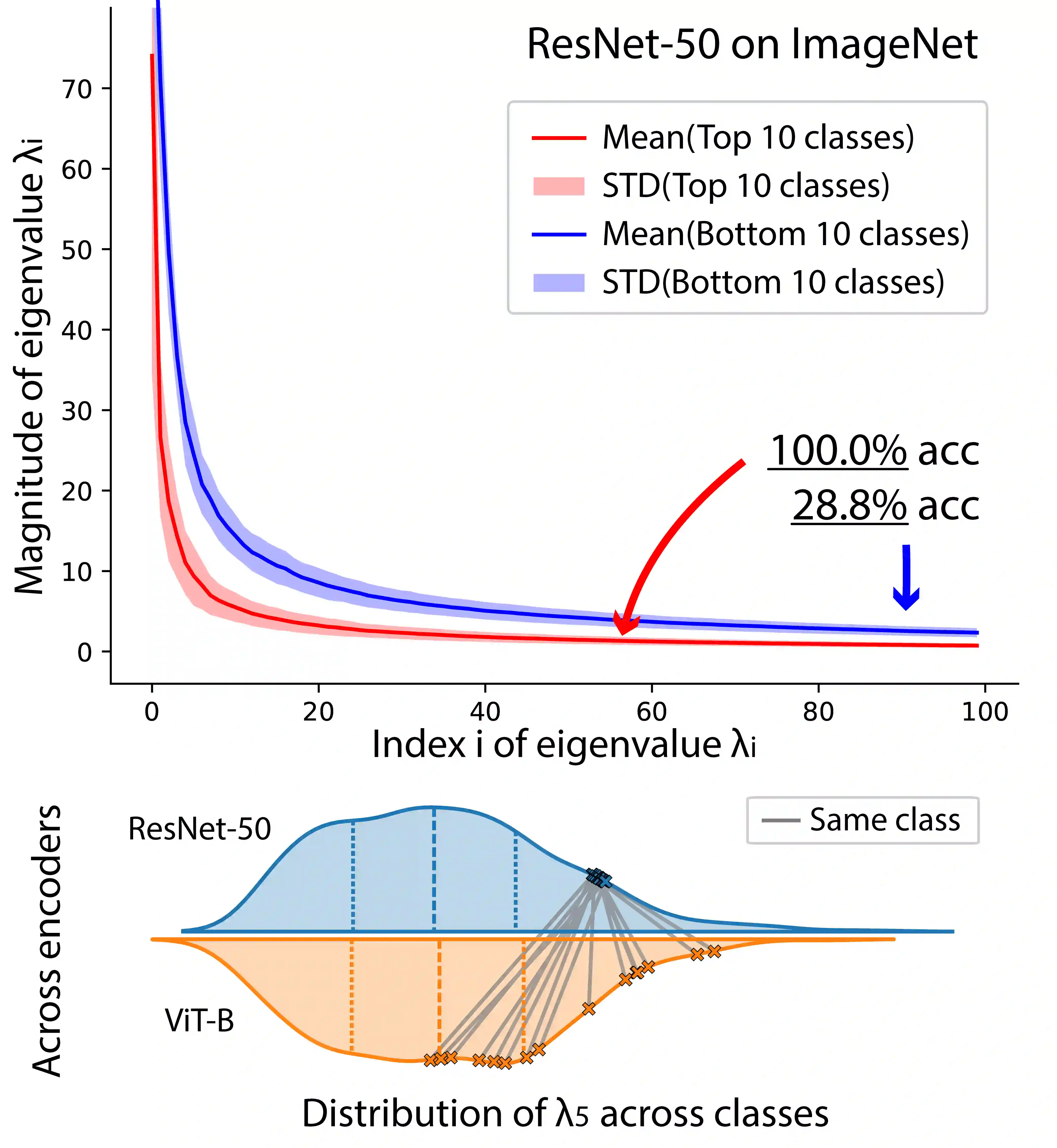
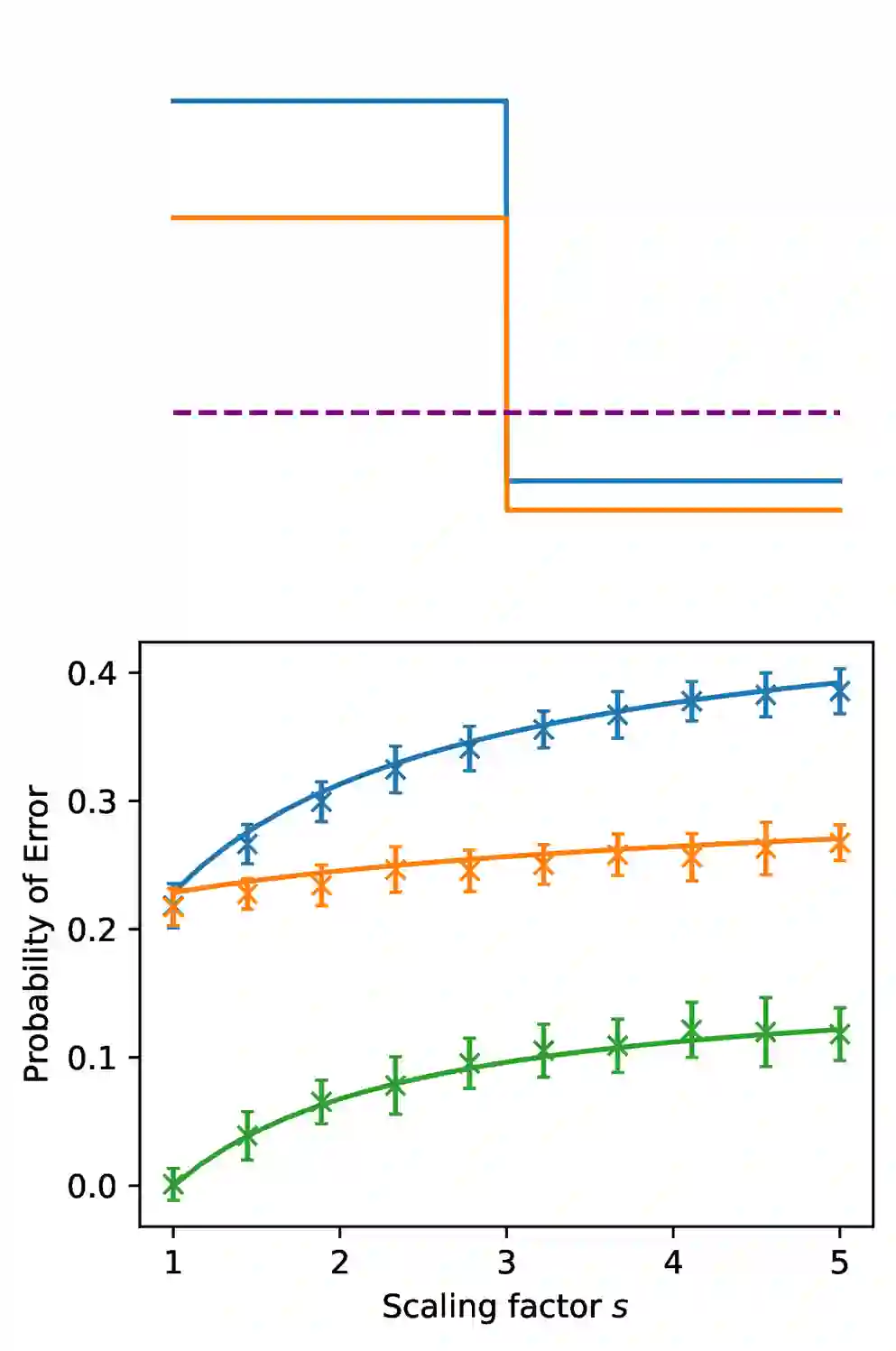
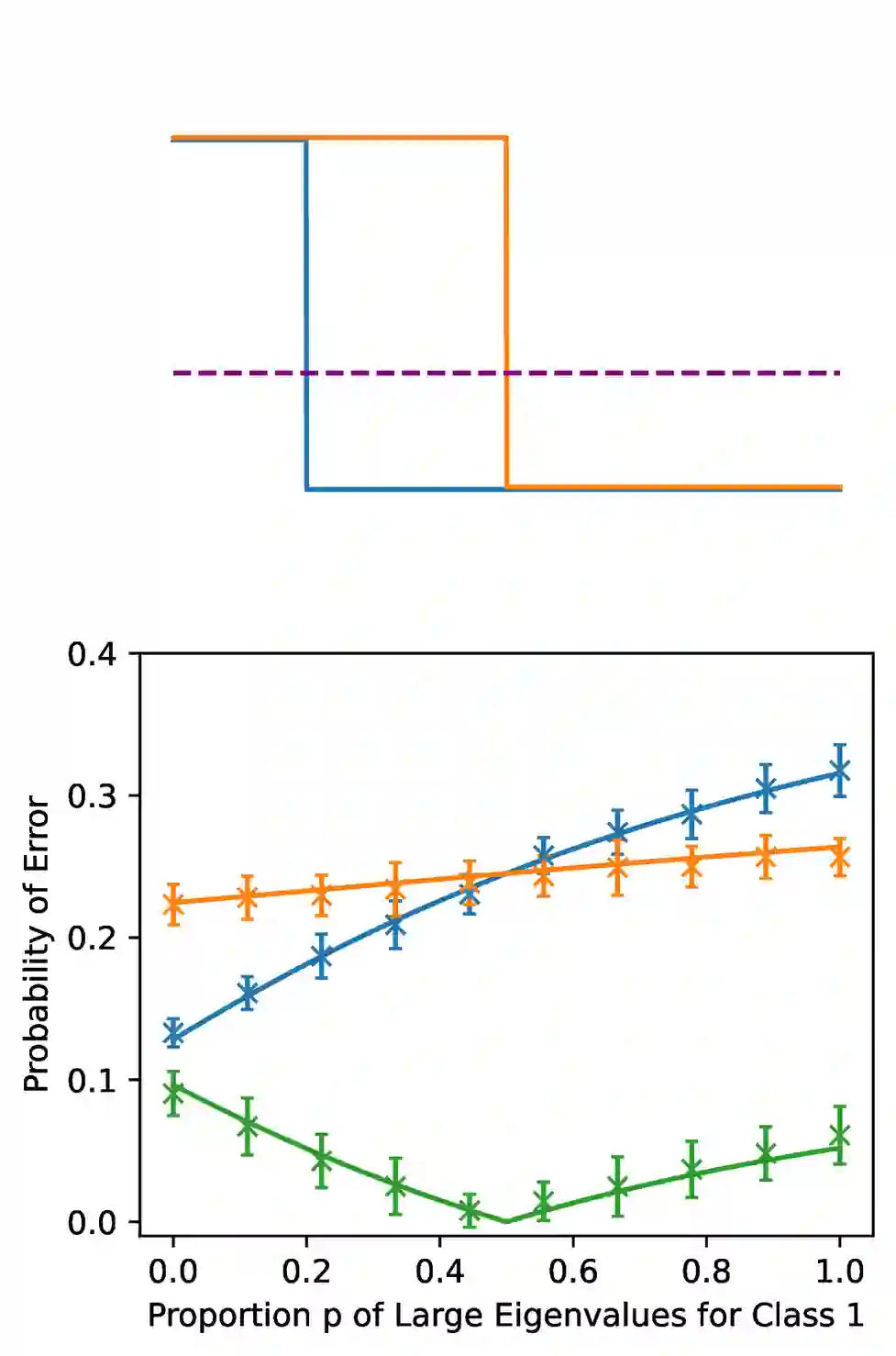
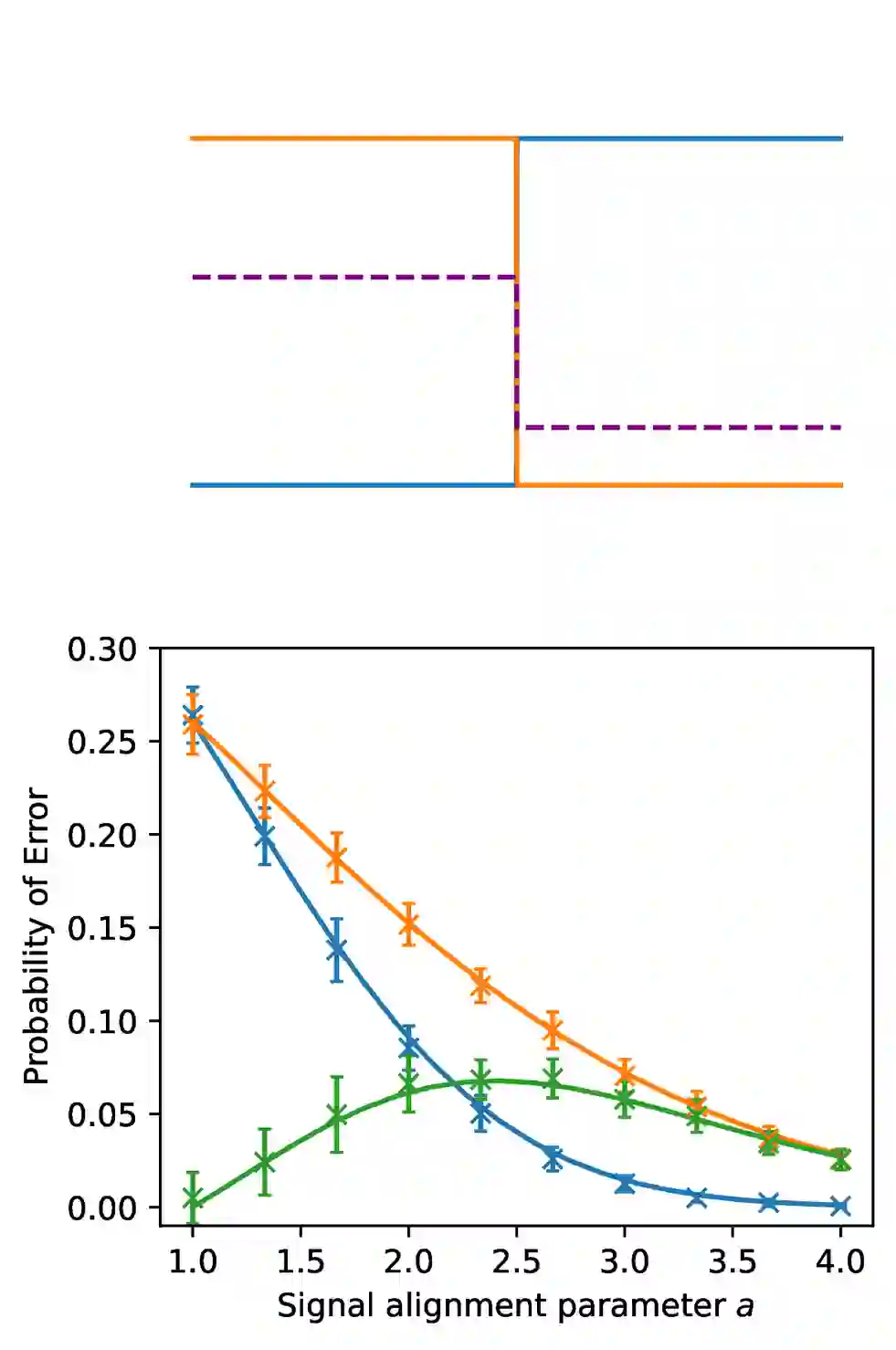
Classification models are expected to perform equally well for different classes, yet in practice, there are often large gaps in their performance. This issue of class bias is widely studied in cases of datasets with sample imbalance, but is relatively