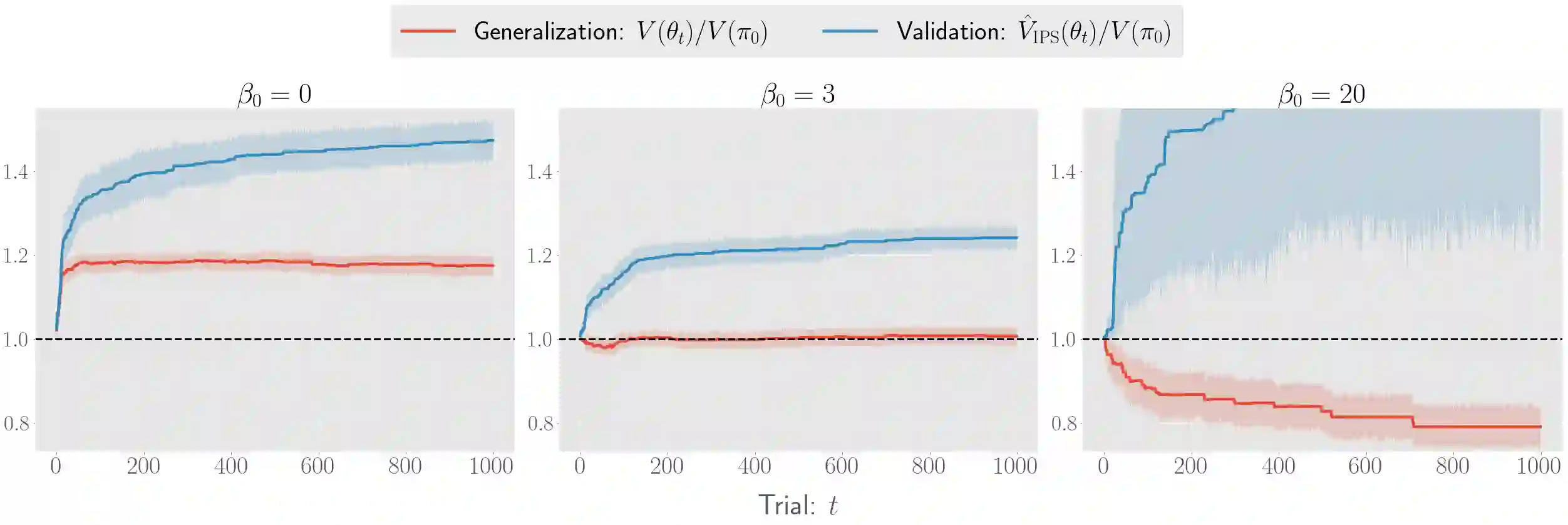
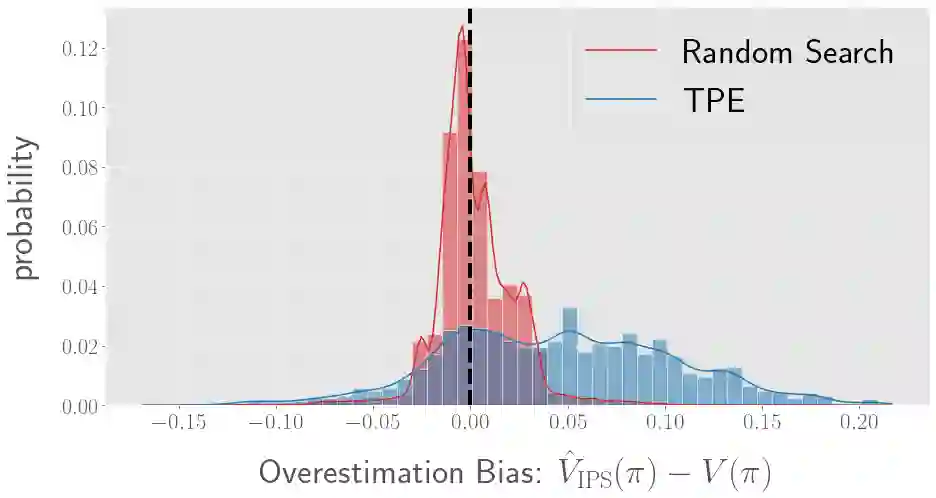
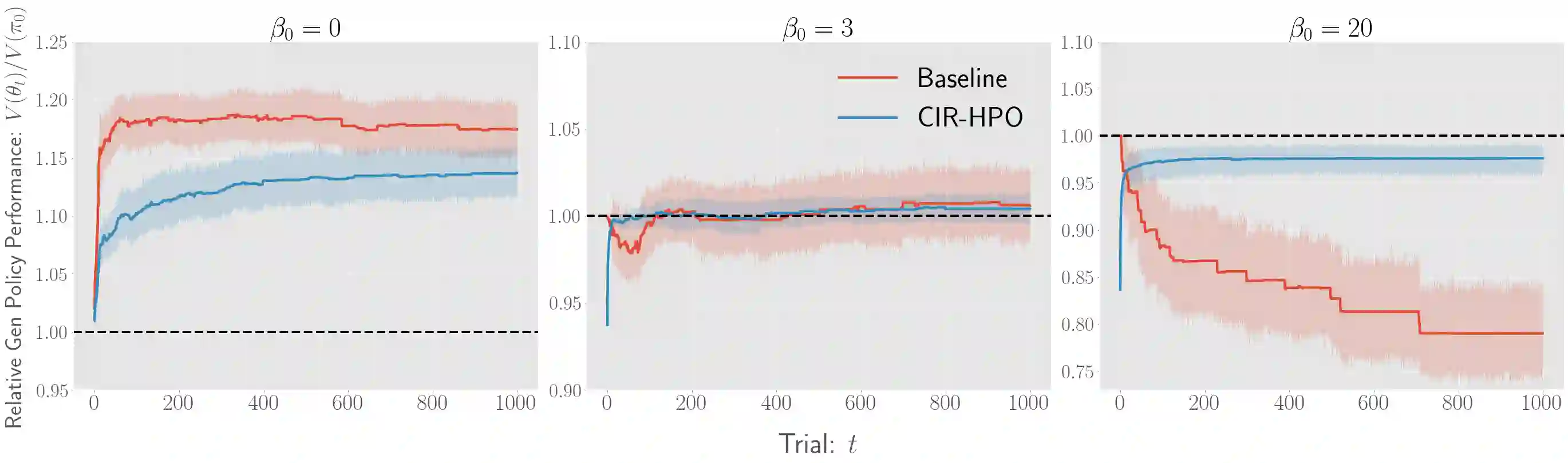
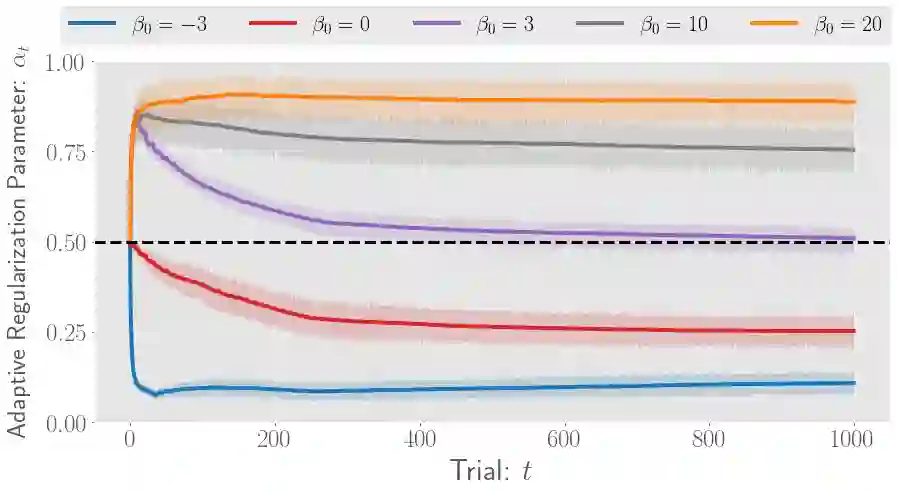
There has been a growing interest in off-policy evaluation in the literature such as recommender systems and personalized medicine. We have so far seen significant progress in developing estimators aimed at accurately estimating the effectiveness of counterfactual policies based on biased logged data. However, there are many cases where those estimators are used not only to evaluate the value of decision making policies but also to search for the best hyperparameters from a large candidate space. This work explores the latter hyperparameter optimization (HPO) task for off-policy learning. We empirically show that naively applying an unbiased estimator of the generalization performance as a surrogate objective in HPO can cause an unexpected failure, merely pursuing hyperparameters whose generalization performance is greatly overestimated. We then propose simple and computationally efficient corrections to the typical HPO procedure to deal with the aforementioned issues simultaneously. Empirical investigations demonstrate the effectiveness of our proposed HPO algorithm in situations where the typical procedure fails severely.
翻译:近年来,文献中对离线策略评估的兴趣日益增长,例如推荐系统和个性化医疗领域。我们在开发旨在基于有偏日志数据准确估计反事实策略有效性的估计器方面取得了显著进展。然而,在许多情况下,这些估计器不仅用于评估决策策略的价值,还用于从大规模候选空间中搜索最佳超参数。本文探讨了离线策略学习中的超参数优化(HPO)任务。我们通过实验表明,在HPO中简单地将泛化性能的无偏估计量作为代理目标可能导致意外失败,即仅追求那些泛化性能被严重高估的超参数。随后,我们提出了简单且计算高效的修正方案,以同时应对典型HPO过程中的上述问题。实验研究证明了我们提出的HPO算法在典型过程严重失效的情况下的有效性。