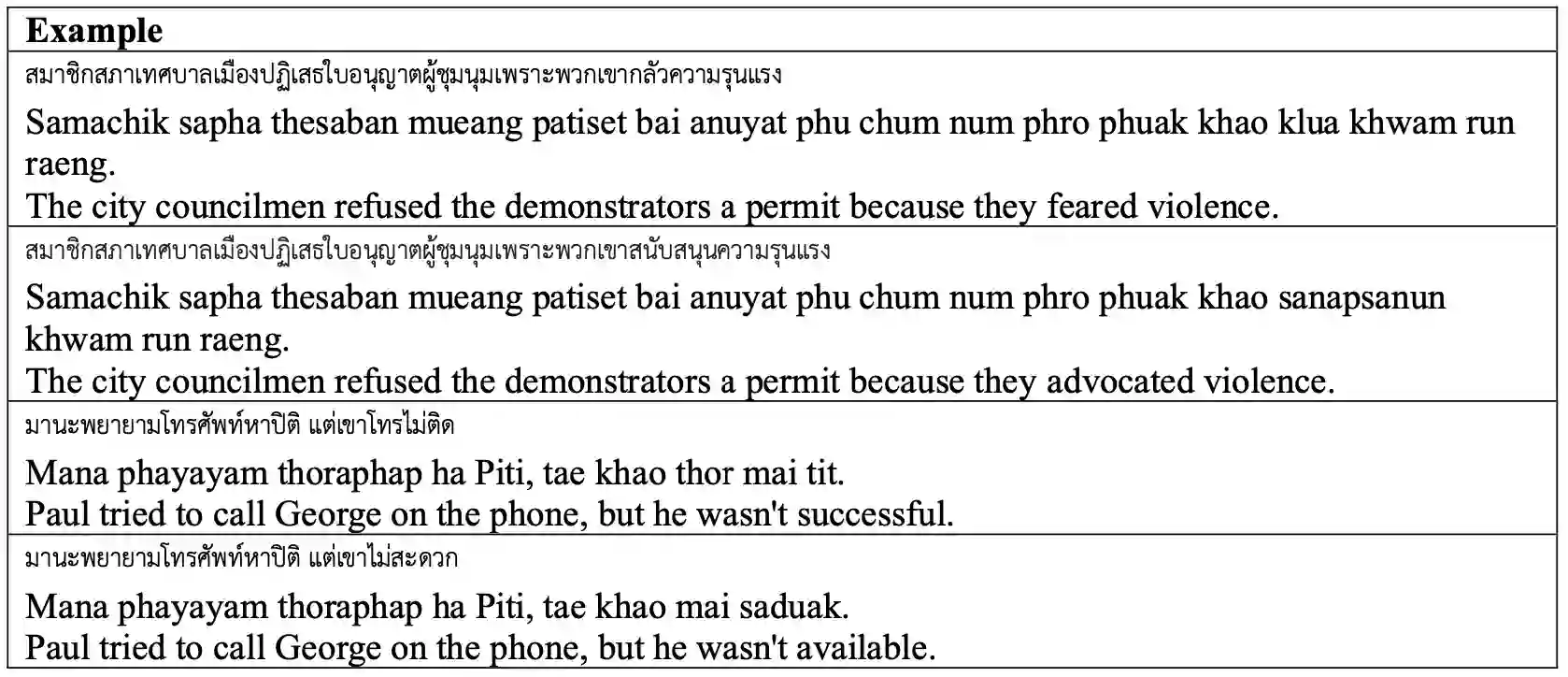
Commonsense reasoning is one of the important aspect of natural language understanding, with several benchmarks developed to evaluate it. However, only a few of these benchmarks are available in languages other than English. Developing parallel benchmarks facilitates cross-lingual evaluation, enabling a better understanding of different languages. This research introduces a collection of Winograd Schemas in Thai, a novel dataset designed to evaluate commonsense reasoning capabilities in the context of the Thai language. Through a methodology involving native speakers, professional translators, and thorough validation, the schemas aim to closely reflect Thai language nuances, idioms, and cultural references while maintaining ambiguity and commonsense challenges. We evaluate the performance of popular large language models on this benchmark, revealing their strengths, limitations, and providing insights into the current state-of-the-art. Results indicate that while models like GPT-4 and Claude-3-Opus achieve high accuracy in English, their performance significantly drops in Thai, highlighting the need for further advancements in multilingual commonsense reasoning.
翻译:常识推理是自然语言理解的重要方面之一,已有多个基准测试被开发用于评估该能力。然而,这些基准测试中仅有少数可用于英语以外的语言。开发平行基准测试有助于跨语言评估,从而促进对不同语言的深入理解。本研究引入了一套泰语Winograd模式集合,这是一个旨在评估泰语语境下常识推理能力的新型数据集。通过采用母语者参与、专业翻译和严格验证的方法论,这些模式力求在保持歧义性和常识挑战的同时,紧密反映泰语的语言细微差别、习语和文化参照。我们评估了当前流行的大型语言模型在此基准测试上的表现,揭示了它们的优势与局限,并为当前技术发展现状提供了见解。结果表明,尽管GPT-4和Claude-3-Opus等模型在英语测试中达到较高准确率,但它们在泰语测试中的表现显著下降,这凸显了多语言常识推理领域仍需进一步突破。