overlooked in balanced datasets. In this work, we introduce the concept of spectral imbalance in features as a potential source for class disparities and study the connections between spectral imbalance and class bias in both theory and practice. To build the connection between spectral imbalance and class gap, we develop a theoretical framework for studying class disparities and derive exact expressions for the per-class error in a high-dimensional mixture model setting. We then study this phenomenon in 11 different state-of-the-art pretrained encoders and show how our proposed framework can be used to compare the quality of encoders, as well as evaluate and combine data augmentation strategies to mitigate the issue. Our work sheds light on the class-dependent effects of learning, and provides new insights into how state-of-the-art pretrained features may have unknown biases that can be diagnosed through their spectra.
翻译:分类模型预期在不同类别上表现相当,然而实践中其性能常存在显著差距。类别偏差问题在样本不平衡数据集中已被广泛研究,但在平衡数据集中相对被忽视。本工作引入特征谱不平衡的概念作为类别差异的潜在来源,并从理论与实践两方面研究谱不平衡与类别偏差之间的关联。为建立谱不平衡与类别差距的联系,我们构建了研究类别差异的理论框架,并在高维混合模型设定中推导出逐类别误差的精确表达式。随后,我们在11种不同的最先进预训练编码器中研究此现象,并展示所提框架如何用于比较编码器质量、评估及组合数据增强策略以缓解该问题。本研究揭示了学习过程中的类别依赖性效应,为理解最先进预训练特征可能存在的、可通过其谱诊断的未知偏差提供了新视角。