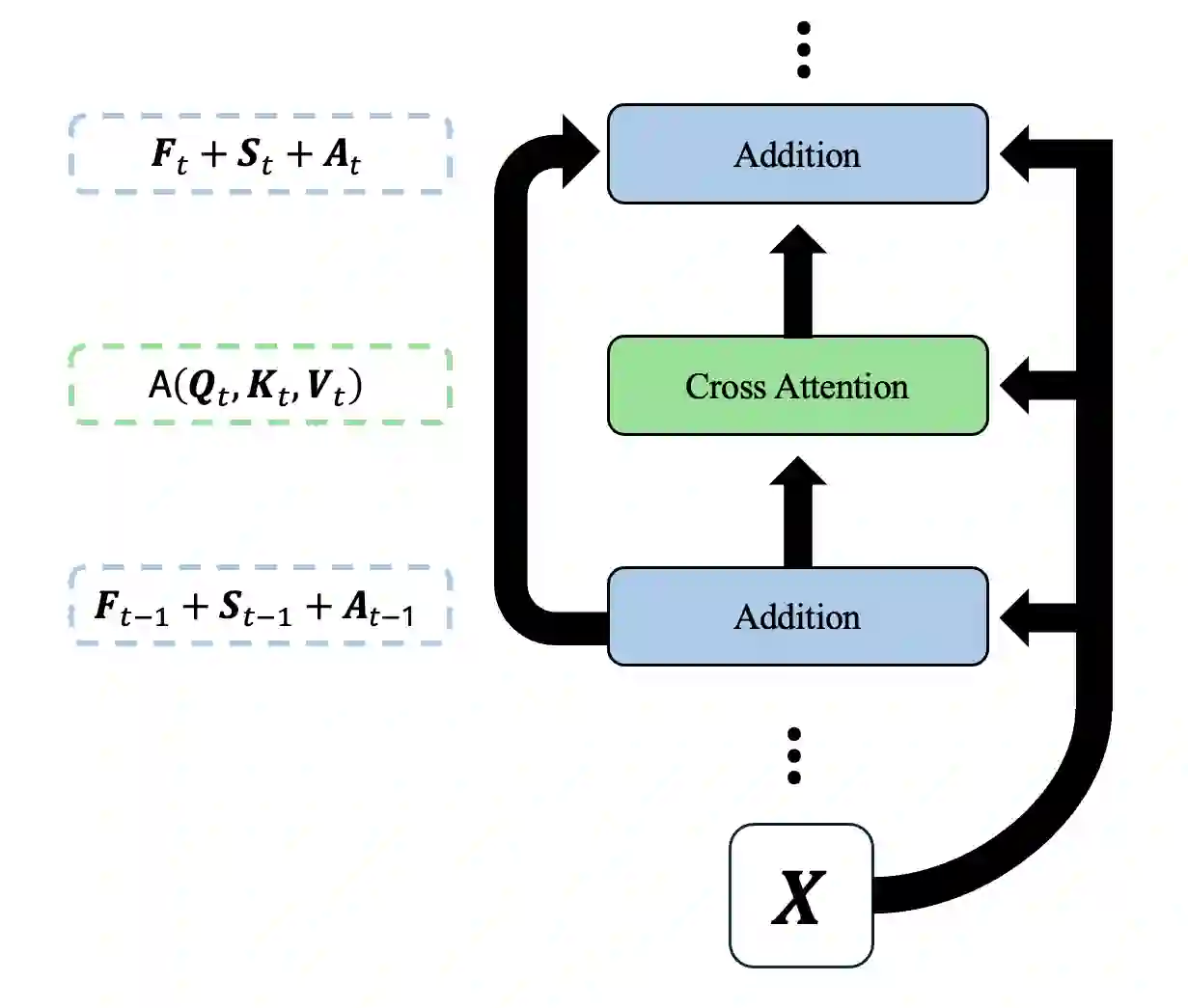
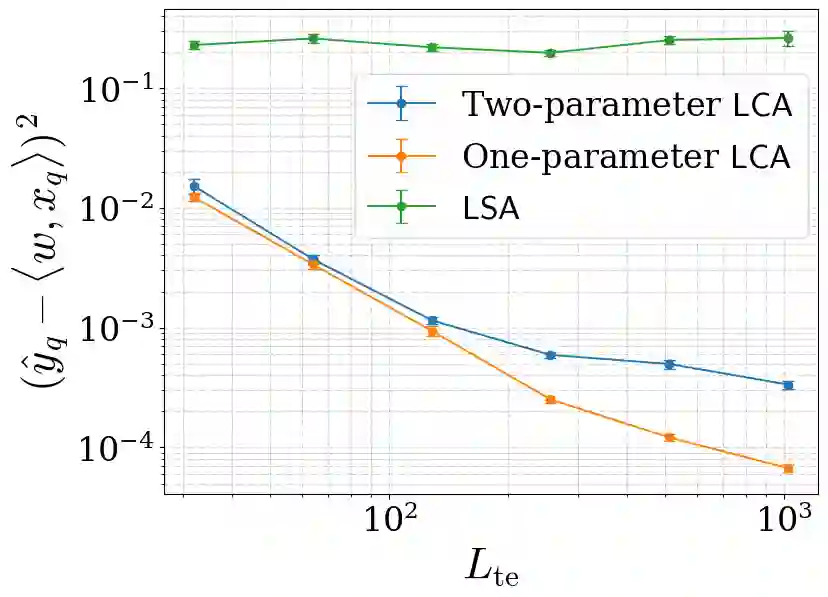
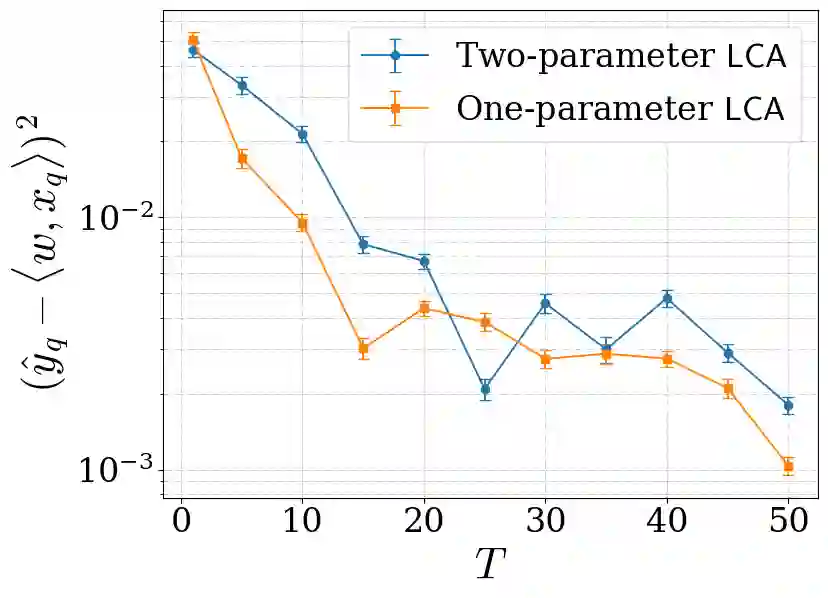
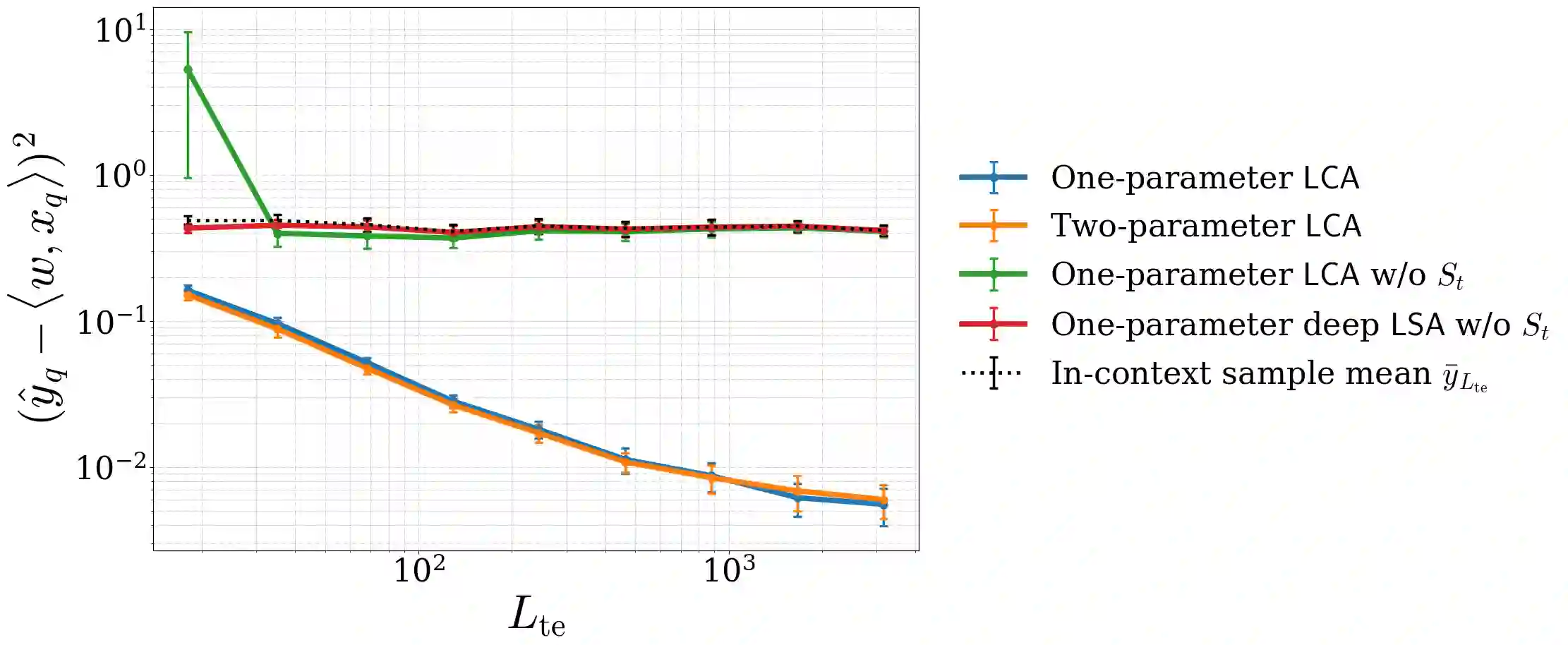
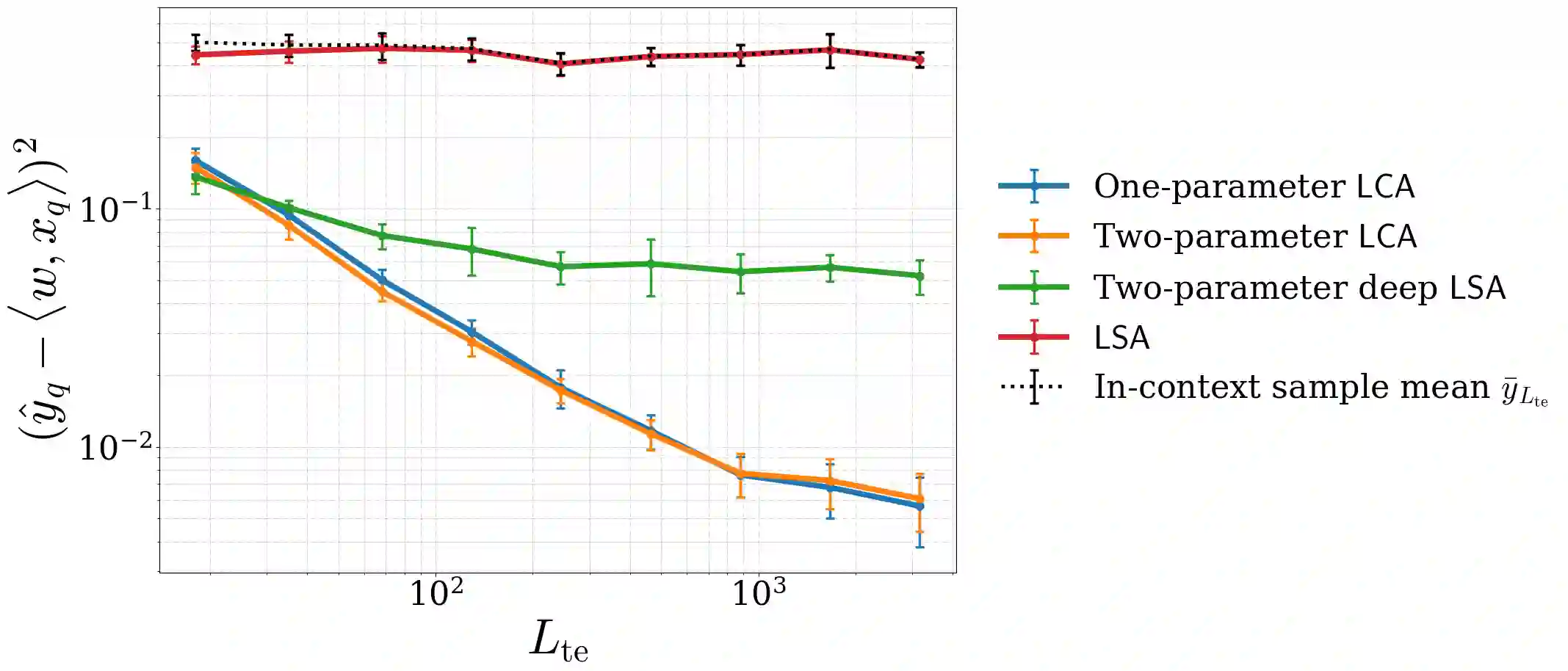
Recent progress has rapidly advanced our understanding of the mechanisms underlying in-context learning in modern attention-based neural networks. However, existing results focus exclusively on unimodal data; in contrast, the theoretical underpinnings