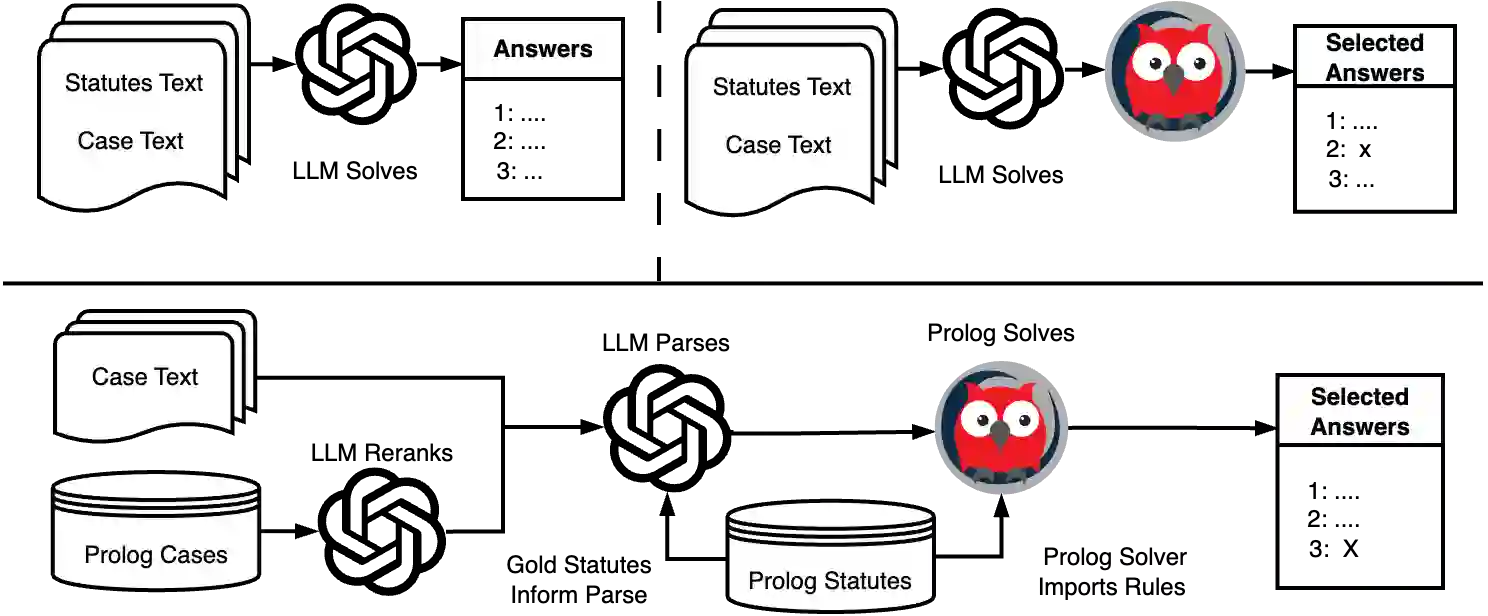
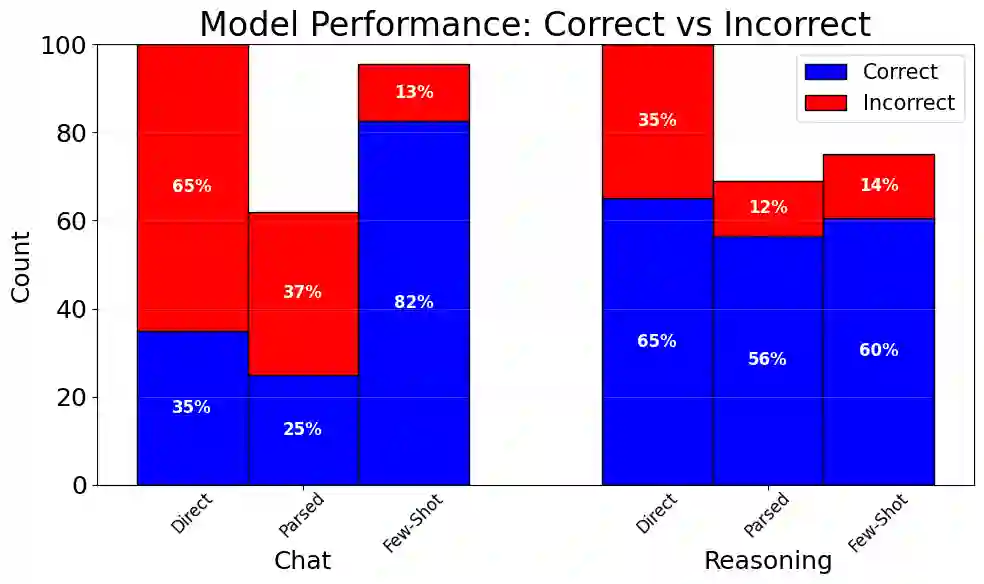
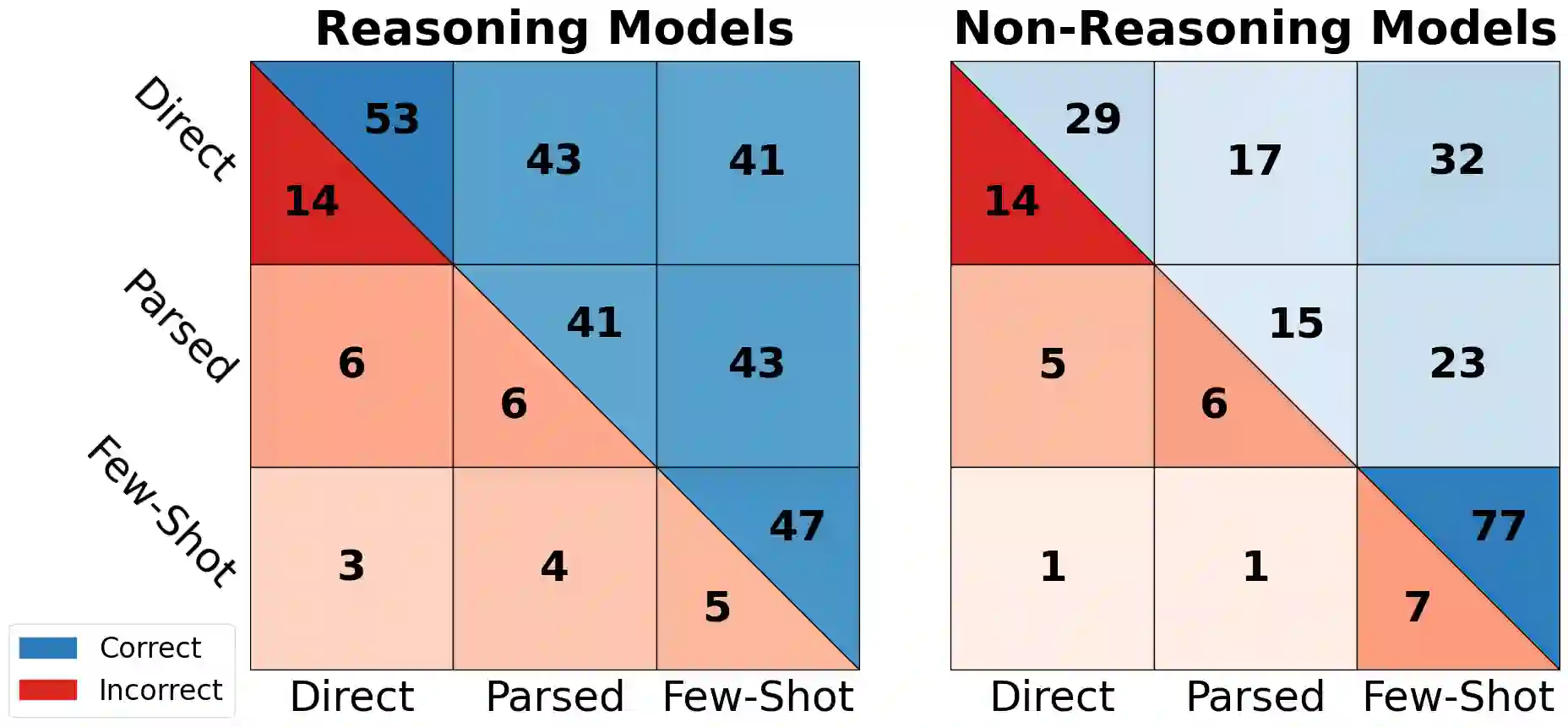
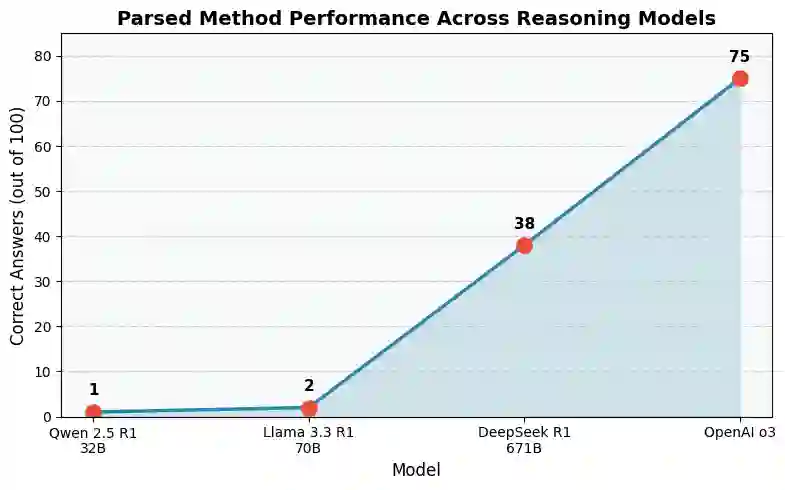
According to the United States Internal Revenue Service, ``the average American spends $\$270$ and 13 hours filing their taxes''. Even beyond the U.S., tax filing requires complex reasoning, combining application of overlapping rules with numerical calculations. Because errors can incur costly penalties, any automated system must deliver high accuracy and auditability, making modern large language models (LLMs) poorly suited for this