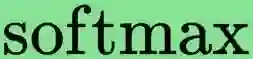Attention computation takes both the time complexity of $O(n^2)$ and the space complexity of $O(n^2)$ simultaneously, which makes deploying Large Language Models (LLMs) in streaming applications that involve long contexts requiring substantial computational resources. In recent OpenAI DevDay (Nov 6, 2023), OpenAI released a new model that is able to support a 128K-long document, in our paper, we focus on the memory-efficient issue when context length $n$ is much greater than 128K ($n \gg 2^d$). Considering a single-layer self-attention with Query, Key, and Value matrices $Q, K, V \in \mathbb{R}^{n \times d}$, the polynomial method approximates the attention output $T \in \mathbb{R}^{n \times d}$. It accomplishes this by constructing $U_1, U_2 \in \mathbb{R}^{n \times t}$ to expedite attention ${\sf Attn}(Q, K, V)$ computation within $n^{1+o(1)}$ time executions. Despite this, computing the approximated attention matrix $U_1U_2^\top \in \mathbb{R}^{n \times n}$ still necessitates $O(n^2)$ space, leading to significant memory usage. In response to these challenges, we introduce a new algorithm that only reads one pass of the data in a streaming fashion. This method employs sublinear space $o(n)$ to store three sketch matrices, alleviating the need for exact $K, V$ storage. Notably, our algorithm exhibits exceptional memory-efficient performance with super-long tokens. As the token length $n$ increases, our error guarantee diminishes while the memory usage remains nearly constant. This unique attribute underscores the potential of our technique in efficiently handling LLMs in streaming applications.
翻译:注意力计算同时具有$O(n^2)$的时间复杂度和$O(n^2)$的空间复杂度,这使得在涉及长上下文的流式应用中部署大语言模型(LLMs)需要大量计算资源。在最近的OpenAI DevDay(2023年11月6日)上,OpenAI发布了一个支持128K长文档的新模型。本文聚焦于当上下文长度$n$远大于128K($n \gg 2^d$)时的内存高效问题。考虑单层自注意力机制,其中查询(Query)、键(Key)和值(Value)矩阵$Q, K, V \in \mathbb{R}^{n \times d}$,多项式方法通过构造$U_1, U_2 \in \mathbb{R}^{n \times t}$,在$n^{1+o(1)}$时间执行内加速注意力${\sf Attn}(Q, K, V)$计算,从而近似注意力输出$T \in \mathbb{R}^{n \times d}$。尽管如此,计算近似注意力矩阵$U_1U_2^\top \in \mathbb{R}^{n \times n}$仍需要$O(n^2)$空间,导致显著内存消耗。针对这些挑战,我们提出一种新算法,仅以流式方式读取数据一遍。该方法使用亚线性空间$o(n)$存储三个草图矩阵,免除了精确存储$K, V$的需求。值得注意的是,我们的算法在处理超长令牌时表现出卓越的内存高效性能。随着令牌长度$n$增加,误差保证逐渐减小,而内存使用几乎保持恒定。这一独特属性凸显了我们的技术在处理流式应用中大语言模型方面的潜力。