of in-context learning for multi-modal data remain poorly understood. We introduce a mathematically tractable framework for studying multi-modal learning and explore when transformer-like architectures can recover Bayes-optimal performance in-context. To model multi-modal problems, we assume the observed data arises from a latent factor model. Our first result comprises a negative take on expressibility: we prove that single-layer, linear self-attention fails to recover the Bayes-optimal predictor uniformly over the task distribution. To address this limitation, we introduce a novel, linearized cross-attention mechanism, which we study in the regime where both the number of cross-attention layers and the context length are large. We show that this cross-attention mechanism is provably Bayes optimal when optimized using gradient flow. Our results underscore the benefits of depth for in-context learning and establish the provable utility of cross-attention for multi-modal distributions.
翻译:近期进展迅速增进了我们对现代基于注意力的神经网络中上下文学习机制的理解。然而,现有成果仅专注于单模态数据;相比之下,多模态数据上下文学习的理论基础仍然知之甚少。我们引入了一个数学上易于处理的框架来研究多模态学习,并探究类Transformer架构何时能够在上下文中恢复贝叶斯最优性能。为了对多模态问题进行建模,我们假设观测数据源自一个潜在因子模型。我们的第一个结果包含了对表达能力的负面看法:我们证明了单层线性自注意力无法在任务分布上一致地恢复贝叶斯最优预测器。为了解决这一局限,我们引入了一种新颖的线性化交叉注意力机制,并在交叉注意力层数和上下文长度都很大的机制下对其进行了研究。我们证明,当使用梯度流进行优化时,这种交叉注意力机制是贝叶斯最优的。我们的结果凸显了深度对于上下文学习的益处,并确立了交叉注意力对于多模态分布的可证明效用。