task. We propose an approach that integrates LLMs with a symbolic solver to calculate tax obligations. We evaluate variants of this system on the challenging StAtutory Reasoning Assessment (SARA) dataset, and include a novel method for estimating the cost of deploying such a system based on real-world penalties for tax errors. We further show how combining up-front translation of plain-text rules into formal logic programs, combined with intelligently retrieved exemplars for formal case representations, can dramatically improve performance on this task and reduce costs to well below real-world averages. Our results demonstrate the effectiveness of applying semantic parsing methods to statutory reasoning, and show promising economic feasibility of neuro-symbolic architectures for increasing access to reliable tax assistance.
翻译:根据美国国税局的数据,“普通美国人花费270美元和13小时来申报税务”。即使在美国之外,税务申报也需要复杂的推理,涉及重叠规则的应用与数值计算的结合。由于错误可能导致高昂的罚款,任何自动化系统都必须提供高准确性和可审计性,这使得现代大型语言模型(LLMs)并不适合此任务。我们提出了一种将LLMs与符号求解器相结合来计算税务义务的方法。我们在具有挑战性的法定推理评估(SARA)数据集上评估了该系统的多个变体,并引入了一种基于实际税务错误处罚来估算部署此类系统成本的新方法。我们进一步展示了如何通过将明文规则预先转换为形式逻辑程序,并结合智能检索的形式化案例表示示例,可以显著提高此任务的性能,并将成本降低至远低于实际平均水平。我们的结果证明了将语义解析方法应用于法定推理的有效性,并展示了神经符号架构在提高可靠税务援助可及性方面具有前景的经济可行性。